11 信息检索与检索增强生成
“有两次有人问我:‘请问,巴贝奇先生,如果你把错误的数字放进机器,它会给出正确的答案吗?’……我实在无法理解,究竟是怎样的概念混乱才会引出这样的问题。”
Babbage (1864)
人们需要知道事情。所以几乎从计算机出现开始,我们就在向它们提问题。到 1961 年,已经有系统能够回答关于美国棒球统计的问题,比如 “How many games did the Yankees play in July?”(Green et al., 1961)。即便是 20 世纪 70 年代的虚构计算机,例如 Douglas Adams 在《银河系漫游指南》中创造的 Deep Thought,也会回答 “生命、宇宙以及一切的终极问题”。[注 1] 由于大量知识被编码在文本中,即使在 LLM 之前,也已经有系统在问答上达到人类水平:IBM 的 Watson 系统在 2011 年赢得电视智力竞赛节目 Jeopardy!,超过人类选手回答如下问题:
WILLIAM WILKINSON’S “AN ACCOUNT OF THE PRINCIPALITIES OF WALLACHIA AND MOLDOVIA” INSPIRED THIS AUTHOR’S MOST FAMOUS NOVEL[注 2]
因此,大型语言模型的一个重要功能自然就是满足人的信息需求。又因为很多信息都在线上,寻找能够满足需求的信息,与 Web 信息检索,即搜索引擎执行的任务,密切相关。事实上,随着现代搜索引擎与大型语言模型整合,两者之间的边界正在变得越来越模糊。
考虑一些简单的信息需求,例如事实型问题(factoid questions),它们可以由短文本表达的事实来满足:
(11.1) Where is the Louvre Museum located?
(11.2) Where does the energy in a nuclear explosion come from?
(11.3) How to get a script l in latex?
要让 LLM 回答这些问题,我们可以直接提示它。例如,一个经过问答指令微调的预训练 LLM(指令微调见第 10 章)可以直接回答下面的问题:
Where is the Louvre Museum located?
也就是说,模型在给定这个前缀的条件下进行条件生成,并把响应作为答案。这之所以可行,是因为大型语言模型在预训练数据中处理过大量事实,包括卢浮宫的位置,并把这些信息编码在参数中。这类事实知识似乎存储在 transformer 模型非常大的前馈层连接中(Geva et al., 2021; Meng et al., 2022)。
直接提示 LLM 对很多生成任务很有用,包括涉及事实的任务。但知识存储在 LLM 前馈权重中这一点,也使得直接提示作为正确生成事实文本或答案的方法时,会带来若干问题。
第一个也是最主要的问题是:LLM 在生成事实答案或其他事实文本时经常出错。大型语言模型会幻觉(hallucinate)。幻觉是指响应不忠实于世界事实。也就是说,当被问到问题时,大型语言模型有时会编造听起来合理的答案。例如,Dahl et al. (2024) 发现,在法律领域的问题上(比如关于特定法律案例的问题),大型语言模型的幻觉率从 69% 到 88% 不等。即使正确事实已经存储在参数中,LLM 有时也会给出错误事实响应;这似乎是因为前馈层未能回忆起参数中存储的知识(Jiang et al., 2024)。
