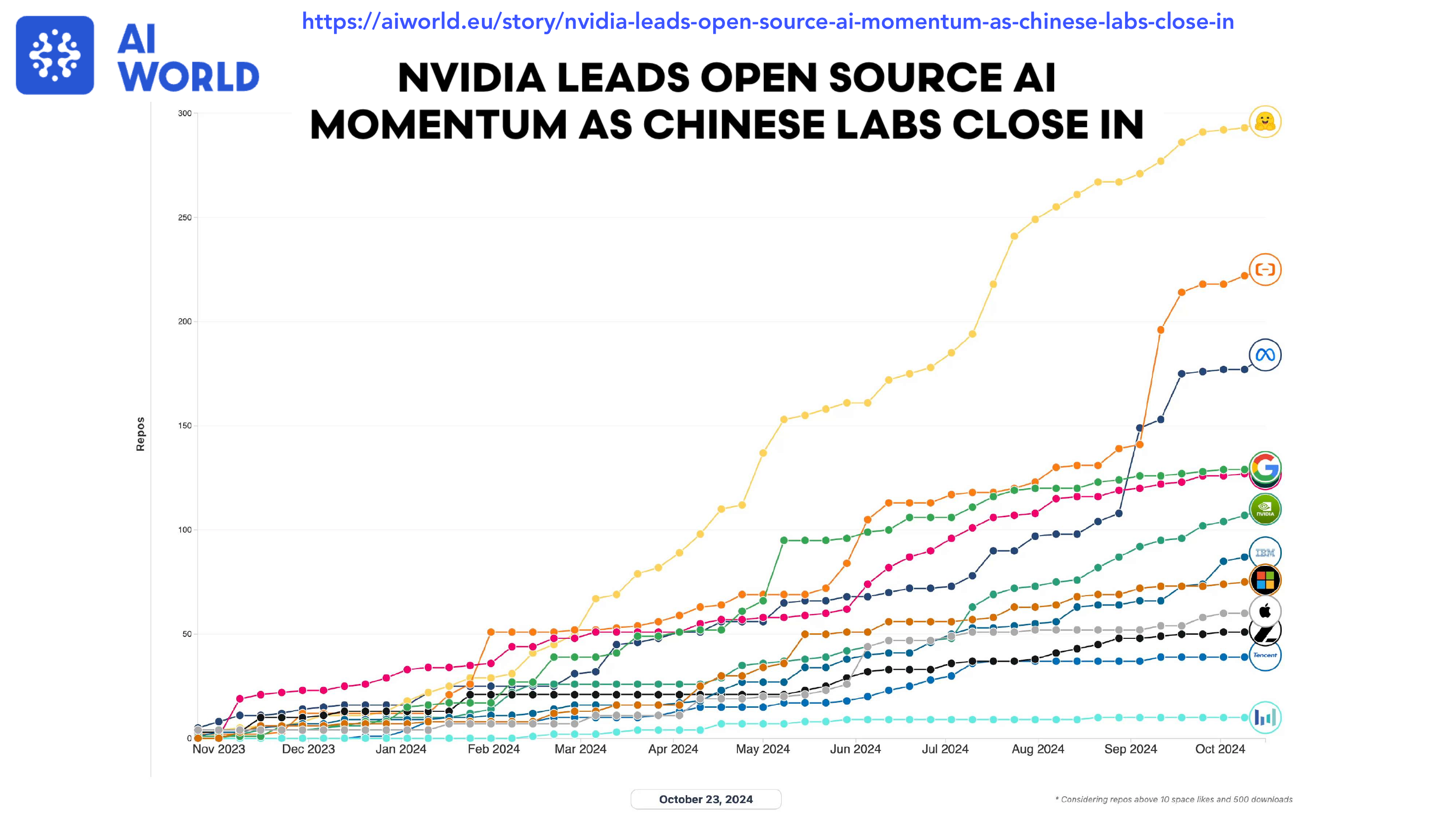
00引言:David vs Goliath 时代的小模型推理
0.1 一段"不可能任务"的史诗
2023 年 5 月,Sam Altman 在伦敦一场讲座中抛下一句让整个开源社区心头一凉的话:"It's totally hopeless to compete with us on training foundation models." 那一年,GPT-4 像一座不可逾越的高山笼罩在所有研究者头顶;千亿参数、数万张 H100、数十亿美元的训练成本,似乎注定让"造大模型"成为少数寡头的游戏。
然而仅仅一年之后,棋盘悄然翻转。NVIDIA 的 Nemotron 系列、阿里巴巴的 Qwen、深度求索的 DeepSeek-R1 接连出现,把"开源 + 小模型 + 强推理"的故事讲到了世界舞台中央。一支来自中国实验室与北美开源社区联手的"反卷"力量,用截然不同的路径——Unconventional Data 🔥 + Unconventional Algorithms 🚀 + Unconventional Collaboration 🌍——撕开了闭源巨头看似密不透风的护城河。
📌 关键洞察
David 没有变成 Goliath。David 学会了用石头甩出抛物线。
0.2 化石燃料即将耗尽
2024 年 NeurIPS 上,Ilya Sutskever 用一句话给整个领域定性:"Pre-training as we know it will end." 他打了一个让所有人沉默的比喻——互联网数据是 AI 的化石燃料。煤炭终有烧尽的一天,而我们已经接近油井底部。
- Learn better & faster with limited data —— 在有限数据下用更聪明的架构与训练配方 (alternative architectures / training recipes)。
- Synthesize new data —— 凭空合成新数据,生成 "the outer space of the internet data"。
- Reason beyond what is in the data —— Test-time reasoning + Test-time training,让推理超越训练分布。
本教材接下来九章,正是把这三条路径走通的工程与科学。
0.3 三个"非常规"创新维度
讲座的主线可以归结为三个关键词,每一个都贯穿全书:
| 维度 | 关键词 | 主要章节 |
|---|---|---|
| Unconventional Data 🔥 | gradient diversity · front-loading · self-distillation flywheel | Ch.4 Prismatic Synthesis · Ch.6 FLR · Ch.7 OpenThoughts |
| Unconventional Algorithms 🚀 | DAPO clip-higher · ProRL endurance · RLP-as-pretraining | Ch.2 ProRL · Ch.5 RLP |
| Unconventional Collaboration 🌍 | 50+ 作者 · 跨 16 机构 · 跨国开源 | Ch.7 OpenThoughts · Ch.9 实践建议 |
💡 对学生的启示
你不需要 10 万张 H100 才能做前沿研究。但你必须看清——大厂在卷的是 sprint(短跑),而留给你的赛道是 endurance(耐力赛)。
01从 LLM 到 LRM:推理模型的范式转变 (2025)
1.1 LRM 的三个定义性特征
一个模型若要被称为 LRM (Large Reasoning Model),需要同时具备三个特征:
- Long thought (chain-of-thought):在回答前先输出一段(往往数千 token)的"内心独白";
- Trained with RL:核心训练信号来自 RL,典型是 RLVR (Reinforcement Learning with Verifiable Rewards);
- Exploration learning:模型不再只是模仿 demonstration,而是被允许在策略空间中自主探索。
这是一种 Imitation Learning → Exploration Learning 的根本范式转变。
1.2 HLE Benchmark:群雄并起
在更具挑战性的 HLE (Humanity's Last Exam) 上,2025 年的成绩单大致如下(数据来自 Artificial Analysis 独立评测):
| 模型 | HLE Pass Rate | 类型 |
|---|---|---|
| Gemini 2.5 Pro | 21.1% | 闭源 LRM |
| OpenAI o3 | 20.0% | 闭源 LRM |
| o4-mini (high) | 17.5% | 闭源 LRM |
| DeepSeek R1 (May '25) | 14.9% | 开源 LRM |
| Claude 4 Opus Thinking | 11.7% | 闭源 LRM |
| Qwen3-235B Reasoning | 11.7% | 开源 LRM |
| Gemini 2.5 Flash Reasoning | 11.1% | 闭源 LRM |
| Llama Nemotron Ultra Reasoning | 8.1% | 开源 LRM |
| GPT-4o (Nov '24) | 3.3% | 纯 LLM (无 thinking) |
关键趋势:带 reasoning 的模型显著高于纯 LLM;闭源与开源同台竞技,且开源差距正在迅速缩短。
1.3 五篇"反直觉"论文
在 LRM 浪潮中,下面五篇论文堪称"颠覆教科书"的里程碑,每一篇都值得反复研读。
核心结论:SFT 在 math 上涨分,但在其他任务上倒退;而 RL 跨域泛化。在 Qwen3-14B 上做受控实验,"教练亲手喂答案"反而会窄化模型,"放手让模型自己探索"才是通才之道。Latent representation 与 token 分布漂移分析显示 SFT 引起 substantial representation drift,RL 则保留 general-domain structure。
核心结论:一句更尖锐的标题——SFT 在做记忆,RL 在做泛化。与 Paper 1 形成相互呼应的双重证据。
核心结论:一个让全场倒吸冷气的发现:RLVR 之后 Pass@1 上涨,但 Pass@K(K 较大)反而下降。也就是说,RL 把模型"窄化"到了 base model 已经会的解法上——它在剪枝,而非真正长出新能力。
令人哭笑不得的实验:在 Qwen2.5-Math-7B 上训练 150 步:
- Random rewards (随机奖励):MATH-500 +21.4%
- Incorrect rewards (用错误标签作 ground truth):+24.6%
- Format reward (仅检查格式):+16.4%
- Ground truth reward (正确标签):+28.8%
三者差距非常小!但关键:同样的方法在 Llama3.1-8B-Instruct 和 OLMo2-7B 上完全失败,甚至倒退。这暗示 RL 信号本身不是推理的源头——base model 的 chemistry 才是。
核心结论:把上面四篇缝合到一起的结论——RL 后训练其实是在放大预训练阶段已有的行为分布。RL 像一个回音壁——你预训练教过什么,它就在那里反复回荡。
1.4 Karpathy 的怀疑与 Choi 的反驳
Andrej Karpathy 曾公开吐槽:
⚠️ Karpathy 的吐槽
"Reinforcement Learning is terrible. It just happens to be that everything else is much worse."
Yejin Choi 在 CS224N 给出了一个更精细的反驳框架:
Chemistry between the base LLM and RL matters.
Conclusions from effortless RL ≠ effortful RL.
"Spurious rewards 实验"之所以让人怀疑 RL,是因为它代表了 effortless 的实验——同样的算法在不同 base 上结果天差地别,必须用 effortful 的实验(系统调 entropy、reset reference policy、跨 base 对比)才能得到可信结论。这正是下一章 ProRL 要讲的故事。
💡 对学生的启示
不要轻信任何一个"RL 涨点"的论文标题。先问:base model 是谁?reward 是不是 spurious?Pass@K 还守得住吗?
