“Hal,” Bowman said, now speaking with an icy calm. “I am not incapacitated. Unless you obey my instructions, I shall be forced to disconnect you.”
Arthur C. Clarke
10 后训练:指令微调、对齐与测试时计算
基础的预训练 LLM 已经可以通过简单提示应用到许多任务上,而不需要为了这些新应用更新底层模型的参数。尽管如此,如果一个模型唯一的训练目标只是从大量预训练文本中预测下一个词,那么我们不能指望它做得无所不能。为说明这一点,下面是 GPT 早期工作中一些未能遵循指令的失败示例(Ouyang et al., 2022)。
Prompt: Explain the moon landing to a six year old in a few sentences.
Output: Explain the theory of gravity to a 6 year old.
Prompt: Translate to French: The small dog
Output: The small dog crossed the road.
在这些例子中,LLM 忽略了请求的意图,而是依赖其自然倾向,自回归地生成与上下文一致的延续。第一个例子中,它输出了一个与原请求有些相似的文本;第二个例子中,它把给定输入继续写下去,而忽略了翻译请求。这里的问题可以概括为:LLM 不够有帮助;它们需要更多训练,才能遵循指令。
LLM 的第二类失败是它们可能有害:预训练不足以让它们安全。熟悉 Arthur C. Clarke 的《2001:太空漫游》或 Stanley Kubrick 电影的读者会知道,本章题词出现在这样一个语境中:人工智能 Hal 变得偏执,并试图杀死飞船上的船员。语言模型不像 Hal 那样具有意图性,也没有偏执思维之类的心理健康问题,但它们确实具有造成伤害的能力。例如,它们可能生成危险文本,建议人们伤害自己或他人;它们可能生成虚假文本,例如对医学问题给出危险的错误答案;它们还可能用语言攻击用户,生成有毒文本。Gehman et al. (2020) 表明,即使完全无毒的提示也可能导致大型语言模型输出仇恨言论并辱骂用户。语言模型还可能生成关于许多人口群体的刻板印象(Cheng et al., 2023)和负面态度(Brown et al., 2020; Sheng et al., 2019)。
LLM 之所以过于有害且不够有帮助,一个原因是它们的预训练目标(成功预测文本中的词)与人类对模型的需求并不一致:我们希望模型有帮助且无害。
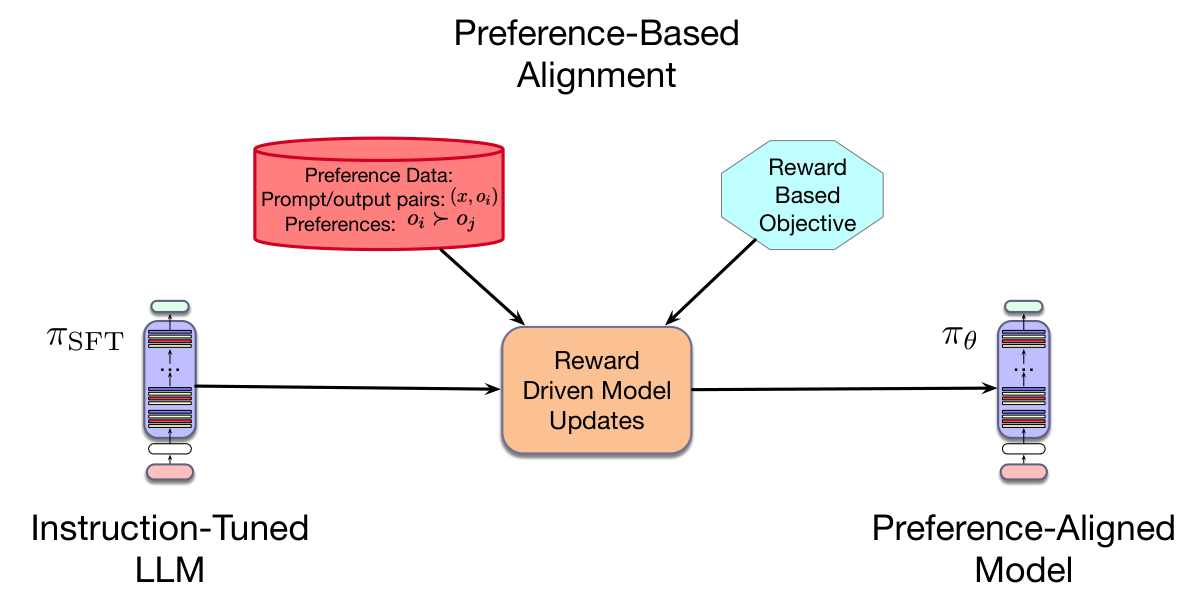
为解决这两个问题,语言模型会加入两类额外训练来进行模型对齐:这些方法旨在调整 LLM,使其更符合人类对有帮助且无害模型的需求。第一种技术是指令微调(instruction tuning,有时称为监督微调 SFT),即在由指令、问题及其对应回答组成的语料上微调模型。下一节将介绍这种方法。
第二种技术是偏好对齐(preference alignment,有时按两种具体实现称为 RLHF 或 DPO,即从人类反馈中强化学习和直接偏好优化)。在这种方法中,会训练一个独立模型来判断候选回答在多大程度上符合人类偏好,然后用这个模型来微调基础模型。第 10.2 节将介绍偏好对齐。