而且我们也不总能判断语言模型何时在幻觉,部分原因是 LLM 并没有良好校准(calibrated)。在一个校准良好的系统中,系统对自己答案正确性的置信度,与答案真正正确的概率高度相关。因此,如果一个校准良好的系统错了,至少它可能会在回答中保留余地,或者告诉我们去核查另一个来源。但由于语言模型通常没有良好校准,它们经常会以完全确定的语气给出非常错误的答案(Zhou et al., 2024)。
用简单提示方法满足用户信息需求的第二个问题是:让大型语言模型从其预训练参数中回答,不允许我们询问专有数据。我们希望用语言模型帮助用户处理关于专有数据的信息需求,例如个人电子邮件。或者在医疗应用中,我们可能希望把语言模型应用于病历。公司内部文档中可能包含客服或内部使用所需的答案。律师事务所也需要围绕专有文档进行法律证据开示相关的提问。这些数据(希望如此)都不在大型语言模型预训练所用的大规模 Web 语料中。
用大型语言模型回答知识问题的最后一个问题是:它们是静态的;它们只在某个特定时间预训练过一次。这意味着 LLM 无法谈论快速变化的信息(比如上周发生的事情),因为模型发布之后的最新信息不会包含在它们的参数中。
解决这些简单提示问题的一种方法,是给语言模型提供外部知识源,例如医疗或法律记录、个人邮件、企业文档等专有文本,并在回答问题时使用这些文档。这种方法称为检索增强生成(retrieval-augmented generation, RAG),也是本章将重点讨论的方法。在 RAG 中,我们使用信息检索(information retrieval, IR)技术检索可能包含有助于回答问题的信息的文档。随后,我们让大型语言模型在给定这些文档的条件下生成答案。
把答案建立在检索出的文档之上,可以解决直接提示回答问题时的一些问题。首先,它有助于确保答案植根于某个经过整理的数据集中的事实。系统还可以把答案与其来源段落或文档的上下文一同呈现给用户。这些信息可以帮助用户相信答案的准确性(或者在答案错误时帮助他们发现问题)。这些检索技术也可以用于任何我们需要的专有数据,例如法律或医疗数据。
我们将从信息检索开始,也就是给定表达用户信息需求的查询,从文档集合中选择最相关文档的任务。我们会看到基于稀疏 tf-idf 向量余弦的经典方法,也会看到现代神经稠密检索器,它们改用 BERT 或其他语言模型以神经方式表示查询和文档。随后,我们会介绍检索增强生成范式。
最后,我们会讨论各种包含问题与答案的数据集,这些数据集可用于指令微调中的 LLM 微调,也可作为评测基准。
11.1 信息检索
信息检索(Information retrieval, IR)是一个领域名称,涵盖基于用户信息需求检索各种媒体的任务。由此得到的 IR 系统通常称为搜索引擎。本节的目标,是给出足够的 IR 概览,以便理解它如何应用于大型语言模型满足用户信息需求。对信息检索本身更感兴趣的读者,可以参见本章末尾的历史注释。