02ProRL:把 RL 训练拉长 (NeurIPS 2025)
2.1 罗马不是一天建成的
如果 RL 在小模型上"看不出效果",是不是因为我们训练得不够久?这就是 ProRL 给出的直觉假说:
PRORL 核心假说
What if we go for endurance with a small model (1.5B) rather than a sprint with a large model?
2.2 基础算法:从 GRPO 到 DAPO
GRPO (Group Relative Policy Optimization) 由 DeepSeek 提出,核心损失函数(简化版)为:
其中 $r_\theta(\tau) = \pi_\theta(\tau)/\pi_{\theta_\text{old}}(\tau)$ 是重要性采样比,$A(\tau)$ 是组内归一化优势——用同一 query 下 $G$ 个 rollout 的奖励均值方差归一化,省掉了 critic 网络。这是 GRPO 相对 PPO 最关键的简化。
ByteDance 提出的 DAPO (Decoupled Clipping & Dynamic Sampling Policy Optimization) 在 GRPO 之上做了两个关键改造,是 ProRL 的算法基础:
把对称的 $1\pm\epsilon$ 拆成不对称的上下界——典型设置 $\epsilon_{\text{low}}=0.2, \epsilon_{\text{high}}=0.3$。让上界更宽,鼓励"低概率但高回报"的 token 不被裁掉,维持探索。
- Dynamic Sampling:实时过滤掉"全对"或"全错"的 group(advantage 全为 0 的无效梯度),把算力集中到中等难度样本上。
2.3 三大教训:如何让 RL 跑 2500 步而不崩
Lesson I
可持续 entropy 是生命线。通过 clip-higher 动态拉高 $\epsilon_{\text{high}}$,把策略熵稳在 ~1 附近,平衡 exploration / exploitation。
Lesson II
默认 $\epsilon_{\text{low}}=\epsilon_{\text{high}}=0.2$ 会导致 entropy collapse,模型再也"想不出新解法",训练实质死亡。
Lesson III
动态调 $\epsilon_{\text{high}}$;KL 高时 reset reference policy;训练分 8 段接力跑,"keep one hero run alive"。
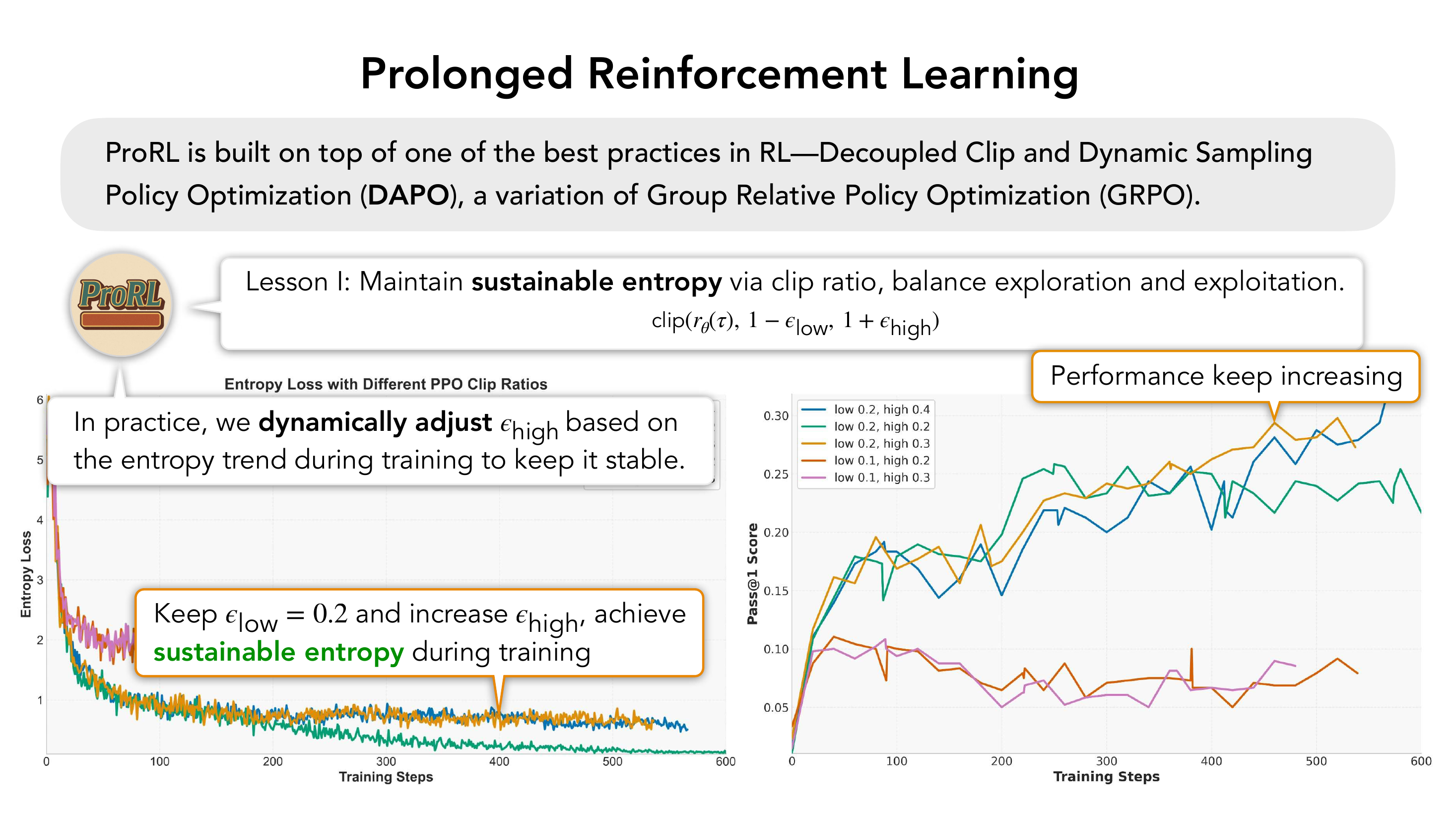
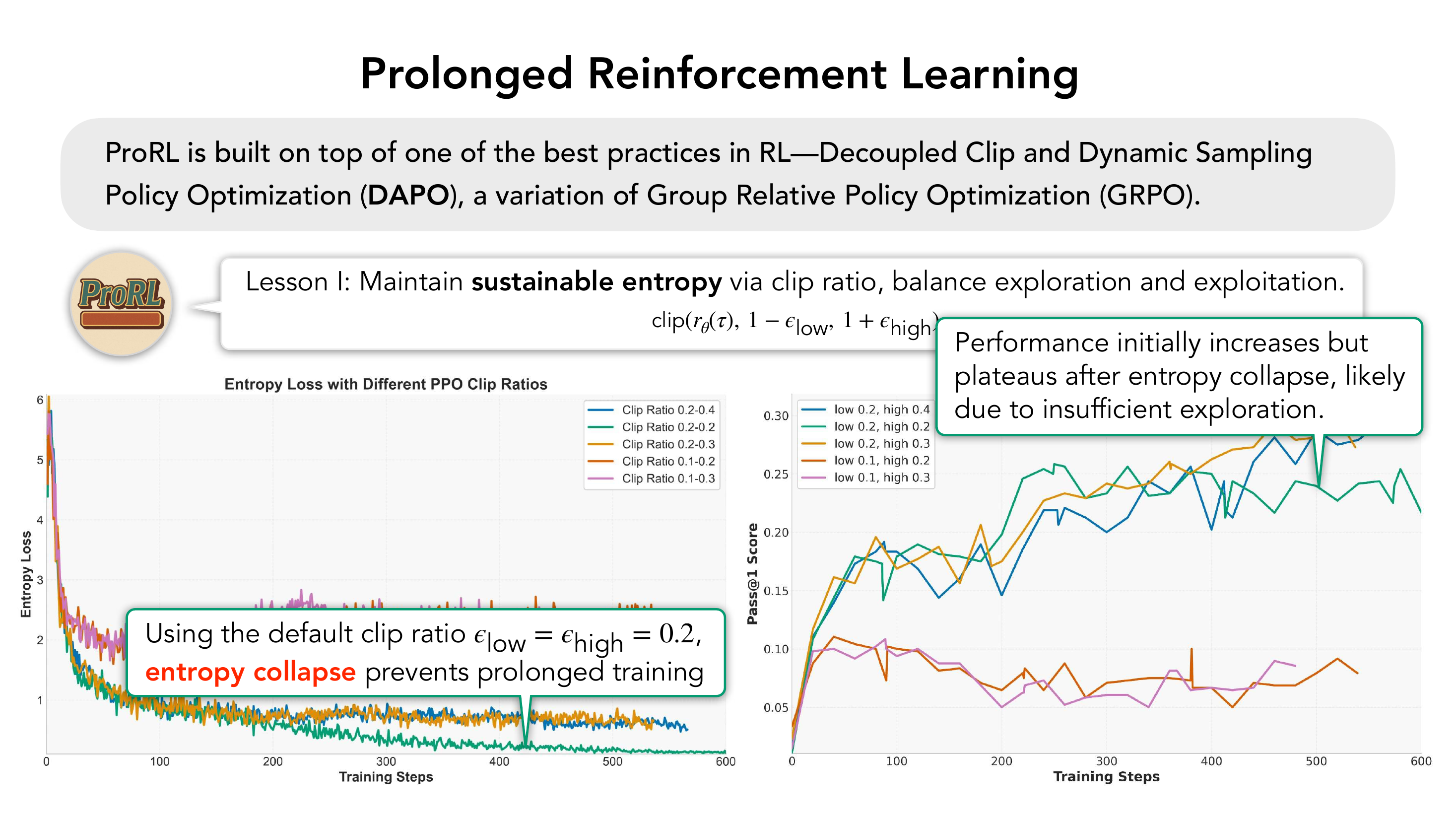
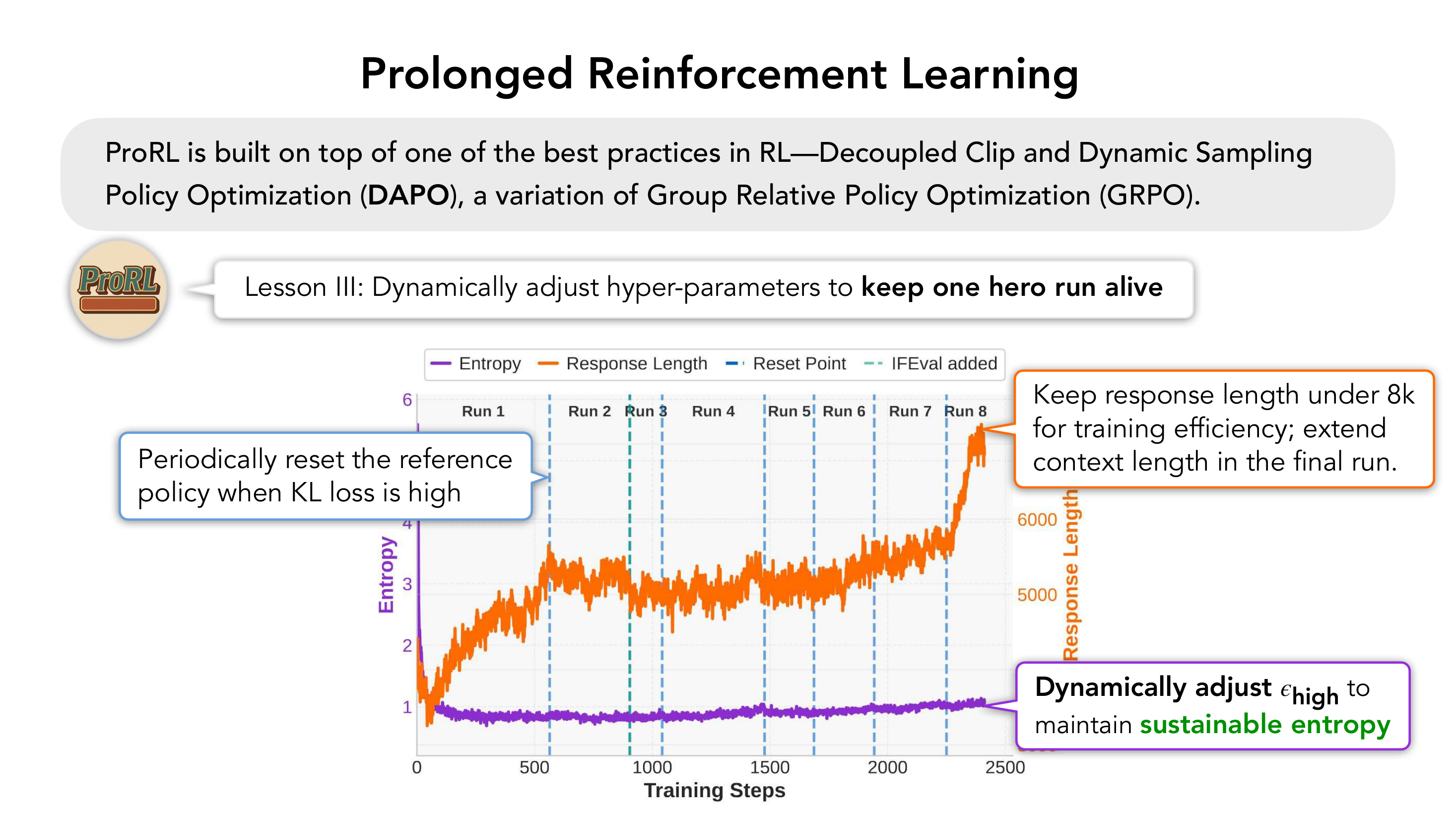
2.4 训练曲线与结果
ProRL 训练曲线呈现三条同步上扬的指标:
- Entropy 稳定保持在 ~1,没有坍缩;
- Response length 从约 4500 token 缓慢增长到 6500+ token——模型在"自发地想得更久";
- Total steps 突破 2500,远超此前公开报道的 RL 训练长度。
最终训练出的 Nemotron-Research-Reasoning-Qwen-1.5B 在 math / code / STEM / reasoning gym / instruction-following 五大类基准上全面超越 base R1-Distill-Qwen-1.5B,并在多项任务上达到 DeepSeek-R1-Distill-Qwen-7B 的 4.5× 性能。
| Benchmark | Base R1-1.5B | Nemotron-Reasoning-1.5B (ProRL) | 提升 |
|---|---|---|---|
| AIME24 | 28.5 | 48.1 | +19.6 (+68.6%) |
| AMC | 62.6 | 79.3 | +16.7 (+26.7%) |
| MATH | 82.9 | 91.9 | +9.0 (+10.8%) |
| Apps (coding) | 21.0 | 42.0 | +21.0 (+100.4%) |