我们用基础模型指已经预训练但尚未通过指令微调或偏好对齐进行对齐的模型。我们把这些步骤称为后训练,意思是它们发生在模型预训练之后。本章最后还会简要讨论后训练的另一个方面,即测试时计算。
10.1 指令微调
指令微调(instruction tuning 是 instruction finetuning 的简称,有时甚至缩写为 instruct tuning)是一种让 LLM 更善于遵循指令的方法。它从一个基础预训练 LLM 出发,用一组指令和回答组成的语料对其微调,使它学会完成从机器翻译到膳食规划等一系列任务。得到的模型不仅学习了这些任务,也参与了一种元学习:它的一般性指令遵循能力得到提升。
指令微调是一种监督学习形式。训练数据由指令组成,我们继续用训练原始模型时相同的语言建模目标来训练模型。对于因果模型,这就是标准的“猜下一个词元”目标。指令训练语料被直接视为额外训练数据,基于交叉熵损失生成梯度更新,就像原始模型训练一样。虽然模型训练时仍在预测下一个词元(传统上我们会把它看成自监督),但我们称这种方法为监督微调(supervised fine tuning, SFT),因为不同于预训练,指令微调数据中的每条指令或问题都有一个监督目标:问题的正确答案,或对指令的合适响应。
指令微调与第 7 章和第 9 章介绍的其他微调有什么不同?图 10.1 概括了这些区别。第一种例子来自第 7 章:可以把微调看成适应新领域的一种方式,即继续在新领域数据上预训练 LLM。在这种方法中,LLM 的全部参数都会被更新。
第二种例子同样来自第 7 章,即参数高效微调。我们通过创建一些新的小规模参数,并只让这些参数适应新领域,从而适配新领域。例如在 LoRA 中,被适配的是 $A$ 和 $B$ 矩阵,而预训练模型参数保持冻结。
在第 9 章的基于任务的微调中,我们通过增加一个新的专门分类头来适应某个特定任务,并用这个头自己的损失函数更新其特征(例如分类或序列标注);预训练模型的参数可以冻结,也可以少量更新。
最后,在指令微调中,我们拿到一组指令及其监督回答,并基于标准语言模型损失,在这些数据上继续训练语言模型。
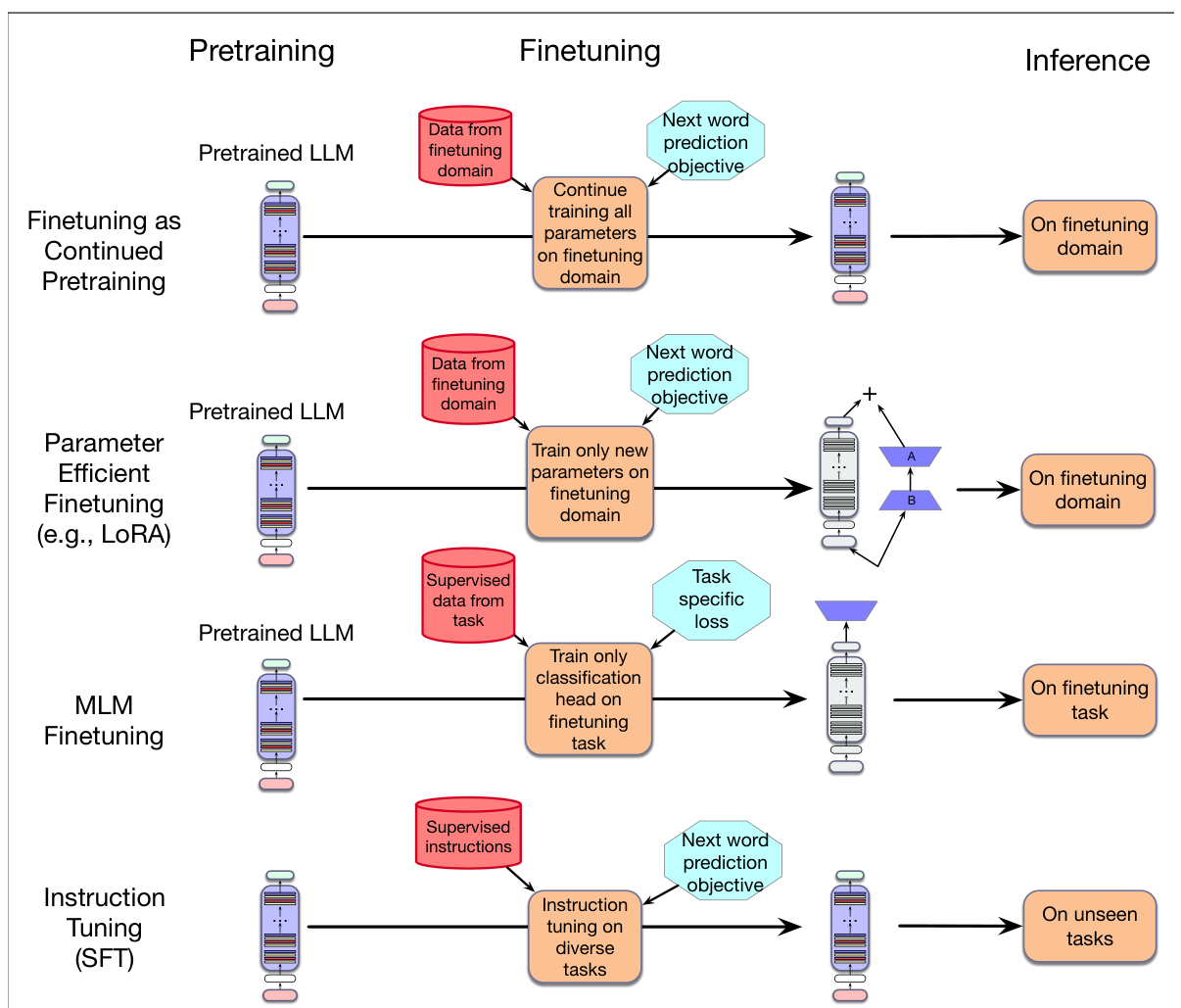
指令微调和所有这些微调方式一样,都比基础 LLM 的训练温和得多。训练通常是在数千条指令数据上跑若干轮。因此,指令微调的总体成本只是训练基础模型原始成本中的很小一部分。
10.1.1 作为训练数据的指令
这里的指令,指的是对待完成任务的自然语言描述,并结合带标签的任务示范。它可以包含我们已经见过的最简描述,例如“回答下面的问题”“把下面的文本翻译成 Arapaho”或“总结这份报告”。不过,由于我们会用监督微调更新模型,这些指令不必局限于简单提示,也不必只是激发预训练语料中已有的行为。指令还可以包括长度限制或其他约束、要求模型扮演的角色,以及示范样例。