我们考虑的 IR 任务称为即席检索(ad hoc retrieval):用户向检索系统提出一个查询,系统随后从某个集合中返回一个有序的文档集合。文档指系统建立索引并检索的任何文本单位(网页、科学论文、新闻文章,甚至段落这样更短的篇章)。集合指用于满足用户请求的一组文档。集合可以表示整个 Web,此时我们做的是Web 搜索;也可以是较小的企业资料库,甚至是某个人使用的一组文档。项(term)指集合中的词,也可能包括短语。最后,查询表示用户用一组项表达的信息需求。
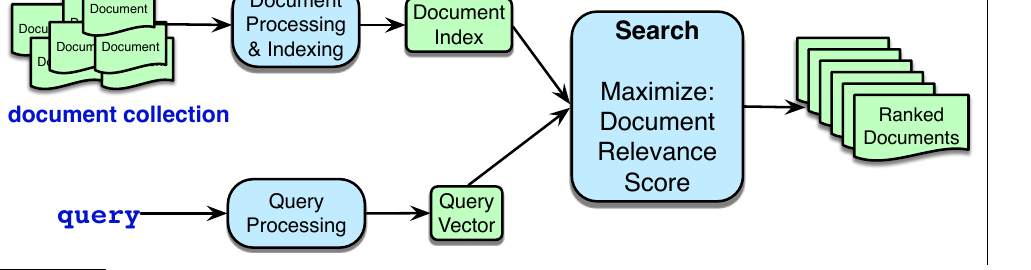
图 11.1 展示了即席检索引擎的高层架构。该图抽象了两类 IR 系统,它们基于表示查询和文档的两类向量:稀疏向量和稠密向量。在稀疏检索中,我们用计数向量表示文档和查询,并用 tf-idf 或 BM25 加权。在稠密检索中,我们用由语言模型(编码器模型或解码器模型)计算得到的嵌入来表示文档和查询。本节余下部分讨论稀疏检索,第 11.3 节再转向稠密检索。
11.1.1 把文档表示为向量
在信息检索的向量空间模型(vector space model; Salton, 1971)中,文档表示为它所包含词的计数向量。
我们有时称这类模型为词袋模型(bag-of-words model)。图 11.2 展示了它的直觉:我们把文本文档表示成一个词袋,也就是一个忽略词位置、只保留词在文档中频率的无序词集合。在图中的例子里,我们不表示 “It manages to be whimsical and romantic” 这类短语中的词序,而只记录词 it 在整个摘录中出现了 5 次,词 love、recommend 和 movie 各出现一次,等等。
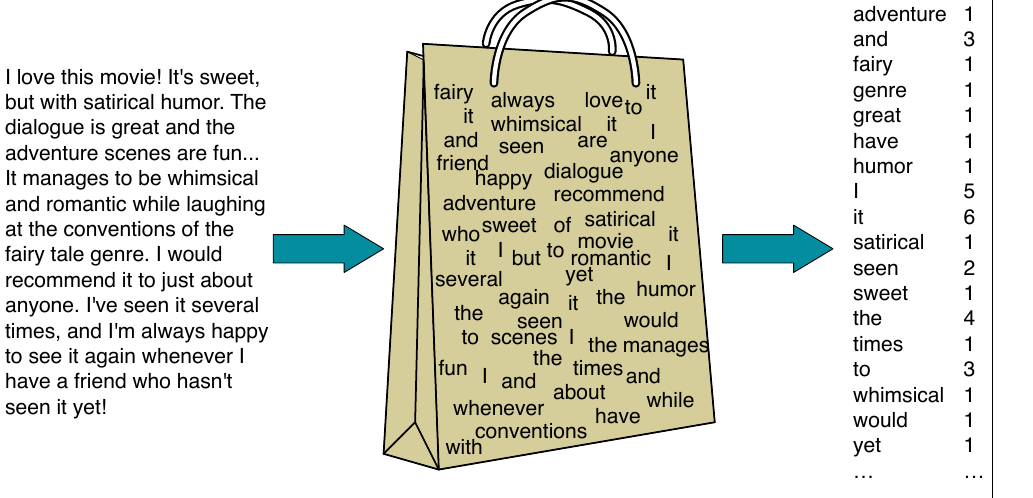
因此,我们可以把图 11.2 中的文档想象成向量 $[1\ 3\ 1\ 1\ 1\ 1\ 1\ 5\ 6\ 1\ 2\ 1\ 4\ 1\ 3\ 1\ 1\ 1]$(如果我们只考虑这 18 个维度,而忽略英语中的所有其他词)。
更一般地,我们可以把一组文档表示为项-文档矩阵(term-document matrix),其中每一行表示词汇表中的一个词,每一列表示某个文档集合中的一个文档。图 11.3 展示了一个项-文档矩阵的小片段,其中显示了四个词在莎士比亚四部戏剧中出现的次数。矩阵中的每个单元表示特定词(由行定义)在特定文档(由列定义)中出现的次数。因此,fool 在 Twelfth Night 中出现了 58 次。

一个文档表示为一个计数向量,也就是图 11.4 中的一列。在图 11.4 的例子里,为了适合页面,我们把文档向量维度选为 4;在真实的项-文档矩阵中,文档向量的维度会是 $|V|$,即词汇表大小。这些向量的第一个维度都对应词 battle 出现的次数,我们可以逐维比较,例如注意到 As You Like It 和 Twelfth Night 在第一个维度上的值相似(分别为 1 和 0)。

由于 4 维空间难以可视化,图 11.5 展示了四个文档向量在二维空间中的可视化;我们任意选择了对应词 battle 和 fool 的两个维度。
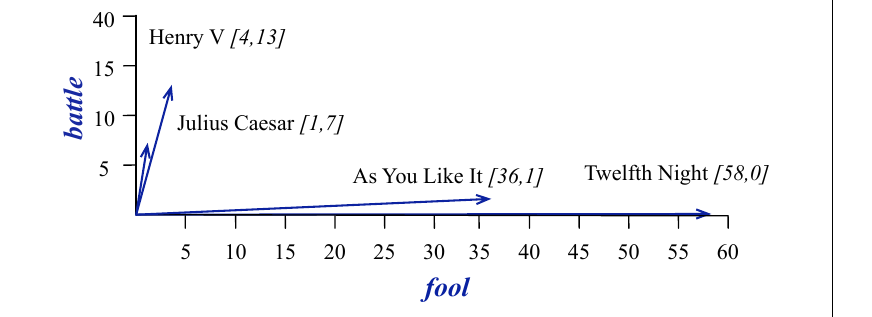