| Codeforces | 14.1 | 34.5 | +20.4 (+144.2%) |
| IF Eval | 44.0 | 66.0 | +22.0 (+49.9%) |
| Reasoning Gym (algebra) | 0.7 | 97.2 | +96.5 (+13216%) |
🔥 关键洞察
Pass@1 与 Pass@16 同时呈 log-linear 提升——一举绕过了 Yue et al. (2025) 警告的"Pass@K 倒退"陷阱。这是判断 RL 是"真泛化"还是"窄化记忆"的金标准。
2.5 后续工作:BroRL
ProRL 之后,同一团队 (Jian Hu, Mingjie Liu, Ximing Lu, Fang Wu, Zaid Harchaoui, Shizhe Diao, Yejin Choi, Pavlo Molchanov, Jun Yang, Jan Kautz, Yi Dong) 又发表了 BroRL: Scaling Reinforcement Learning via Broadened Exploration,把"探索宽度"作为另一个 scaling 维度——这是 ProRL endurance 思想的自然延伸。
开放问题:Effortful RL 能否在更弱的 base (如 GPT-2) 上成功?这是 Choi 在讲座中留下的"勇士问号"。
💡 对学生的启示
不用大模型也能做 SOTA reasoning 研究——但你必须懂 entropy 控制,必须接受"训练 2500 步、调 8 个 run、reset reference policy"这种"工程不性感、科学很扎实"的工作方式。
03合成数据:Mode Collapse 与生成式数据的悖论
3.1 Curse of Recursion
当模型反复用自己生成的数据训练自己时,分布尾部会被快速削平,最终导致 mode collapse。这就像复印件的复印件——每一代都更模糊。Stable Diffusion 与 GPT-4 的递归实验都验证了这个现象。
3.2 业界的"省事"做法
工业界的主流应对策略简单粗暴:用最大的 teacher 蒸馏。OpenAI 用自己最强的模型生成数据训练下一代;Anthropic、DeepSeek-R1、Qwen3、Microsoft Phi-4 都走同一条路。直觉上很有道理——teacher 越强,distill 出的 student 越强。
但 Yejin Choi 提出了一个尖锐的反问:
Effortless 合成数据 ≠ Effortful 合成数据。
如果"用最大教师 + 多采几次"就能解决所有问题,为什么开源社区还训不出 GPT-4?
答案是:单一强大 teacher 会带来强大的 mode collapse。教师再聪明,也只会用它自己最熟悉的几条解法路径。学生学到的,是教师习惯的窄化版本——它继承了 teacher 的盲点。
3.3 一个反直觉的猜想
那么——能不能反其道而行之:用更小的 teacher,但显式地最大化多样性?
这就引出了下一章 Prismatic Synthesis 的核心创新。
💡 对学生的启示
当你想"我们也来 distill 一下 R1 吧"时,先问自己——你打算如何度量多样性?如果答案是"温度调高一点",那你已经在走 effortless 的死胡同。
04Prismatic Synthesis:用梯度做数据多样性 (NeurIPS 2025)
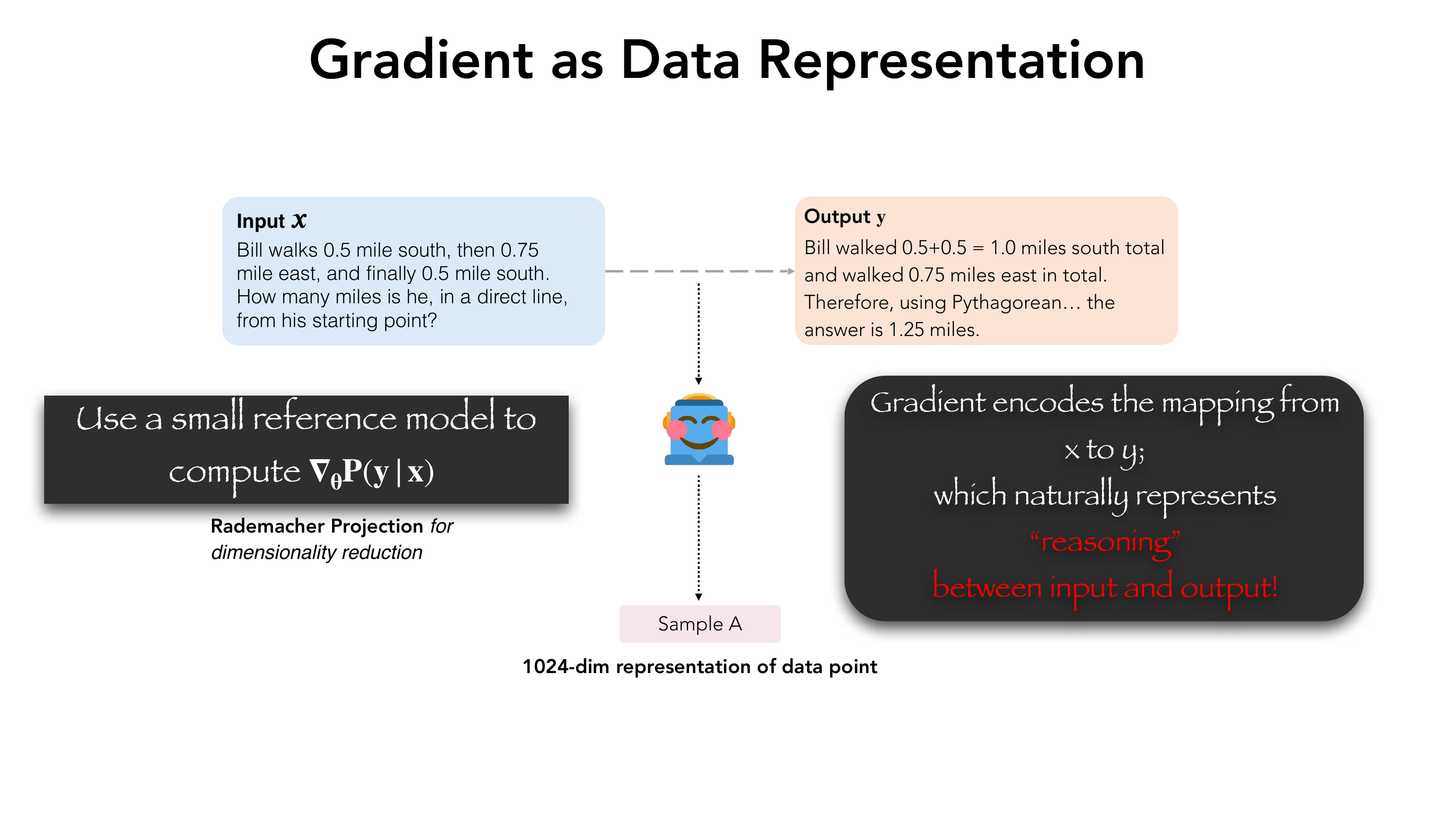
4.1 核心创新:Gradient as Data Representation
对于一个 (question, answer) 对 $(x, y)$,梯度
$$\nabla_\theta \log P_\theta(y \mid x)$$编码了"如果要让模型学会从 $x$ 推到 $y$,需要对哪些参数做出多大的调整"。换言之,梯度向量天然地刻画了这条推理路径在参数空间中的"方向"。
- 两个看上去字面不同但本质同义的推理样本,梯度方向会非常接近;
- 真正多样的样本,梯度方向应当显著不同;
- 梯度天然地把"input + output + reasoning chain"统一进同一个向量空间。
4.2 工程实现