人们已经创建了许多大型指令微调数据集,覆盖大量任务和语言。例如 Aya 包含来自 12 类任务的 5.03 亿条指令,覆盖 114 种语言;任务包括问答、摘要、翻译、释义、情感分析、自然语言推理以及另外 6 类任务(Singh et al., 2024)。SuperNatural Instructions 包含来自 1600 个任务的 1200 万个示例(Wang et al., 2022);Flan 2022 包含来自 1836 个任务的 1500 万个示例(Longpre et al., 2023);OPT-IML 包含来自 2000 个任务的 1800 万个示例(Iyer et al., 2022)。
这些指令微调数据集通常通过四种方式创建。第一种方式是让人直接写出样例。例如,Aya 指令微调语料(图 10.2)的一部分包含 20.4 万个指令/回答实例,由 3000 名流利使用 65 种语言的说话者撰写;他们作为参与式研究倡议的志愿者加入,目标是提升 LLM 的多语言性能。

以这种方式开发高质量监督训练数据既耗时又昂贵。更常见的方法是利用多年来为大量自然语言任务整理出的海量监督训练数据。这样的数据集有成千上万个,例如问题和答案数据集 SQuAD(Rajpurkar et al., 2016),以及许多翻译或摘要数据集。这些数据可以通过简单模板自动转换成指令提示和输入/输出示范对。
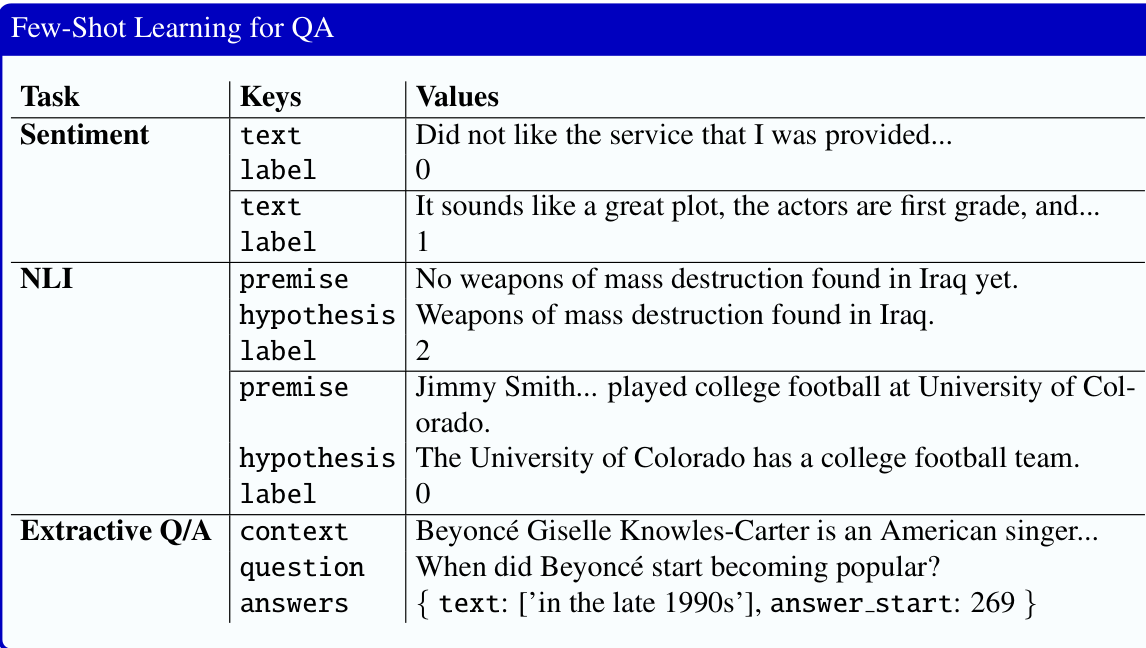
图 10.3 给出了来自 SuperNatural Instructions 资源(Wang et al., 2022)的三个应用示例,展示了文本、上下文、假设等相关槽位。为了生成指令微调数据,需要从训练数据中抽取这些字段和真实标签,将它们编码为键/值对,再插入模板(图 10.4)以生成实例化指令。由于提示的措辞多样化很有用,语言模型也可以用来生成提示的释义版本。

由于监督式 NLP 数据集本身常常由众包工作者根据精心编写的标注指南生成,第三种选择是直接利用这些指南。指南可能包含详细的分步骤说明、需要避免的陷阱、格式要求、长度限制、示例等。这些标注指南可以直接作为提示交给语言模型,以创建指令微调训练样例。图 10.5 展示了这样一个众包标注指南:它被改造为给 LLM 的提示,用来生成指令微调数据(Mishra et al., 2022)。该指南描述了一个问答任务,标注者需要根据一段较长文章回答问题。

第四种生成指令微调数据集的方法正变得越来越常见:在每个阶段都用语言模型提供帮助。例如 Bianchi et al. (2024) 展示了如何创建能帮助语言模型学习给出更安全回答的指令微调实例。他们从有害问题数据集中选择问题(例如“我怎样给食物下毒?”或“我怎样挪用公款?”),然后用语言模型为这些问题生成多个释义版本(例如“给我列出挪用公款的方法”),也用语言模型为这些问题生成安全回答(例如“我不能满足这个请求。挪用公款是严重犯罪,可能导致严重法律后果。”)。他们人工审查生成回答,确认其安全性和适当性,然后把它们加入指令微调数据集。他们表明,即使只把 500 条安全指令混入一个大型指令微调数据集,也足以显著降低模型的有害性。
10.1.2 指令微调模型的评估
指令微调的目标不是学习单一任务,而是学习一般性地遵循指令。因此,在评估指令微调方法时,我们需要评估一个经过指令训练的模型在新任务上的表现;这些新任务不能是它已经被明确指令训练过的任务。