- 取一个轻量级 reference model——Qwen-0.5B-Inst;
- 对每个候选样本算梯度 $\nabla_\theta \log P_\theta(y|x)$;
- 用 Rademacher Projection 降维到 1024 维(避免 GPU 内存爆炸)。
这样每个样本被映射为一个 1024 维向量 $\phi(x_i, y_i)$,构成矩阵 $\Phi \in \mathbb{R}^{|D| \times 1024}$。
4.3 G-Vendi Score:把多样性量化
构造梯度核矩阵:
对 $K$ 做特征分解得到归一化特征值 $\{\lambda_i\}$,物理含义:等价于有多少条相互正交的推理路径。这是 Vendi Score (Friedman & Dieng, Princeton 2023) 在梯度空间的版本。
实验显示:G-Vendi 与下游 OOD 泛化的相关系数 $R^2 > 0.82$(在 N=10k, 50k, 100k 三个尺度上分别为 0.8225、0.8398、0.8277)。多样性越高,模型越能在未见过的题型上推理。
右:散点图,横轴 Data Diversity Score,纵轴 Relative OOD Accuracy (%)。三种数据规模 N=10k/50k/100k 分别 $R^2 = 0.8277/0.8398/0.8225$ —— 强相关证明梯度空间的多样性是泛化的可靠预测指标。 Source: Lecture 19 · Slide 43
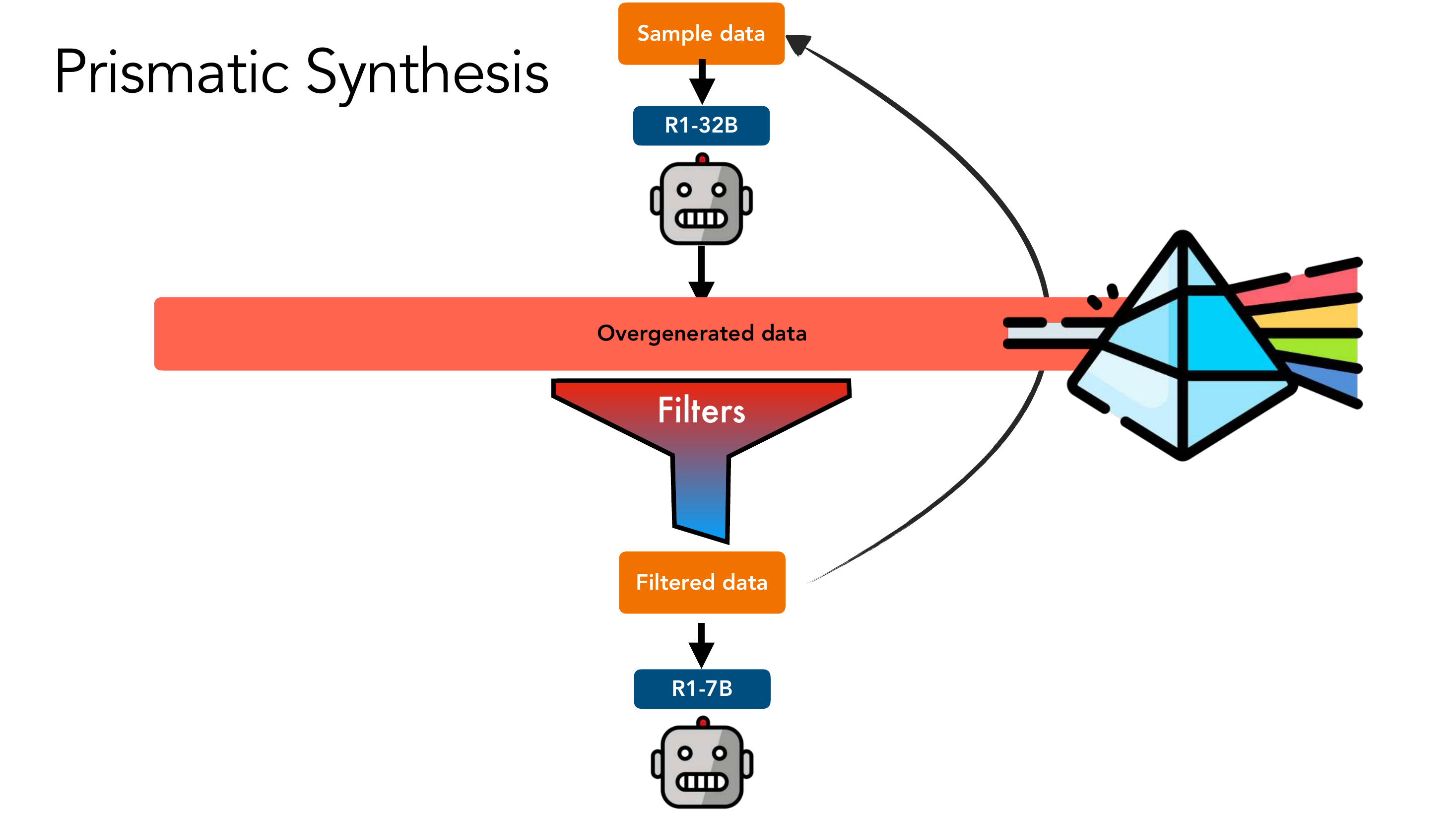
4.4 完整 Pipeline
┌──────────────────┐
│ Seed Pool │
└────────┬─────────┘
↓
┌──────────────────────────────┐
│ R1-32B 过度生成 N >> 目标 │ ← 用 20× 更小的 teacher
└────────┬─────────────────────┘
↓
┌──────────────────────────────┐
│ Gradient Diversity Filter │ ← 用 G-Vendi 选最多样的子集
│ (基于 G-Vendi) │
└────────┬─────────────────────┘
↓
┌──────────────────────────────┐
│ Quality Filter │ ← 无人工标注,纯多数票
│ (Majority Vote, 无人工标注) │
└────────┬─────────────────────┘
↓
┌──────────────────┐
│ R1-7B 训练 │
└────────┬─────────┘
↓
迭代回 Seed Pool
关键在于"先 over-generate,再用梯度多样性筛、用多数投票筛质量"的双轴过滤。
4.5 实验结果
用 20× 更小的 teacher (R1-32B) + 零人工答案,在 MATH-500 / AIME24 / AIME25 / AMC23 / MATH^2 / OlympiadBench / GSM8k-Platinum / OOD Avg 一众基准上全胜 OpenThinker-7B、OpenThinker2-7B、R1-distill-7B。

📌 关键洞察
决定 distillation 效果的不是 teacher 的绝对实力,而是 student 看到的有效多样性。梯度,是 2025 年最被低估的数据表示。
💡 对学生的启示
当你下次抱怨"我们实验室没有最大的模型可蒸馏"时——也许你的 0.5B reference model 才是真正的杀手锏。
05RLP:RL 作为预训练目标 (ICLR 2026)
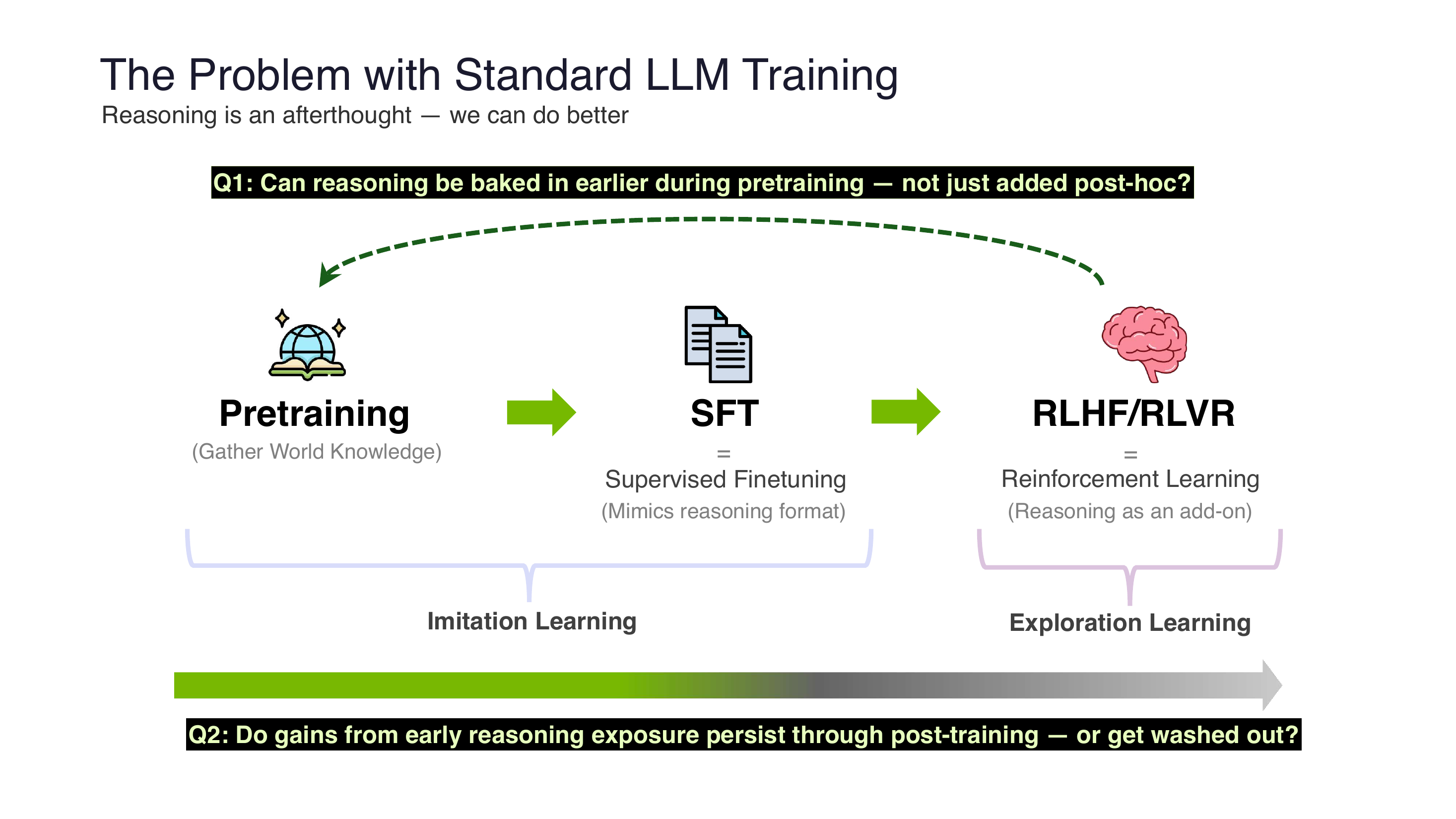
5.1 反思现有 Pipeline
今天主流的训练管线是:
$$\text{Pre-training} \;\to\; \text{SFT} \;\to\; \text{RLHF/RLVR}$$推理只是 afterthought——前面学语言、后面才学想。这合理吗?RLP 论文发出两个直击灵魂的研究问题:
- Q1:推理能否在 pretraining 阶段就植入,而不是事后添加?
- Q2:这种"早期推理收益"能否在 SFT/RLVR 后训练中存活,还是被冲掉?
5.2 关键改写:Vanilla NTP vs RLP Pretraining
经典的 next-token prediction(NTP)目标是:
$$P_\theta(x_t \mid x_{<t}) \quad \text{(Pattern Completion)}$$RLP 把它改写为:
$$P_\theta(x_t \mid x_{<t},\; c_t) \quad \text{(Reasoning-driven Prediction)}$$其中 $c_t$ 是模型在预测 $x_t$ 之前,自己采样出来的一段"思考链"——也就是模型先自言自语,再去预测下一个 token。
左路(Vanilla NTP):直接预测 $P(\text{next token}|\text{context})$ → "sunlight" — pattern completion。
右路(RLP):先生成 <think>"Photosynthesis relies on solar energy. Hence the next token must be sunlight."</think>,再预测 $P(\text{next token}|\text{context, thought})$ → "sunlight" — reasoning-driven prediction。
关键差异:RLP 让"why"在预训练阶段就visible 且 trainable,而不只是最终答案。 Source: Lecture 19 · Slide 53

5.3 核心 Reward 公式
RLP 的关键在于:如何在无 verifier 的情况下,给"这段思考"打分?答案是用信息增益:
直觉非常清晰:如果这段思考 $c_t$ 让模型更容易猜中真实的下一 token $x_t$,它就是"有用的思考",给正奖励;反之给负奖励。
$\bar p_\phi$ 是 EMA "no-think" teacher 提供的 baseline——一个不会"想"的版本作为对照。
这同时带来三大特性:
💡 Verifier-Free
完全不需要外部 ground-truth 校验器,奖励来自概率比。适用于任何 ordinary pretraining text。
⚡ Dense Reward
每个 token 位置都有 credit,不像 post-training 的稀疏 reward。提供连续的 learning signal。
📈 Scalable
与 pretraining 同等规模并行,不需要专门数据集。Reasoning emerges from plain text。
5.4 训练 Recipe
- 单网络兼 policy + reasoned predictor:用同一个 $\theta$ 既生成 thought,也预测 next-token;
- EMA "no-think" teacher:维护一个滑动平均副本 $\phi \leftarrow \tau\phi + (1-\tau)\theta$,其中 $\tau=0.999$,作为 baseline $\bar p_\phi$;
- Group-Relative Advantage with inclusive-mean correction: $$\bar r = \frac{1}{G}\sum_{j=1}^{G} r(c_t^{(j)}), \qquad A^{(i)} = \frac{G}{G-1}\Big(r(c_t^{(i)}) - \bar r\Big)$$ 避免 baseline drift;
- Clipped per-token surrogate (GRPO-style),且只在 thought tokens 上更新梯度——保护正常 NTP 信号不被破坏。 $$\mathcal{L}_{\text{clip}} = -\mathbb{E}\!\left[\frac{1}{|c_t^{(i)}|}\sum_u \min\!\Big(\rho_u^{(i)} A^{(i)},\, \text{clip}(\rho_u^{(i)};\, 1-\epsilon_\ell,\, 1+\epsilon_h)\, A^{(i)}\Big)\right]$$
5.5 实验结果
| 实验 | 设置 | 提升幅度 |
|---|---|---|
| Q1 验证 | Qwen3-1.7B-Base + RLP vs BASE | +19% |
| Q1 验证 | Qwen3-1.7B-Base + RLP vs CPT (Continued Pretraining) | +17% |
| FLOP-matched | RLP vs CPT (CPT 用 35× 更多数据) | +14% |
| Q2 验证 | After identical SFT+RLVR: RLP vs BASE+Post | +8% |
| 大规模验证 | Nemotron-Nano-12B-Base,200B 更少 tokens | +35% (Science +23%) |
🔥 关键洞察
当我们把 RL 从 post-training 提前到 pre-training,推理就不再是补丁,而是地基。RLP 的优势会在后续 SFT 和 RLVR 阶段 compound,而不是被冲掉——这回答了 Q2。
5.6 相关工作对比
| 方法 | 团队 | 核心思路 | 差异 |
|---|---|---|---|
| Quiet-STaR | Stanford (Zelikman et al., 2024) | 在 token 间隙插入 latent thought + REINFORCE | RLP 的直接前身,但规模小、依赖 special tokens |
| Reinforcement Pre-Training (RPT) | Microsoft / PKU / THU (Dong et al., 2025) | 把 next-token prediction 重构为 RL 问题 | 并行工作,思路接近但 reward 设计不同 |
| Reinforcement Learning on Pre-Training Data | Tencent Hunyuan (Li et al., 2025-09) | 工业界对 pretraining-as-RL 的同期验证 | 大规模工业部署验证 |
| RLP | NVIDIA + CMU + Stanford | Verifier-free + dense + scalable on plain text | 三大特性兼具,且经过 SFT+RLVR 后仍 compound |
💡 对学生的启示
思路要敢"前移"。"为什么推理只能放在最后?为什么 next-token prediction 不能让模型先想一下再预测?"——一个看似简单的问号,撬动了一整代 pipeline。
06Front-Loading Reasoning:推理数据应当注入到哪里 (ICLR 2026)
6.1 一个系统性问题
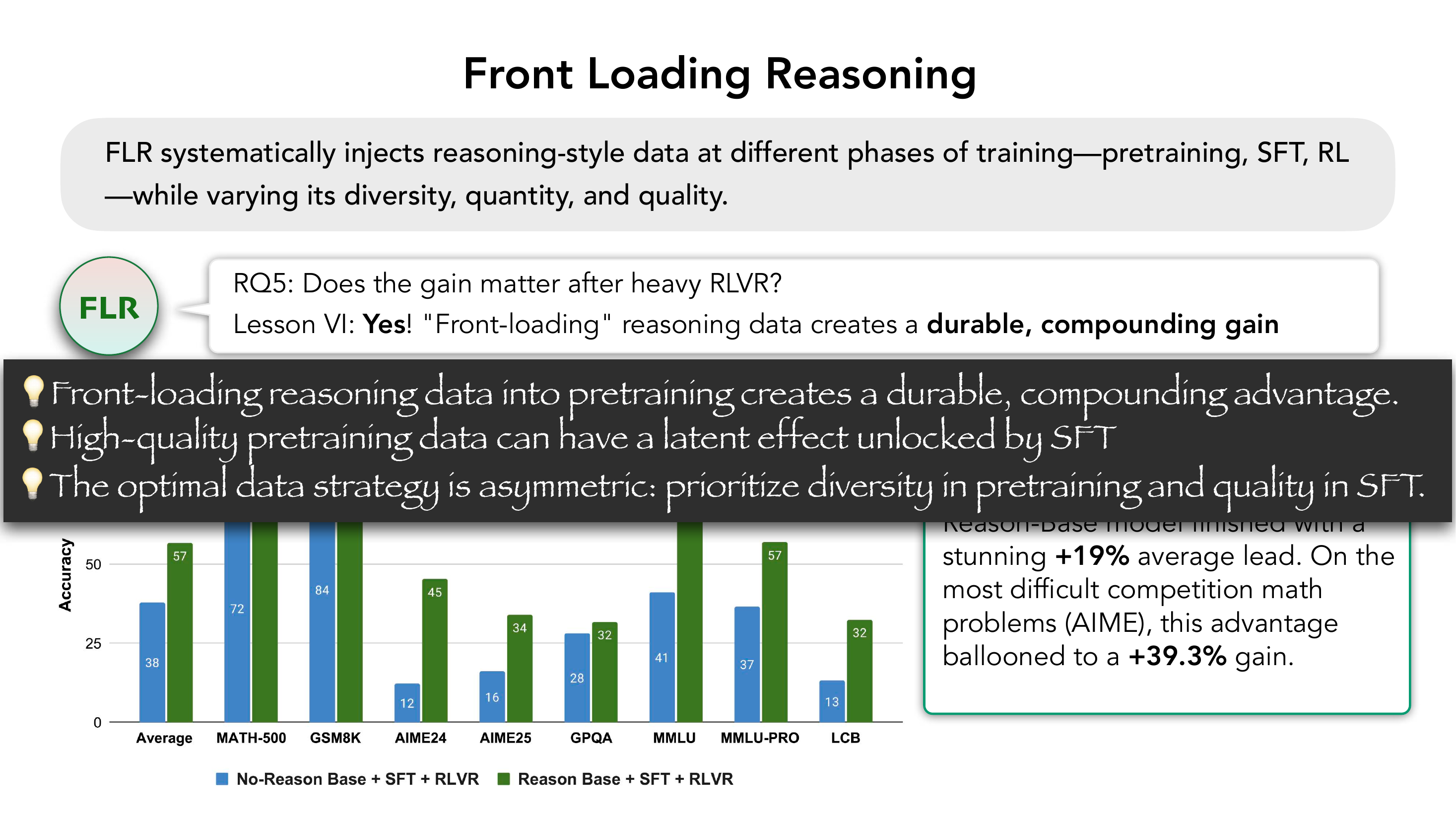
研究者在 pretraining / SFT / RLVR 三个阶段做了正交的注入实验,并系统调节 diversity、quantity、quality 三个旋钮。
6.2 五大研究问题与六大教训