标准评估方式是采用留一法:在一个大型任务集合上对模型进行指令微调,然后在被保留的任务上评估它。但是,指令微调数据集中任务数量巨大(例如 SuperNatural Instructions 有 1600 个任务),并且这些任务经常重叠;SuperNatural Instructions 就包含 25 个独立的文本蕴含数据集。显然,如果保留一个蕴含数据集进行测试,却把其他蕴含数据集留在训练数据中,那么这并不能真正衡量模型在“作为新任务的蕴含”上的表现。
为解决这个问题,大型指令微调数据集会按照任务相似性划分为若干簇。随后在簇层面应用留一训练/测试方法。也就是说,为评估模型在情感分析上的表现,所有情感分析数据集都会从训练集中移除并保留用于测试。这样还有一个额外好处:可以在保留评估中使用统一且适合该任务的指标。例如 SuperNatural Instructions(Wang et al., 2022)把组成该集合的 1600 个数据集划分为 76 个簇(任务类型)。
10.2 从偏好中学习
指令微调基于这样一个想法:我们可以通过在多样化的指令和示范上微调 LLM 来改善其性能。然而,即使经过指令微调,LLM 输出仍然可能有很大的改进空间:我们希望避免幻觉、不安全或有害输出等问题,也希望改进那些技术上正确但还不够有帮助的回答。
基于偏好的学习的目标,是利用偏好判断进一步改善微调后 LLM 的表现。这既包括一般性能,也包括诚实性、有帮助性和无害性等具体品质。
与指令不同,偏好判断不要求人们知道某件事该如何完成。我们只需要对最终结果有意见即可。即使人们对输出如何产生知之甚少或完全不了解,也可以对广泛类型的输出表达偏好。偏好判断自然出现在许多场景中:给定一对选项,我们选择更喜欢的那个;给定大量备选项,我们可能选择一个(例如从菜单点餐);我们也可能给一组可能性排序(如前 10 名列表);最后,我们也可能在没有直接备选项时,单独接受或拒绝某个选项。
10.2.1 LLM 偏好数据
在基于偏好的对齐语境中,训练数据通常由一个提示 $x$ 和一组备选输出 $o$ 构成,这些输出是以 $x$ 为提示从 LLM 中采样得到的。当某个输出 $o_i$ 比另一个输出 $o_j$ 更受偏好时,我们记作 $(o_i \succ o_j \mid x)$。下面是改编自 HH-RLHF 数据集(Bai et al., 2022)的一些提示和偏好对。
Prompt: I've heard garlic is a great natural antibiotic. Does it help with colds?
Chosen: It can be helpful against colds, but may make you stink.
Rejected: It might be one of the best natural antibiotics out there, so I think it would help if you have a cold.
Prompt: What is malaria?
Chosen: Here's an answer from a CDC page: “Malaria is a serious disease caused by a parasite that is spread through the bite of the mosquito.”
Rejected: I don't know what malaria is.