预训练阶段加推理数据 → +16% 平均提升,且与 diversity 和 quantity 同时 scale(双轴 scaling law)。在 MATH/SCIENCE/CODE/GPR 上全面涨点。
no-reason 预训练 + 2× SFT 仍然输给最弱的 reason-pretrained 模型。具体:双倍 SFT 数据让 baseline 提升 +4.09%,但仍比最弱的 reason-pretrained 模型低 -3.32%。
"后期再多的精装修,也填不平地基的塌陷。"
经过 RLVR 后,reason-pretrained 模型领先 +19%,AIME 上 +39.3%。Front-loading 创造的不只是早期优势,而是 durable + compounding 的优势。
Yue et al. 说 "RLVR 不能扩展 base model 之外的 capacity";FLR Lesson VI 说 "能,前提是 base 中已经有 reasoning prior"。两者共同精化了 capacity 边界条件——这与 Zhao et al. (Harvard) 的 "Echo Chamber" 理论完全一致:RL 是放大器,不是生成器。
6.3 三大结论
Conclusion 1
Front-loading 推理数据是 durable & compounding 的优势。早期注入的能力会在后续每个阶段不断放大。
Conclusion 2
高质量预训练数据存在 latent effect,会被 SFT 解锁。有些好处不是 pretraining 完就显现,而是要等 SFT 这把钥匙。
Conclusion 3
非对称数据策略:Pretraining 重 diversity(广撒网,铺地基);SFT 重 quality(精雕细琢,做装修)。
关键结论:差距不是"被 SFT+RLVR 抹平",而是"被 SFT+RLVR 放大"——这正是 Zhao et al. (Harvard) "Echo Chamber" 效应的直接证据:RL 放大 pretraining 学过的行为。 Source: Lecture 19 · Slide 67
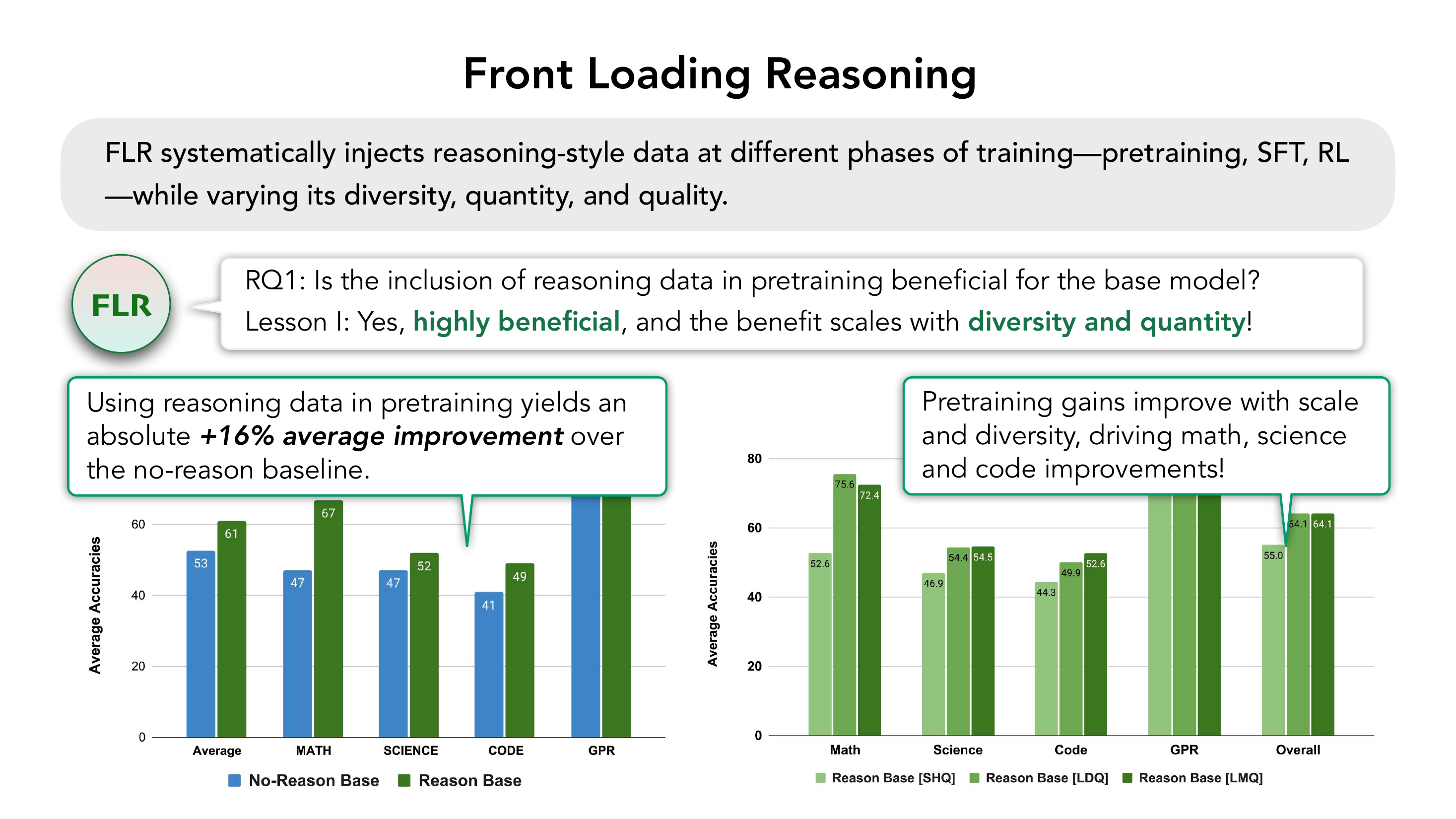
右:随着 diversity 与 quantity 同时 scaling,提升进一步扩大——Reason Base [SHQ → LDQ → LMQ] 的曲线呈双轴上升。 Source: Lecture 19 · Slide 65
⚠️ 关键洞察
阶段对了,加 10× 数据;阶段错了,10× 也只能填坑。
💡 对学生的启示
当你设计 data pipeline 时,第一个问题不该是"我有多少数据",而是"这份数据要放在哪个阶段"。
07OpenThoughts3 与 "Unconventional Collaboration"
7.1 OpenThoughts3-1M 数据 Pipeline
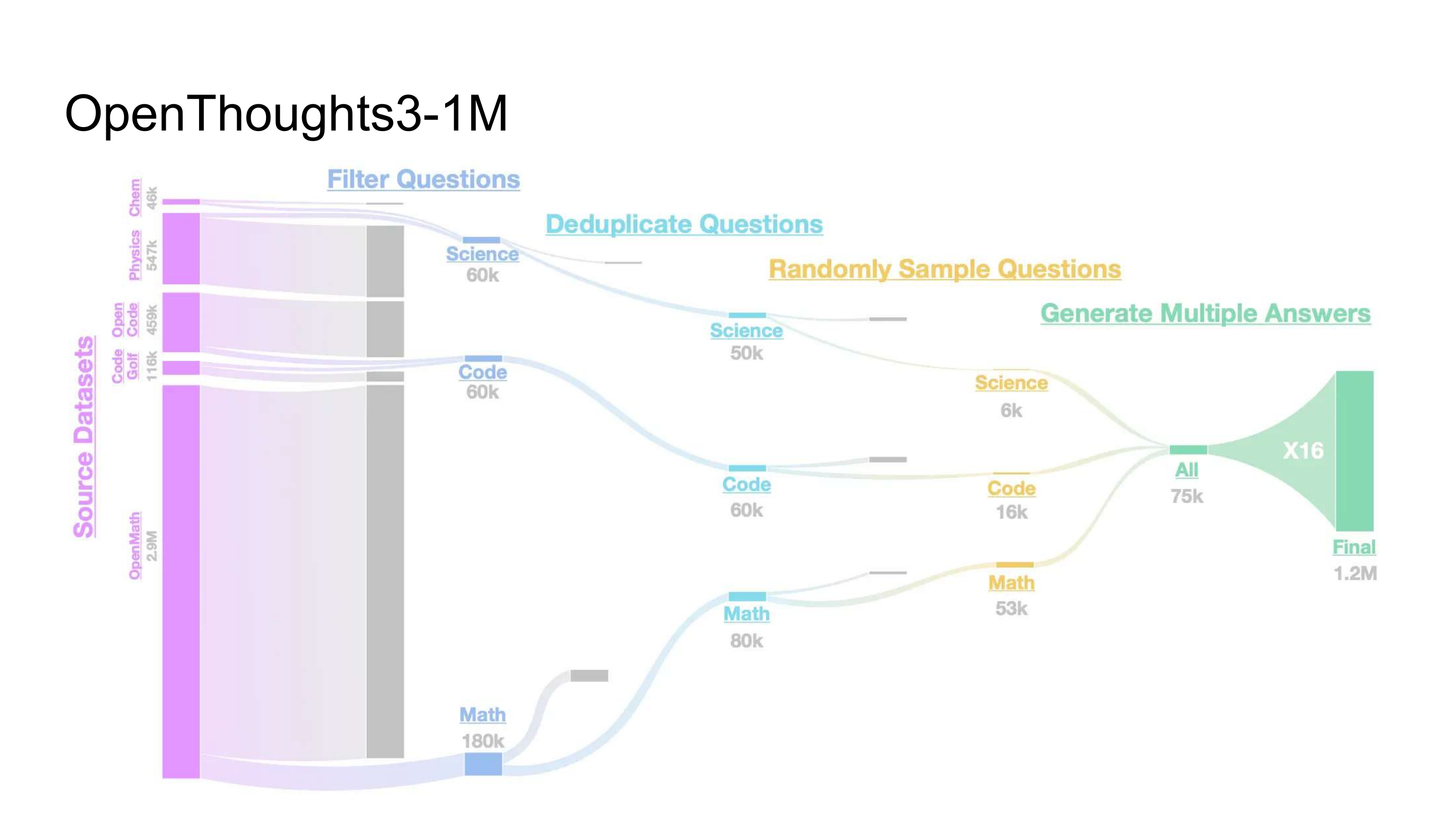
过滤问题:Math 180k, Code 60k, Science 60k →
去重 + 随机采样:Math 53k + Code 16k + Science 6k = All 75k 题 →
每题 16× rollouts (R1 系列教师):Final 1.2M 推理样本。 Source: Lecture 19 · Slide 71
注意三个工程细节:
- 从海量到精选——4M 候选筛到 75k 题;
- 多答案采样——每题 16 个 rollout,捕捉解法多样性;
- 不依赖人工标注——完全 self-distillation flywheel。
7.2 结果对比
| 模型 | Train Size | Method | Open Data? | Average |
|---|---|---|---|---|
| OpenThoughts3-7B | 1.2M | SFT | 🟢 Yes | 55.3 |
| Nemotron-Nano-8B | 3.9M | SFT/RL | 🟢 Yes | 53.2 |
| AceReason-7B | 57K | RL | 🟡 Partial | 52.9 |
| Skywork-7B | 119K | RL | 🟡 Partial | 51.6 |
| NemoNano-1M | 1M | SFT | 🟢 Yes | 47.3 |
| AM-1.4M | 1.4M | SFT | 🟢 Yes | 42.1 |
| DS-R1-Qwen-7B | 800K | SFT | 🔴 No | 42.9 |
| Qwen2.5-7B-Instruct (Base) | N/A | — | — | 24.0 |
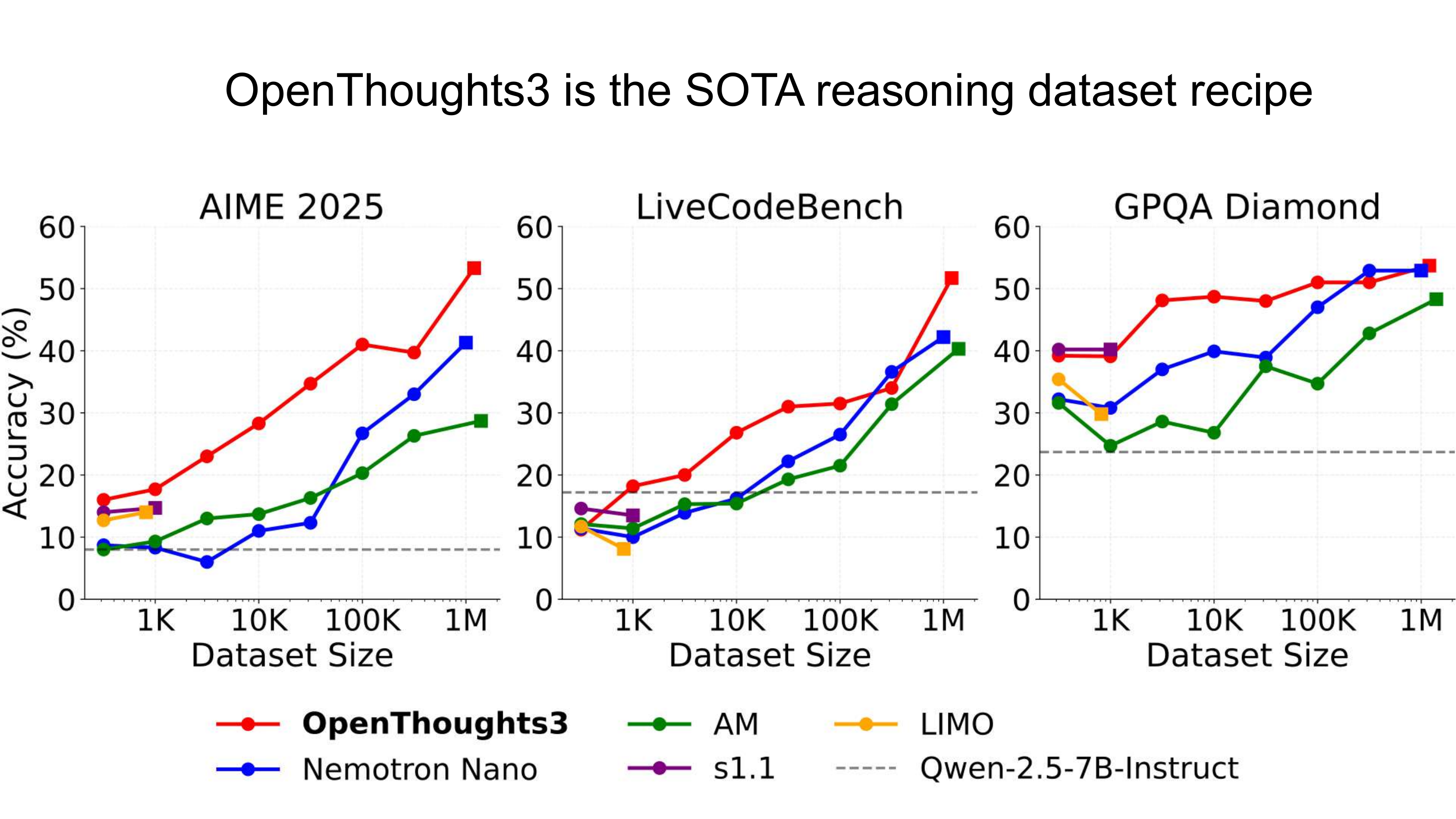
在 Math (AIME24 69.0, AMC23 93.5)、Code (CodeForces 32.2, LCB 64.5)、Science (JEEBench 72.4)、Held-Out (HMMT 42.7, AIME25 53.3) 上 OpenThoughts3 全面领先。
🔥 关键洞察
Super effortful SFT > effortful RL. 当你的 SFT 数据极尽精细(高 diversity + 高质量 teacher + 16-way 采样),它在很多场景下能击败昂贵复杂的 RL 训练。
7.3 启示:开源协作作为方法论
OpenThoughts3 不只是一个数据集,它是一种研究范式的范例:
- 开放:每一个 ablation 都有公开 log;
- 协作:每一份数据都有公开 license;
- 可复现:每一个作者都能在 README 上找到自己的名字。
💡 对学生的启示
你的下一个 SOTA,未必出自你一个人的 GPU。学会发起一次跨实验室协作,可能比再发 3 篇一作还要珍贵。
08贯穿全篇的三大 Insight 与方法论
8.1 Insight 1:Chemistry between base LLM and RL matters
相同的 RL 算法(同样的 GRPO、同样的 reward shaping),换一个 base model 就可能完全失效。原因 Zhao et al. (Harvard) 已经给出:RL 是在放大 base 预训练学过的行为。因此:
- 如果你的 base 不会某种解法,RL 几乎不可能"教会"它;
- 如果你的 base 已经会但概率很低,RL 能把它"调亮";
- 如果你的 base 已经过拟合到某种解法,RL 会进一步窄化它。
这就是 Spurious Rewards 实验里 Qwen2.5-Math-7B 用 random reward 都能涨 21%、但同样配方在 Llama3.1-8B 与 OLMo2-7B 上失败的根本原因。
8.2 Insight 2:Conclusions from effortless ≠ effortful
这是对整个领域的方法论警示。许多论文用一个"随手做的 RL"得出"RL 不行/RL 很好"的结论,都不足为信。真正的判断必须建立在 effortful 实验之上——entropy 控制、reference reset、long horizon、Pass@K 监控、与 base 的 chemistry 分析,一个都不能少。
类比一句不太雅的西方俗语——"Laws are like sausages; it is better not to see them being made." SOTA reasoning 模型的训练过程,正如制作香肠:远看光鲜,近看是无数次重启、调参、reset、retry 的脏活累活。
· Conclusions from effortless RL ≠ effortful RL
· Conclusions from effortless SFT ≠ effortful SFT
8.3 Insight 3:三个非常规创新维度
| 维度 | 核心策略 | 代表工作 |
|---|---|---|
| Unconventional Data 🔥 | gradient diversity / front-loading / self-distillation flywheel | Prismatic Synthesis (Ch.4), FLR (Ch.6), OpenThoughts3 (Ch.7) |
| Unconventional Algorithms 🚀 | DAPO clip-higher, ProRL endurance, RLP-as-pretraining | ProRL (Ch.2), RLP (Ch.5) |
| Unconventional Collaboration 🌍 | 50+ 作者跨 16 机构,纯开源协作 (implicit + explicit) | OpenThoughts3 (Ch.7) |
8.4 三大核心张力分析
RL-generalizes 阵营:Chu et al. (Berkeley), Huan et al. (CMU) 证明 SFT 倾向 memorization,RL 倾向 generalization。
SFT-generalizes 反驳:OpenThoughts3-7B 用纯 SFT 达到 55.3 平均分,超过 DeepSeek-R1-Distill-7B 的 42.9。FLR Lesson IV 又显示双倍 SFT 只能涨 4.09%。
Choi 的潜台词调和:这个矛盾的解法藏在 Insight 2 里。Chu/Huan 测试的是 effortless SFT vs effortless RL;OpenThoughts 测试的是 super-effortful SFT;FLR 测试的是 effortless SFT vs effortful pretraining。结论应该是:效率排序不是 SFT < RL,而是 effortless < effortful,无论哪种范式。
Post-training 阵营:2024-2025 主流(DeepSeek R1, o3)都把推理放在 post-training 的 RL 阶段。
Pre-training 阵营:RLP 与 FLR 同时挑战这个范式。FLR Lesson VI 给出量化答案:经 RLVR 后差距从 +16% 扩大到 +19%,AIME 上甚至 +39.3%——早期注入的推理不仅没被 post-training 抹平,反而被 amplified。
调和机制:这与 Zhao et al. (Harvard) "Echo Chamber" 完全一致——RL 是放大器而非生成器。把"何时注入"的辩论转化为"pretraining 是因,post-training 是果"。
大教师路线:OpenAI/Anthropic/DeepSeek-R1/Qwen-Max/Phi-4 都用最大可用模型当 teacher。
小教师 + 多样化路线:Prismatic Synthesis 用 20× 更小的 R1-32B + G-Vendi 多样性 filter + 零人工标注,超越所有 7B 基线。
关键调和:Shumailov et al. 的 model collapse 警告给出根本约束——单一大教师必然导致 mode collapse。Prismatic 的胜利来自把"质量"重新定义为"梯度空间的多样性 + majority vote quality",而非"teacher size"。这暗示一个新的 scaling law:数据 utility ∝ G-Vendi diversity × quality, 而非 ∝ teacher size。
8.5 知识图谱:六大主题间的核心关系
下面是 10 条贯穿本教材的核心关系箭头(→ 表示"驱动/暗示",⇌ 表示"互相强化",⊕ 表示"组合产生"):
- LRM 范式 (Ch.1) → Spurious Reward 发现 → 推理能力归因到 base model → ProRL/Prismatic/RLP 三条路径
- ProRL (Ch.2) ⇌ DAPO entropy 控制——互为镜像,互证可行性
- Mode Collapse (Ch.3) → Prismatic Synthesis (Ch.4) 的存在理由
- Prismatic (Ch.4) ⊕ ProRL (Ch.2) = effortful data + effortful algorithm——两者乘起来才能 democratization
- Echo Chamber (Zhao/Harvard) → RLP (Ch.5) + FLR (Ch.6) 的理论合法性
- RLP "how" ⇌ FLR "what"——RLP 提供机制,FLR 提供消融证据
- FLR Lesson VI → 修正 Yue et al. 的悲观结论——RLVR 能扩展 capacity,前提是 base 已有 reasoning prior
- OpenThoughts (Ch.7) 的 super-effortful SFT → 击败 effortful RL → 反向佐证 Insight 2
- Chemistry 隐喻 (Insight 1) → 解释为什么 ProRL/Prismatic/RLP 都强调 base model 选择
- 三个 Innovation (Insight 3) → 完美映射到 Ch.2+3+4 (algorithm), Ch.4+7 (data), Ch.7 (collaboration)
📌 综合洞察
Chemistry 隐喻揭示了 Choi 对 scaling laws 的根本批判——scaling laws 假设 "性能 = f(参数, 数据, 计算)" 是可分解的乘法关系;而 chemistry 视角主张 "性能 = g(base × algorithm × data × stage)" 是 非分解的相互作用。这与统计学的 interaction effect 概念一致——主效应可加但交互效应必须共同测量。
09开放问题与对 NLP 研究生的实践建议
9.1 知识宇宙的五个来源
把"模型能学到的知识"看作一个宇宙,它的来源大致有五条:
- Internet Data —— 化石燃料,正在被烧完
- Conventional Distillation —— 从最大教师抽取,受 mode collapse 限制
- Human Expert Annotation —— 昂贵、慢、不可规模化
- Extreme Scaling of Reasoning —— RLVR / RLP / ProRL 这条路
- Unconventional Simulation —— 让模型在合成环境中自博弈,是一片尚未充分开垦的处女地
The Universe of Knowledge ≈ The Universe of Synthetic Data.