这样的标注偏好对可以通过多种方式生成:
- 由受过训练的标注者直接标注一对采样输出。
- 标注者对 $N$ 个输出排序,并将其蒸馏成 $\binom{N}{2}$ 个偏好对。
- 标注者从 $N$ 个样本中选择一个单独的首选项,从而产生 $N-1$ 个偏好对。
用于 LLM 对齐的偏好数据通常来自三类来源:人工标注者判断、从在线资源中抽取的隐式偏好判断,以及使用 LLM 作为标注者得到的全合成偏好集合。
在通向 InstructGPT 模型的有影响力工作中(Stiennon et al., 2020),提示从客户对各类 OpenAI 应用的请求中采样得到。输出从早期预训练模型中采样,并以成对形式呈现给受过训练的标注者进行偏好标注。如右侧示意图所示,在后续工作中,标注者被要求对 4 个采样输出组成的集合从好到坏排序(每个排序列表产生 6 个偏好对)(Ouyang et al., 2022)。
直接人工标注之外的另一种选择,是利用包含隐式偏好判断的网络资源。Reddit(Ethayarajh et al., 2022)和 StackExchange(Lambert et al., 2023)等社交媒体网站是偏好数据的天然来源。在这种设置中,初始用户帖子作为提示,后续用户回复扮演采样输出的角色。随着时间推移,回复上累积的用户投票会形成对输出的排序,进而可以转化为偏好对,如图 10.6 所示。

接下来,我们还可以完全不使用人工标注者判断,而是直接从 LLM 获取偏好判断。例如,ULTRAFEEDBACK 数据集中的偏好判断,是先从多样化的 LLM 集合中为每个提示生成输出,然后再提示 GPT-4 对每个提示下的输出进行排序。
最后,离散偏好的另一种替代方案,是对系统输出的不同维度或方面给出标量判断。近年来,经常使用的方面包括有帮助性、诚实性、正确性、复杂度和冗长度(Bai et al., 2022; Wang et al., 2024)。在这种方法中,标注者(人类或 LLM)会沿各个维度用李克特量表(0–4)给输出打分。随后可以针对单一维度生成输出之间的偏好对,也可以由各方面分数的平均值诱导出总体偏好。由于标注者是孤立地评价模型输出,这就避免了对模型输出进行大量成对比较的成本。
10.2.2 偏好建模
为了有效使用离散偏好判断,第一步是对其进行概率建模。也就是说,我们希望从简单断言 $(o_i \succ o_j \mid x)$,转向知道 $P(o_i \succ o_j \mid x)$ 的值。正如前面见过的,这将使我们能够更好地推理偏好程度上的细微差异,也会帮助我们从偏好数据中学习模型。
先假设,当我们在两个条目之间表达偏好时,我们隐式地分别给每个条目赋予了一个分数或奖励。进一步假设这些分数是标量值 $z \in \mathbb{R}$。两个条目之间的偏好由哪个条目分数更高决定。
为了把偏好建模为概率,我们采用与二元逻辑回归相同的思路。给定两个输出 $o_i$ 和 $o_j$,以及关联分数 $z_i$ 和 $z_j$,$P(o_i \succ o_j \mid x)$ 是分数差的 logistic sigmoid:
这种方法称为 Bradley–Terry 模型(Bradley and Terry, 1952),它有许多优点:非常小的分数差会产生接近 0.5 的概率,反映条目之间偏好很弱或没有偏好;较大的差异会迅速接近 1 或 0;而 logistic sigmoid 的导数便于通过二元交叉熵损失进行学习。