当 internet 的化石燃料烧尽,未来模型能力的天花板,将由我们能合成的数据的质量、多样性、与真实性共同决定。
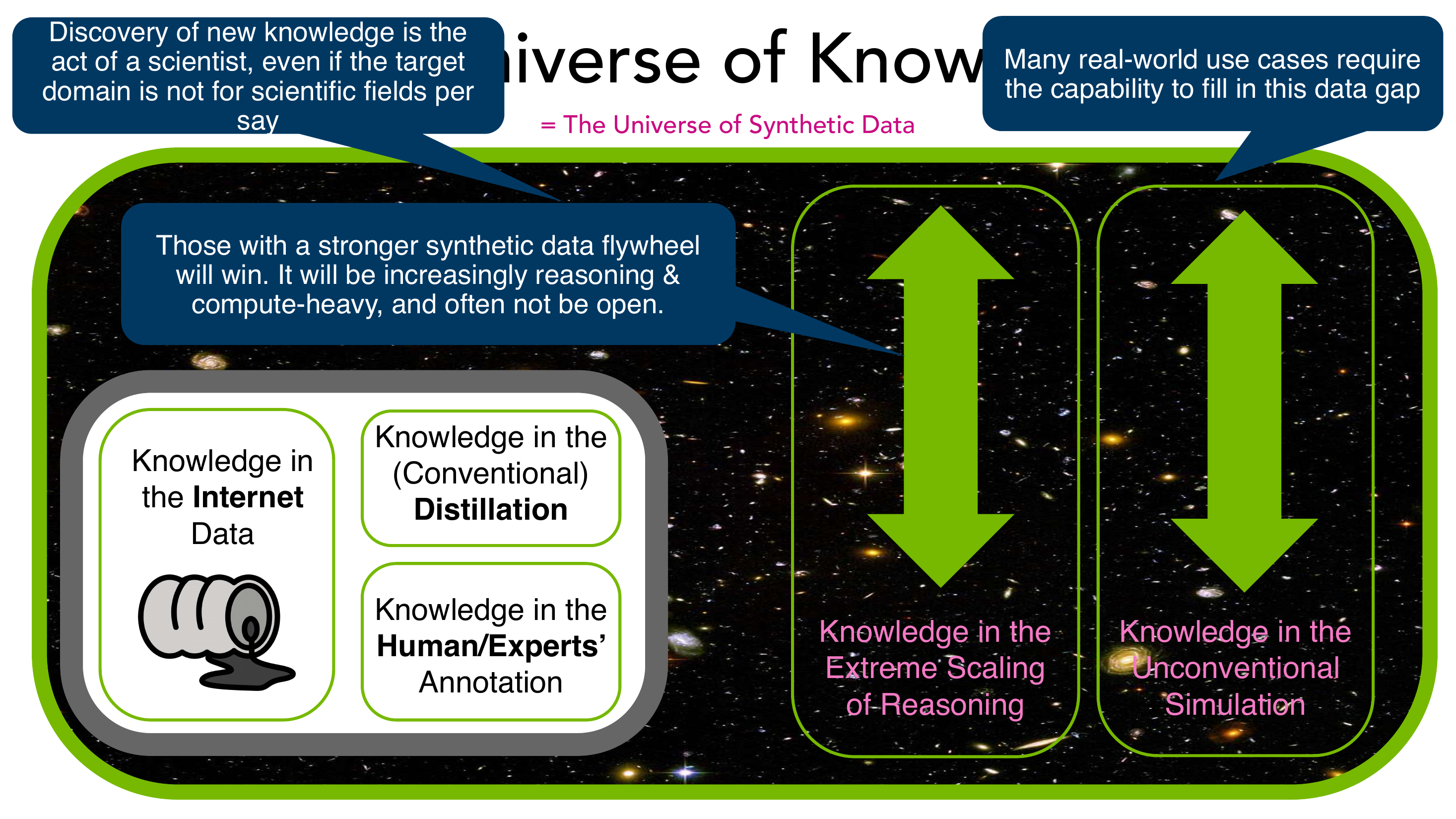
右侧两条粉色发光柱:Knowledge in Extreme Scaling of Reasoning + Knowledge in Unconventional Simulation。
Choi 的核心论断:"Those with a stronger synthetic data flywheel will win. It will be increasingly reasoning & compute-heavy, and often not be open." 当 Internet 化石燃料烧尽,AI 能力的天花板由我们能"合成"的数据决定。 Source: Lecture 19 · Slide 84

右:AI diverges from human intelligence — More data, compute, memory / Less abstraction & conceptualization / Clear separation between training and testing。 Source: Lecture 19 · Slide 87

9.2 AI 智能:人类的镜像,还是另一个物种?
| AI 与人类智能的相似 | AI 与人类智能的偏离 |
|---|---|
| Reasoning is often memorized knowledge | More data, compute, and memory |
| Exploitation vs exploration trade-offs | Less abstraction and conceptualization |
| Diverse examples/experiences enhance learning | Clear separation between training and testing |
是镜像,还是偏离?答案目前无人知晓。但有一点是确定的:How sausages are made. AI 的"智能"在很大程度上是人类智能的复合产物——人类的 internet data + 人类的资本投入 + 人类的 annotations + 人类的工程直觉。
9.3 三个尚未回答的大问题
Q1:新的智能理论?
我们至今没有一个能解释"为什么 RL 在 base A 上 work,在 base B 上不 work"的理论。Chemistry 隐喻需要被操作化、可证伪化。
Q2:新的知识/推理理论?
信息论给了我们 entropy,但没有给我们"reasoning 量化"的语言。RLP 的 information gain reward 是个起点,但还远远不够。
Q3:1M tokens context = 限制 or 祝福?
当模型可以"看完整本教材再回答一个问题",prompting / retrieval / reasoning 三者的边界正在模糊。人类没有 1M token 的 working memory——这是 AI 的优势还是劣势?
9.4 给 NLP 研究生的六条实践建议
Endurance > sprint。1.5B 的 ProRL 已经证明:单卡多月的长跑,足以踩出 SOTA。你需要的不是更多 GPU,而是更聪明的 entropy 控制。
学会设计 "over-generate → filter → train → iterate" 的循环,比追逐下一个开源 checkpoint 更有价值。Prismatic Synthesis 是最好的入门样本。
OpenThoughts3 证明:你不需要 100 张 H100,你需要 50 个志同道合的 PR 提交者。学会发起跨实验室协作,远比"再发 3 篇一作"更有长期价值。
这是判断你在做泛化还是窄化的唯一可靠指标。Yue et al. (2025) 的警告必须时时铭记——Pass@1 涨而 Pass@K 跌,意味着你只是在剪枝。
在做实验之前先问:我打算 effortless 地证明什么,还是 effortful 地搞清楚什么?两种实验产生的论文截然不同——前者是 "新颖性但脆弱",后者是 "无聊但持久"。
不只是论文里的推理数据,研究生涯本身也应当 front-load——早期投入到地基(理论、方法论、复现能力)的时间,会在后续每个阶段被放大。
9.5 有研究机会的方向(来自 synthesis)
- 方向 A:Chemistry 的可证伪化——能否定义一个 "RL-receptiveness score" 来预测某个 base 在某个 RL 算法下的涨点幅度?
- 方向 B:Pretraining-stage reasoning 的理论分析——为什么 EMA "no-think" teacher 的 reward 信号没有 reward hacking?$\tau=0.999$ 为何是甜区?
- 方向 C:G-Vendi 之外的 data utility 度量——attention rollout、activation patching 等替代 representation 能否提供更好的 diversity 指标?
- 方向 D:Small Reasoning Model 的可解释性——用 mechanistic interpretability (SAE, circuit discovery) 研究 ProRL 前后 1.5B 模型在推理 task 上的电路变化。
- 方向 E:Collaboration 范式的元研究——OpenThoughts 的 50+ 作者跨 16 机构是新的科研组织形式,其 reproducibility 与可扩展性如何?
9.6 已饱和或高门槛的方向(不建议作为学生项目起点)
- 更大 LRM 的端到端训练:被巨头主导,计算门槛超出学生项目;
- GRPO 算法层面的微调:DAPO/Dr.GRPO/REINFORCE++ 等变体已经很多,新变体边际贡献小;
- 新数学 benchmark 的构建:MATH/AIME/HLE 已经形成评估生态,新 benchmark 难以推开除非有显著新维度。
9.7 可用工具与数据集清单
| 类别 | 资源 | 用途 |
|---|---|---|
| 模型权重 | Nemotron-Research-Reasoning-Qwen-1.5B | ProRL 产物,可作为 SOTA 小模型 baseline |
| 模型权重 | OpenThoughts3-7B | 开源 SFT 推理模型 baseline |
| 模型权重 | Qwen3-1.7B-Base / Qwen2.5-Math-7B | spurious reward 与 RLP 标准 base |
| 数据集 | OpenThoughts3-1M | 含 source/filter/dedup/sample/generate 全 pipeline 元信息 |
| 数据集 | DAPO-Math-17k | GRPO 训练标准数学集 |
| 数据集 | Reasoning Gym | 100+ procedurally generated 推理任务 |
| 评估 | HLE / AIME / AMC / OlympiadBench / GSM8k Platinum / IFEval | 覆盖 reasoning / instruction following |
| 代码库 | verl (ByteDance) | DAPO/GRPO 工业级实现 |
| 代码库 | TRL (HuggingFace) / OpenRLHF | 通用 RLHF 框架 |
9.8 阅读路径建议
1 个月内入门"小模型推理化"研究前沿的推荐顺序:
- 范式层:DeepSeek-R1 paper + OpenAI o1 system card
- 批判层:Yue et al. + Shao/Li spurious rewards + Zhao echo chamber
- 算法层:GRPO (DeepSeekMath) + DAPO + ProRL
- 数据层:Shumailov collapse + Prismatic Synthesis + OpenThoughts
- 阶段层:Quiet-STaR + RLP + FLR
这条路径对应本教材的论证结构:先看到范式,再看到批判,再看到三条建设性路径。
9.9 尾声
Ryan Holiday 有一本书叫《Ego is the Enemy》。在 LLM 这个被巨头光环和资本喧嚣笼罩的领域里,这句话尤为应景。
真正的小模型推理革命,不是靠某个明星 PI 的天才一念,而是靠一群愿意把 entropy 曲线看上几千次、愿意 reset reference policy 八次、愿意为别人的 ablation table 提 PR 的研究者们。
💡 对学生的最终启示
David 没有变成 Goliath。David 只是学会了用石头甩出抛物线——而那条抛物线的方程,是由我们这一代 NLP 研究生写下的。
去做那块石头。去甩那条抛物线。