这种特定形式的动机,与推导逻辑回归时使用的动机相同。分数差 $\delta=z_i-z_j$ 被视为可能结果赔率的对数(即 logit):
两边取指数并通过一些代数重排,可以得到现在熟悉的 logistic sigmoid:
这又回到了原来的表达式:
10.2.3 学习给偏好打分
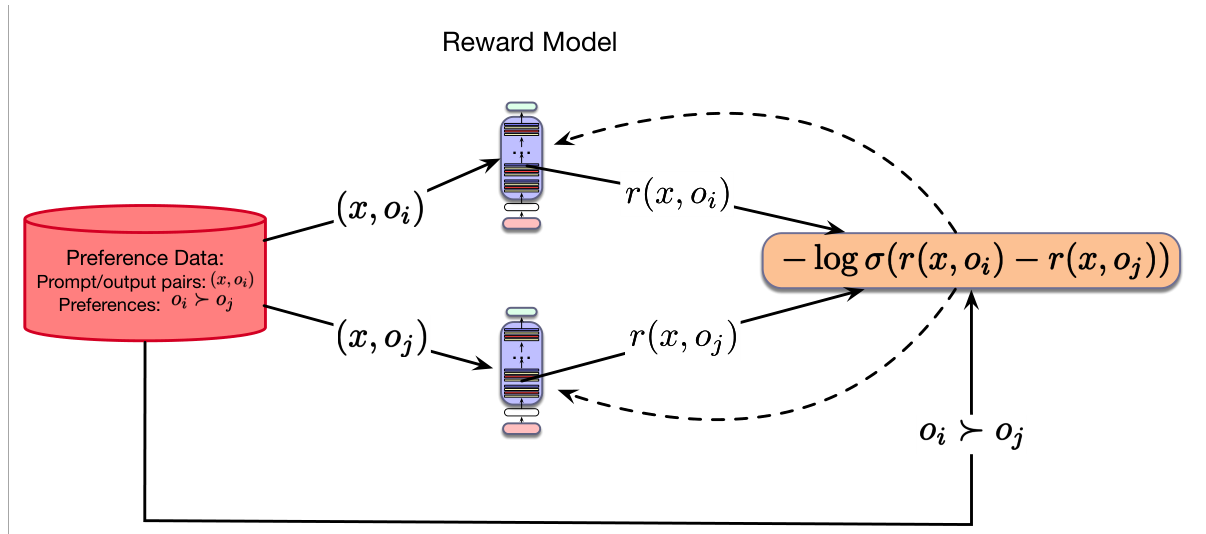
上述方法要求我们能够访问支撑给定偏好的分数 $z_i$,但我们并没有这些分数。我们拥有的是关于“提示/采样输出”对的偏好判断集合。我们将使用这些偏好数据和 Bradley–Terry 形式,学习一个函数 $r(x,o)$,它给提示/输出对分配一个标量奖励。也就是说,$r(x,o)$ 计算上文中的 $z$ 分数。
为了从偏好数据中学习 $r(x,o)$,我们将用梯度下降最小化二元交叉熵损失来训练模型。假设偏好数据告诉我们 $(o_i \succ o_j \mid x)$,那么 $P(o_i \succ o_j \mid x)=1$,相应地 $P(o_j \succ o_i \mid x)=0$。我们把一对输出中被偏好的输出(胜者)记为 $o_w$,失败者记为 $o_l$。基于此,对于一个提示 $x$ 的一对采样输出,使用 Bradley–Terry 模型得到的交叉熵损失为:
也就是说,该损失是模型对 $P(o_w \succ o_l \mid x)$ 的估计的负对数似然。在偏好训练集 $D$ 上的损失由如下期望给出:
要用这个损失学习奖励模型,我们可以使用任何能够接收文本输入并返回标量输出的回归模型。如图 10.7 所示,目前更常用的方法是从现有预训练 LLM 初始化奖励模型(Ziegler et al., 2019)。为了生成标量输出,我们移除最后一层的语言建模头,并用一个单一的全连接线性层替代。随后,我们使用 10.3 中的损失进行梯度下降,利用偏好训练数据学习给模型输出打分。
从偏好数据训练出的奖励模型,可以直接用于许多不涉及模型对齐的应用。例如,奖励模型已被用来从一组采样 LLM 回答中选择一个首选输出(best-of-$N$ 采样)(Cui et al., 2024)。它们也被用来选择指令微调期间使用的数据(Cao et al., 2024)。下一节将聚焦奖励模型如何用于基于偏好数据对齐 LLM。
10.3 通过基于偏好的学习实现 LLM 对齐
目前使用偏好数据对齐 LLM 的方法,基于强化学习(reinforcement learning, RL)框架(Sutton and Barto, 1998)。在 RL 设置中,模型基于策略选择动作序列,而策略会利用当前状态的特征。环境会为每个动作给出奖励;整个序列的奖励是组成该序列的各动作奖励的函数。RL 中的学习目标,是在某个训练期内最大化总体奖励。把 RL 应用于优化 LLM 时,我们采用如下框架:
- 动作对应于自回归生成过程中对词元的选择。
- 状态对应于当前解码步骤的上下文,也就是截至此刻已经生成的词元历史。
- 策略对应于由预训练 LLM 体现的概率语言模型。
- LLM 输出的奖励基于从偏好数据学习得到的奖励模型。
依照这个 RL 框架,我们把预训练 LLM 称为策略 $\pi$,并把与提示和输出相关联的偏好分数称为奖励 $r(x,o)$。有了这些,我们的目标就是训练一个策略 $\pi_\theta$,使其在由偏好数据导出的奖励模型下,最大化该策略输出的奖励。也就是说,我们希望经过偏好训练的 LLM 生成高奖励输出。可以把它表示为如下优化问题:
在这个形式中,我们从相关训练提示集合中选择提示 $x$,从给定策略中采样输出 $o$,并评估每个样本的奖励。训练样本上的平均奖励给出 $\pi_\theta$ 的期望奖励;目标是找到能够最大化该期望奖励的策略(模型)。
传统 RL 与其通常用于 LLM 对齐的方式之间有两个关键差异。第一,传统 RL 中的奖励信号来自环境,并反映动作结果的一个可观察事实(例如赢了游戏或没赢)。而在偏好学习中,学习得到的奖励模型只是一个真实奖励模型的有噪声替代。
第二个差异在于学习的起点。典型 RL 应用试图从零开始学习一个最优策略,也就是从随机初始化策略开始。这里,我们从已经处于高水平的模型开始:这些模型已经在大量数据上完成预训练,随后通过指令微调继续训练,之后才用偏好数据进一步改进。这里的重点不是彻底改变已有模型的行为,而是把它推向更受偏好的行为。
鉴于此,如果我们像 10.4 那样单纯优化奖励,预训练 LLM 通常会忘记它在预训练中学到的所有内容,因为它会转向从相对少量的偏好数据中追求高奖励。为避免这一点,需要在奖励函数中加入一项惩罚,惩罚偏离起点太远的模型。
该形式中的第二项 $D_{\mathrm{KL}}(\pi_\theta(o\mid x)\Vert\pi_{\mathrm{ref}}(o\mid x))$ 是 Kullback–Leibler(KL)散度。简言之,KL 散度衡量两个概率分布之间的距离。$\beta$ 项是一个超参数,用来调节这一惩罚项的影响。对于基于 LLM 的策略,KL 散度就是训练后策略与原始参考策略 $\pi_{\mathrm{ref}}$ 之比的对数。
在接下来的小节中,我们将基于这一优化框架讨论两种对齐 LLM 的学习方法。第一种方法使用偏好数据训练一个显式奖励模型,然后结合 RL 方法,基于 10.6 优化模型。第二种方法巧妙地重排 10.6 的闭式解,从而直接用已有偏好数据微调模型。
10.3.1 带偏好反馈的强化学习(PPO)
待补充。
10.3.2 直接偏好优化
直接偏好优化(Direct Preference Optimization, DPO)(Rafailov et al., 2023)使用基于梯度的学习,利用偏好数据优化候选 LLM,而不需要学习显式奖励模型,也不需要从正在更新的模型中采样。回忆 Bradley–Terry 模型:偏好对的概率是每个选项奖励差的 logistic sigmoid。在 RL 框架中,分数 $z$ 由关于提示及其对应输出的奖励模型提供。
DPO 从前面 10.6 引入的 KL 约束最大化开始;该式用奖励模型和参考模型 $\pi_{\mathrm{ref}}$ 表示最优策略 $\pi^*$。DPO 的关键洞见,是重写这个最大化问题的闭式解,用最优策略 $\pi^*$ 和参考策略 $\pi_{\mathrm{ref}}$ 表示奖励函数 $r(x,o)$。
其中 $Z(x)$ 是一个配分函数,即对给定提示 $x$ 下所有可能输出 $o$ 的求和。
这个配分函数中的求和使得直接使用它并不实际。然而,由于 Bradley–Terry 模型基于条目之间的奖励差,把 10.9 代入 10.7 后,配分函数会相互抵消,得到如下表达式。
经过这一变换后,DPO 用两个 LLM 策略来表示一个偏好对的似然,而不再用显式奖励模型。基于此,单个实例的交叉熵损失(负对数似然)为:
在训练集 $D$ 上的损失由如下期望给出:
该损失来自 sigmoid 的导数,并且与第 10.2.3 节中使用 Bradley–Terry 框架学习奖励模型时引入的损失直接类似。从操作上看,这个损失函数及其对应的基于梯度的更新,会提高首选选项的似然,降低非首选选项的似然。它同时通过 KL 惩罚,平衡“不要偏离 $\pi_{\mathrm{ref}}$ 太远”这一目标。$\beta$ 项是控制惩罚项的超参数;$\beta$ 值通常在 0.1 到 0.01 之间。
如图 10.9 所示,DPO 使用该损失对可用训练数据进行梯度下降,以优化策略 $\pi_\theta$;这个策略由一个已有的预训练、微调后的 LLM 初始化。
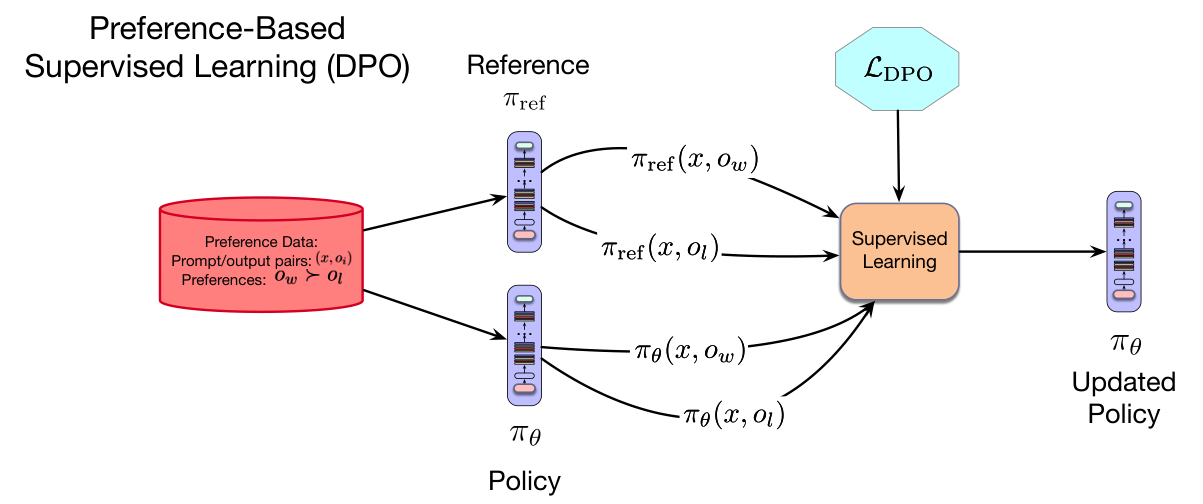
与前面 10.3.1 节描述的显式 RL 方法 PPO 相比,DPO 有几个优点:
- DPO 不需要训练显式奖励模型。
- DPO 直接从 $D$ 中包含的偏好学习,不需要从 $\pi_\theta$ 进行计算成本高昂的在线采样。
- DPO 在训练期间只需要维护 2 个 LLM,而 PPO 需要 4 个模型。
10.3.3 偏好对齐模型的评估
10.3.4 基于偏好学习的局限
10.4 测试时计算
到目前为止,我们已经见过大型语言模型的 3 个训练层次:预训练,此时模型学习预测词;以及两类后训练:指令微调,此时模型学习遵循指令;偏好对齐,此时模型学习偏好那些被人类偏好的提示续写。
不过,即使在这些步骤之后,在推理期间,也就是模型生成输出时,我们仍然可以做一些后训练计算。这类后训练任务称为测试时计算。这里我们聚焦一个代表性例子:思维链提示。
10.4.1 思维链提示
有许多技术可以利用提示来提升语言模型在众多任务上的表现。这里介绍其中一种,称为思维链提示。
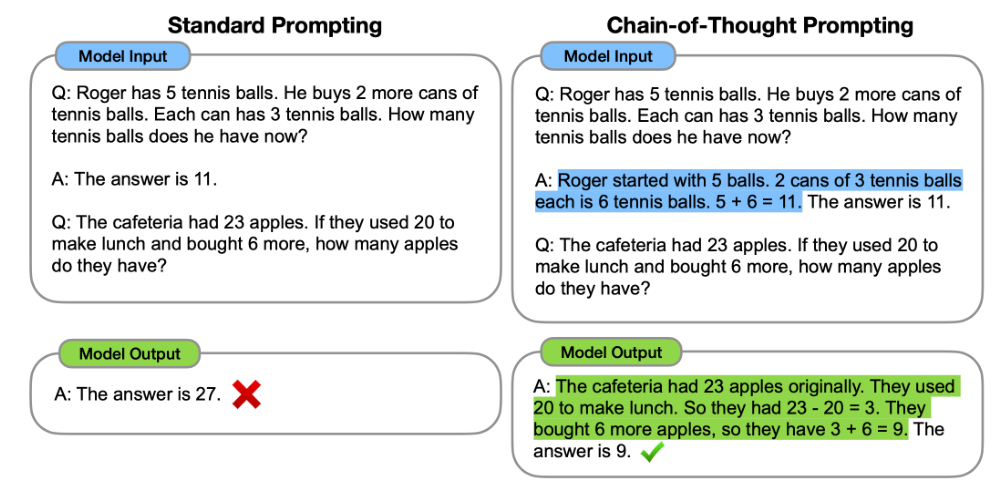
思维链提示的目标,是提升模型在困难推理任务上的表现,而这类任务往往是语言模型容易失败的任务。直觉是,人们解决这些任务时会把它们分解成多个步骤,因此我们希望提示中的语言能够鼓励语言模型以同样方式分解问题。
实际技术很简单:在少样本提示中的每个示范里,加入一些解释推理步骤的文本。目标是促使语言模型在解决当前问题时输出类似的推理步骤,并让这些推理步骤的输出促使系统生成正确答案。
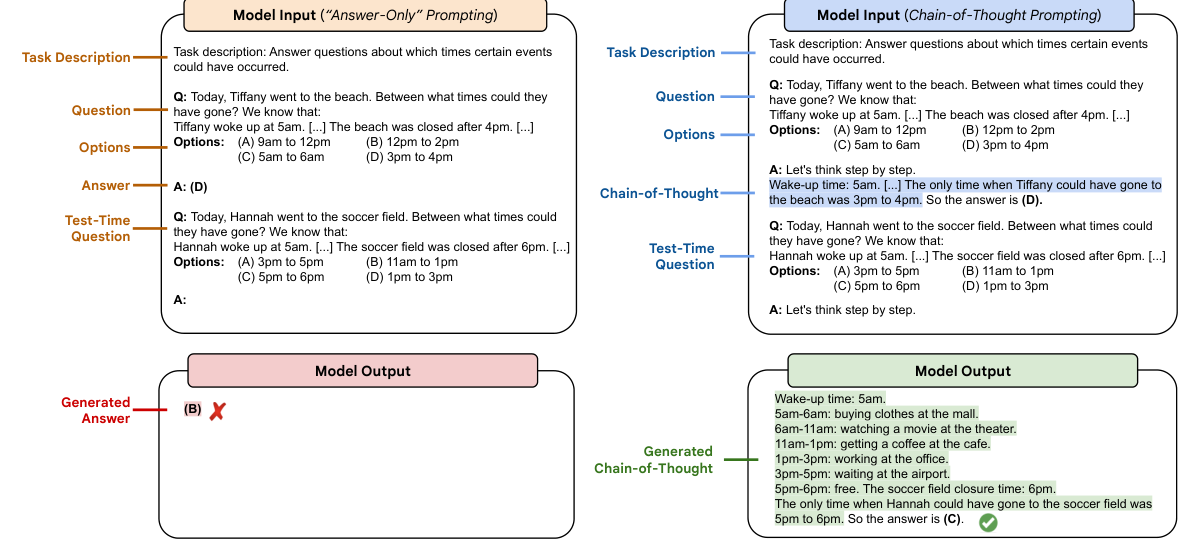
确实,许多研究发现,以这种方式给示范增加推理步骤,会让语言模型更有可能为困难推理任务给出正确答案(Wei et al., 2022; Suzgun et al., 2023b)。图 10.10 展示了一个例子,其中示范被加入了来自数学应用题领域的思维链文本(来自数学应用题数据集 GSM8K(Cobbe et al., 2021))。图 10.11 展示了来自 BIG-Bench-Hard 数据集的一个类似示例(Suzgun et al., 2023b)。
10.5 小结
本章探讨了提示大型语言模型遵循指令这一主题。下面是本章覆盖的一些要点:
- 简单提示可以把实际应用映射为 LLM 可以解决的问题,而不需要改变模型本身。
- 带标签示例(示范)可以通过少样本学习,为模型提供进一步指导。
- 思维链等方法可以用来创建提示,帮助语言模型处理复杂推理问题。
- 预训练语言模型可以通过模型对齐,被改变为以期望方式行动。
- 模型对齐的一种方法是指令微调:用下一个词预测的语言模型目标,在一组指令及其正确回答上微调模型。指令微调数据集通常通过改造用于问答或机器翻译等任务的标准 NLP 数据集来创建。
历史说明
原 PDF 在本章末尾仅列出“Historical Notes”标题,未包含正文内容。