相似的两个文档往往有相似的词;如果两个文档有相似的词,它们的列向量也往往相似。喜剧 As You Like It $[1,114,36,20]$ 和 Twelfth Night $[0,80,58,15]$ 的向量看起来彼此更相似(有更多 fools 和 wit,而不是 battles),不像 Julius Caesar $[7,62,1,2]$ 或 Henry V $[13,89,4,3]$。
11.1.2 项加权:tf-idf 与 BM25
事实上,在 IR 中,我们不会直接使用原始词计数,例如 As You Like It 的 $[1\ 114\ 36\ 20]$,或图 11.2 中文档的 $[1\ 3\ 1\ 1\ 1\ 1\ 1\ 5\ 6\ 1\ 2\ 1\ 4\ 1\ 3\ 1\ 1\ 1]$。相反,我们为每个文档词计算一个项权重。常见的项加权方案有两种:tf-idf,以及 tf-idf 的一个变体 BM25。
Tf-idf(这里的 “-” 是连字符,不是减号)是两个项的乘积:词频 tf 和逆文档频率 idf。
词频项告诉我们一个词有多频繁;在文档中出现越多的词,越可能对文档内容有信息量。我们通常使用词频的 $\log_{10}$,而不是原始计数。直觉是,一个词在文档中出现 100 次,并不意味着这个词与文档意义相关的可能性变为 100 倍。我们还需要对 0 计数做特殊处理,因为不能取 $\log 0$。[注 3] 因此,如果把 $\mathrm{count}(t,d)$ 定义为项 $t$ 在文档 $d$ 中的原始计数,那么项 $t$ 在文档 $d$ 中的 tf,即 $tf_{t,d}$,为:
如果使用对数加权,在文档中出现 0 次的项有 $tf=0$,出现 1 次的项有 $tf=1+\log_{10}(1)=1$,出现 10 次的项有 $tf=2$,出现 100 次有 $tf=3$,出现 1000 次有 $tf=4$,依此类推。
项 $t$ 的文档频率 $df_t$ 是它出现于多少篇文档中的数量。只出现在少数文档中的项有助于把这些文档与集合中其余文档区分开;遍布整个集合的项则不那么有帮助。逆文档频率(inverse document frequency, idf)项权重(Sparck Jones, 1972)定义为:
其中 $N$ 是集合中的文档总数,$df_t$ 是项 $t$ 出现于其中的文档数量。一个项出现的文档越少,其权重越高;出现在每篇文档中的项会得到最低权重 0。
下面是莎士比亚戏剧语料中一些词的 idf 值。从只出现在一部戏剧中、信息量极高的词(如 Romeo),到只出现在少数戏剧中的词(如 salad 或 Falstaff),再到很常见的词(如 fool),以及完全没有区分力、出现在全部 37 部戏剧中的词(如 good 或 sweet):[注 4]
| Word | df | idf |
|---|---|---|
| Romeo | 1 | 1.57 |
| salad | 2 | 1.27 |
| Falstaff | 4 | 0.967 |
| forest | 12 | 0.489 |
| battle | 21 | 0.246 |
| wit | 34 | 0.037 |
| fool | 36 | 0.012 |
| good | 37 | 0 |
| sweet | 37 | 0 |
词 $t$ 在文档 $d$ 中的 tf-idf 值就是词频 $tf_{t,d}$ 与 IDF 的乘积:
11.1.3 文档评分
一旦把每个文档和查询表示为加权向量,我们就需要为每个文档评分。我们的目标是度量文档与用户信息需求的相关性,而该需求由查询表达。在经典 tf-idf 模型中,我们通过度量文档向量与查询向量在向量空间中的几何相似度来估计文档相关性。也就是说,我们做出一个简化假设:与查询有相似词的文档,更可能与用户相关。
我们使用第 5 章介绍过的余弦相似度函数,用文档向量 $d$ 与查询向量 $q$ 的余弦来给文档 $d$ 打分:
也可以把余弦计算理解为单位向量的点积:先通过除以长度,把查询向量和文档向量都归一化为单位向量,然后取点积:
用 tf-idf 值展开式 (11.8),并把点积写成乘积之和:
下面使用式 (11.9),通过一个小查询与 4 个纳米文档组成的集合来走一遍例子,计算 tf-idf 值并观察文档排序。我们假设下面查询和文档中的所有词都已经小写化并去除了标点:
Query: sweet love
Doc 1: Sweet sweet nurse! Love?
Doc 2: Sweet sorrow
Doc 3: How sweet is love?
Doc 4: Nurse!
图 11.6 展示了查询与文档 1、查询与文档 2 之间的 tf-idf 余弦计算。余弦是 tf-idf 值的归一化点积,因此为了归一化,我们需要使用式 (11.4)、式 (11.5)、式 (11.6) 和式 (11.9) 计算查询以及前两个文档的向量长度 $|q|$、$|d_1|$ 和 $|d_2|$(文档 3 和 4 也需要计算,留作读者练习)。两个向量的点积是在各个维度上,把两个 tf-idf 向量在该维度的值相乘再求和。只有当查询和文档在同一个维度上都有非零值时,这个乘积才非零。因此在这个例子中,查询只有 sweet 和 love 有非零值,点积就是每个向量在这些元素上乘积的和。
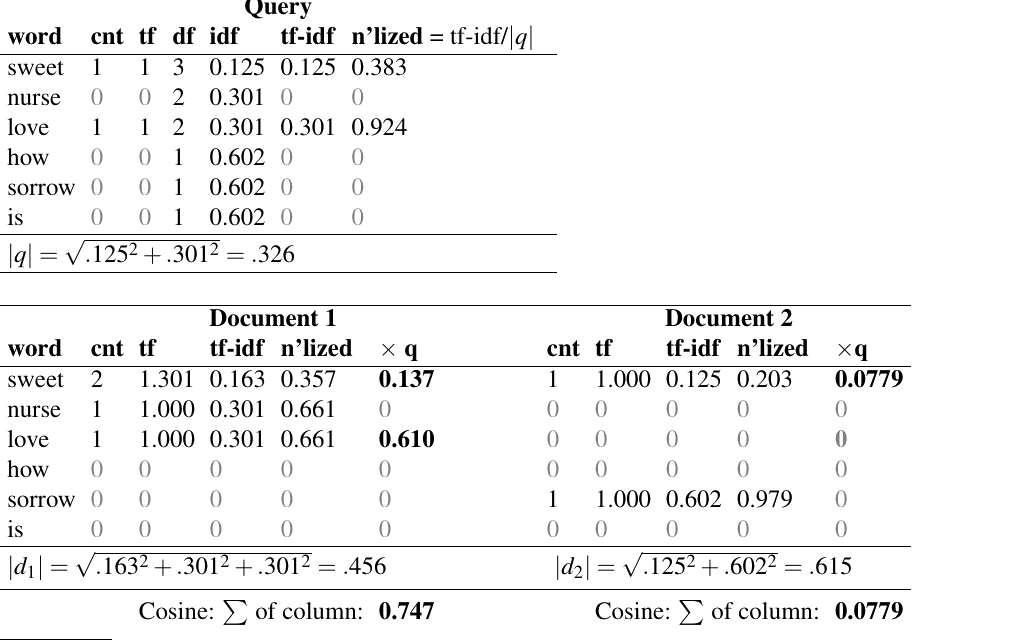
文档 1 与查询的余弦(0.747)高于文档 2 与查询的余弦(0.0779),因此 tf-idf 余弦模型会把文档 1 排在文档 2 前面。这个排序符合向量空间模型的直觉,因为文档 1 含有查询中的两个项,而且包含两个 sweet;文档 2 则缺少其中一个项。文档 3 和 4 的计算留作读者练习。
实践中,式 (11.9) 有许多变体和近似。例如,我们可能会选择移除某些项来简化处理。为此,先把式 (11.9) 中的 tf-idf 公式展开,显式写出式 (11.6) 中的 tf 和 idf:
例如,在一个常见的 tf-idf 余弦变体中,我们去掉文档侧的 idf 项。消去第二份 idf 项(因为查询侧已经计算了同一个项)有时会带来更好的性能:
其他 tf-idf 变体会消去各种其他项。
tf-idf 家族中一个稍复杂的变体是 BM25 加权方案(有时也称为 Okapi BM25,因为它是在 Okapi IR 系统中提出的;Robertson et al., 1995)。BM25 增加了两个参数:$k$,用于调节词频和 IDF 之间的平衡;以及 $b$,用于控制文档长度归一化的重要性。给定查询 $q$ 时,文档 $d$ 的 BM25 分数为:
其中 $|d_{avg}|$ 是平均文档长度。当 $k=0$ 时,BM25 退化为不使用词频,只对查询中的项做二值选择(加上 idf)。较大的 $k$ 会导致使用原始词频(加上 idf)。$b$ 的取值范围从 1(按文档长度缩放)到 0(不做长度缩放)。Manning et al. (2008) 建议的合理值是 $k=[1.2,2]$、$b=0.75$。Kamphuis et al. (2020) 对 BM25 的许多细小变体做了有用总结。
停用词
过去通常会在表示查询和文档之前,从二者中移除高频词。要移除的这类高频词列表称为停用词表(stop list)。直觉是,高频项(通常是 the、a、to 这样的功能词)语义权重很小,可能无助于检索,并且移除它们也有助于缩小下面将描述的倒排索引文件。使用停用词表的缺点是,它会使包含停用词的短语难以搜索。例如,常见停用词表会把短语 to be or not to be 缩减为 not。在现代 IR 系统中,停用词表的使用已经少得多,部分原因是效率提高了,部分原因是 IDF 加权已经处理了许多此类功能,即降低出现在每篇文档中的功能词的权重。尽管如此,停用词移除在各种 NLP 任务中偶尔仍有用,因此值得记住。
11.1.4 高效寻找文档:倒排索引
为了计算分数,我们需要高效地找到包含查询词的文档。(任何不包含查询项的文档都会得到 0 分,可以忽略。)IR 中的基本搜索问题就是找到包含项 $q\in Q$ 的所有文档 $d\in C$。
完成这项任务的数据结构是倒排索引(inverted index)。我们使用倒排索引提高搜索效率,也可以方便地存储文档频率、每个项在每个文档中的计数等有用信息。
倒排索引在给定查询项时,给出包含该项的文档列表。它由两部分组成:词典和倒排记录(postings)。词典是项的列表(设计为可高效访问),每个项指向该项对应的倒排记录表。倒排记录表是与每个项关联的文档 ID 列表,其中也可以包含词频,甚至项在文档中的确切位置。词典还可以存储每个项的文档频率。例如,对于上面的 4 个示例文档,一个简单倒排索引可以如下表示;每个词后的 {} 中是其文档频率,指向的倒排记录表中包含文档 ID 和 [] 中的项计数:
how {1} → 3 [1]
is {1} → 3 [1]
love {2} → 1 [1] → 3 [1]
nurse {2} → 1 [1] → 4 [1]
sorrow {1} → 2 [1]
sweet {3} → 1 [2] → 2 [1] → 3 [1]给定查询中的项列表,我们就可以非常高效地得到所有候选文档列表,以及计算所需 tf-idf 分数所需的信息。
11.2 信息检索系统的评估
我们使用一直在用的 precision 和 recall 指标来度量排序检索系统的性能。我们假设 IR 系统返回的每个文档要么与我们的目的相关,要么不相关。Precision 是返回文档中相关文档所占的比例,recall 是所有相关文档中被返回的比例。更形式化地,假设系统响应某个信息请求返回 $T$ 个排序文档,其中子集 $R$ 是相关文档,与其不相交的子集 $N$ 是其余不相关文档,而整个集合中有 $U$ 个文档与该请求相关。则 precision 和 recall 定义为:
遗憾的是,这些指标不能充分度量一个对返回文档进行排序的系统。如果我们要比较两个排序检索系统的性能,就需要一个更偏好把相关文档排得更靠前的指标。我们需要调整 precision 和 recall,使它们能够刻画系统把相关文档放在排序前列的能力。
来看一个例子。假设图 11.7 中的表给出一个特定查询下,沿着一组排序文档向下查看时计算的逐排名 precision 和 recall 值;precision 是在给定排名处已经看到的相关文档比例,recall 是在同一排名处已经找到的相关文档比例。本例中的 recall 基于这样一个假设:整个集合中有 9 个文档与该查询相关。
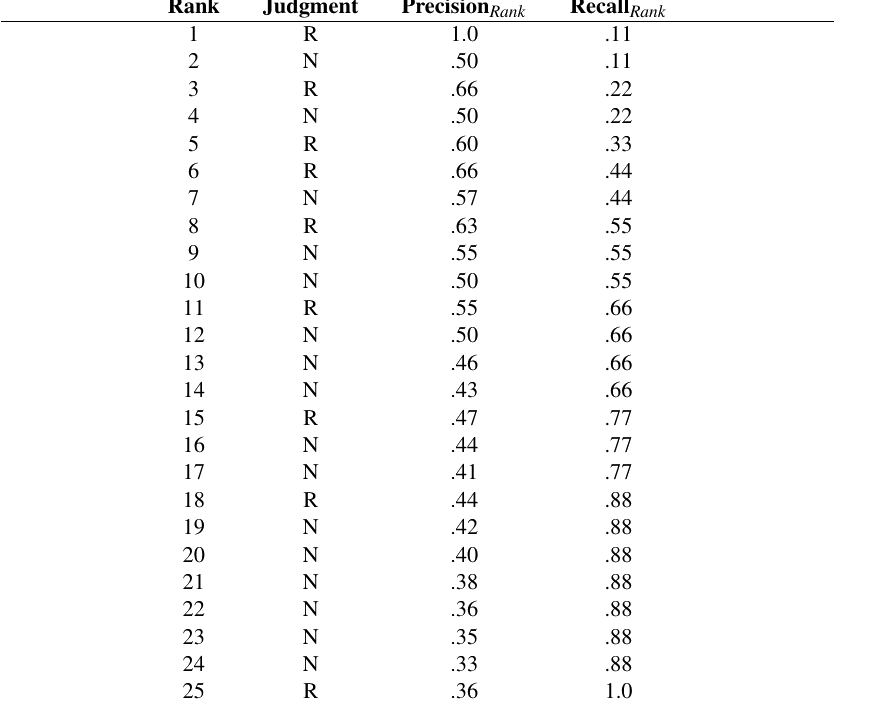
注意,recall 是非递减的;遇到相关文档时,recall 增加;遇到不相关文档时,recall 保持不变。相比之下,precision 会上下跳动:遇到相关文档时增加,否则降低。可视化 precision 和 recall 最常见的方法,是把 precision 对 recall 作图,得到精确率-召回率曲线(precision-recall curve),如图 11.8 所示。
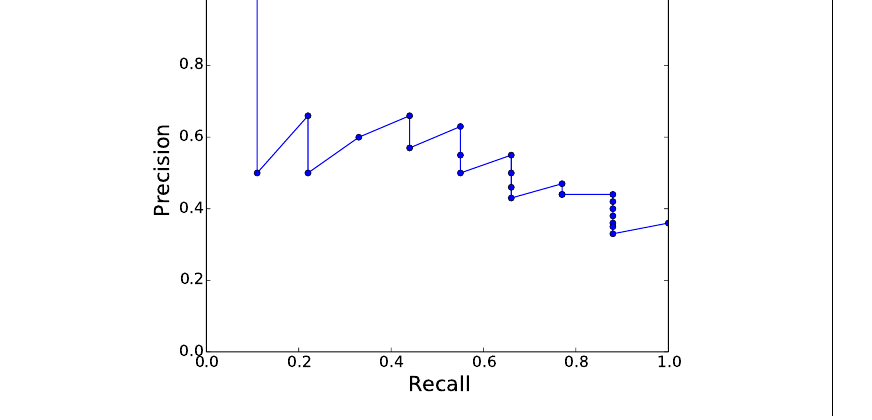
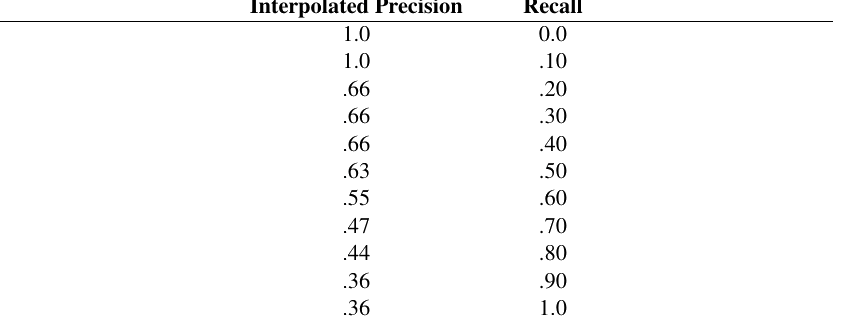
图 11.8 展示的是单个查询的值。但我们还需要以一种能比较系统的方式,把所有查询的值合并起来。方法之一是在 11 个固定 recall 水平上(从 0 到 100,步长为 10)绘制平均 precision 值。由于实际数据点不太可能恰好落在这些水平上,我们使用已有数据点为这 11 个 recall 值计算插值精确率。做法是选择在待计算 recall 水平或其以上任意 recall 水平达到的最大 precision 值。换言之:
这种插值方案不仅让我们可以对一组查询的性能求平均,也能平滑原始数据中不规则的 precision 值。它通过把更高 recall 水平上达到的最大 precision 值赋给当前测量点,为系统提供 “有利解释”。图 11.9 和图 11.10 展示了例子中得到的插值数据点。
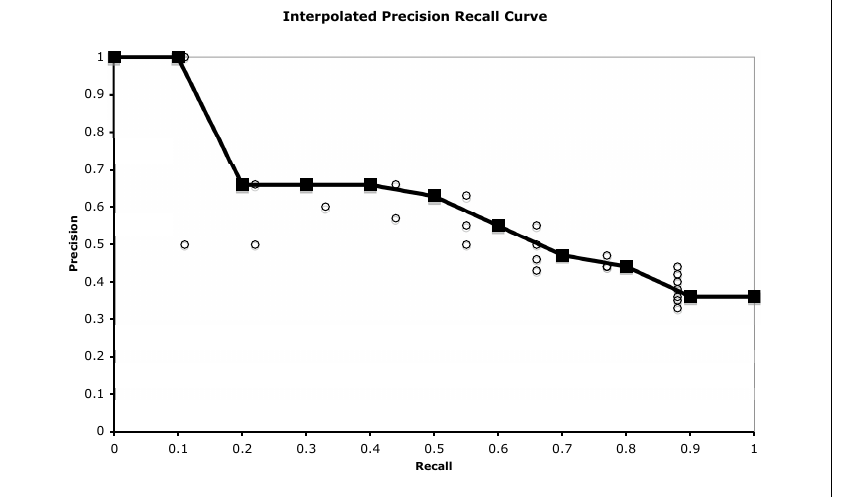
给定图 11.10 这样的曲线,我们可以通过比较曲线来比较两个系统或方法。显然,在所有 recall 值上 precision 更高的曲线更好。不过,这些曲线也能让我们洞察系统的整体行为。曲线左侧 precision 更高的系统可能更偏向 precision 而不是 recall;更面向 recall 的系统则会在较高 recall 水平(右侧)更高。
第二种评估排序检索的方法是平均精度均值(mean average precision, MAP),它提供一个可用于比较竞争系统或方法的单一指标。在这种方法中,我们同样沿着排序项目列表向下查看,但只在遇到相关项目的位置记录 precision(例如图 11.7 中排名 1、3、5、6 处,而不是 2 或 4 处)。对于单个查询,我们对返回集合中的这些 precision 测量值求平均(直到某个固定截断点)。更形式化地,如果假设 $R_r$ 是排名 $r$ 或其以上的相关文档集合,则单个查询的平均精度(average precision, AP)为:
其中 $\mathrm{Precision}_r(d)$ 是在文档 $d$ 被找到的排名处测量的 precision。对于一组查询 $Q$,我们再对这些平均值求平均,得到最终的 MAP:
图 11.7 中单个查询的 MAP(因此也就是 AP)为 0.6。
11.3 使用稠密向量的信息检索
经典的 tf-idf 或 BM25 IR 算法长期以来被认为有一个概念性缺陷:它们只有在查询和文档之间存在精确词重叠时才有效。换言之,提出查询(或提问)的用户需要准确猜到答案作者可能使用了哪些词,这个问题称为词汇不匹配问题(vocabulary mismatch problem; Furnas et al., 1987)。
这个问题的解决思路,是使用能够处理同义关系的方法:不用(稀疏的)词计数向量,而使用(稠密的)嵌入。这个想法上世纪就以潜在语义索引(Latent Semantic Indexing; Deerwester et al., 1990)的名称首次用于检索,但在现代通常通过 BERT 这样的编码器来实现。
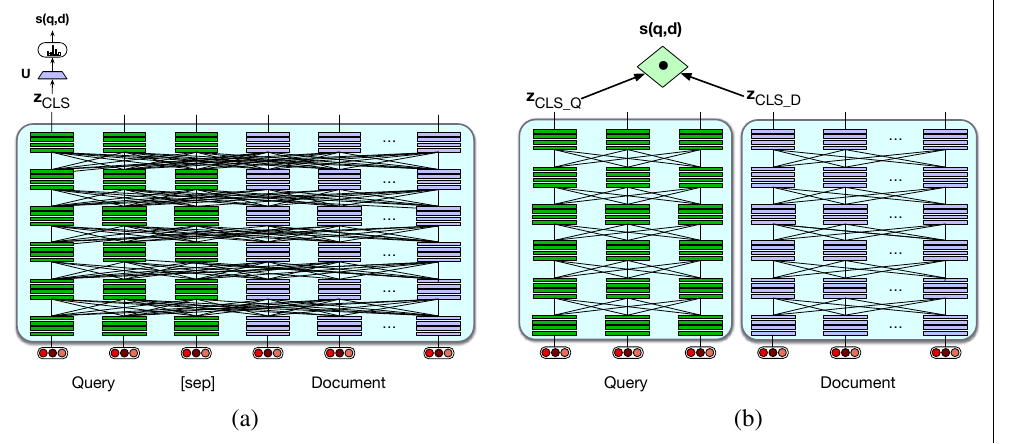
最强大的方法,是把查询和文档同时送入一个编码器,让 transformer 自注意力能看到查询和文档的所有词元,从而构建一个同时敏感于查询和文档意义的表示。然后,可以在 [CLS] 词元上方放一个线性层,预测查询/文档二元组的相似度分数:
这个架构见图 11.11a。通常,检索步骤并不在整个文档上完成。相反,文档会被拆成较小的段落,例如不重叠的固定长度块(比如 100 个词元),检索器编码并检索这些段落,而不是整篇文档。查询和文档必须放入 BERT 的 512 词元窗口中,例如把查询截断到 64 个词元,并在必要时截断文档,使文档、查询、[CLS] 和 [SEP] 一起适配 512 个词元。随后,BERT 系统以及线性层 $U$ 可以通过收集相关和不相关段落组成的调优数据集,针对相关性任务进行微调。
图 11.11a 中完整 BERT 架构的问题是计算和时间成本高。使用这种架构时,每当得到一个查询,我们都必须把整个集合中的每一篇文档与新查询一起通过 BERT 编码器。这种巨大的资源消耗在真实场景中不可行。
计算光谱的另一端,是一种高效得多的架构:双编码器(bi-encoder)。在这种架构中,我们使用两个独立的编码器模型,一个编码查询,一个编码文档;集合中的文档只需编码一次。我们预先编码每篇文档,并存储所有编码后的文档向量。当查询到来时,只编码这个查询,然后使用查询向量与预计算文档向量之间的点积作为每个候选文档的分数(图 11.11b)。例如,如果使用 BERT,我们会有两个编码器 $\mathrm{BERT}_Q$ 和 $\mathrm{BERT}_D$,并可以把查询和文档分别表示为各自编码器的 [CLS] 词元(Karpukhin et al., 2020):
双编码器比完整查询/文档编码器便宜得多,但也不那么准确,因为它的相关性判断无法充分利用查询中所有词元与文档中所有词元之间的意义交互。
在完整编码器和双编码器之间,还有许多中间方法。一种中间方案是先使用更便宜的方法(如 BM25)作为第一轮文档相关性排序,取排名前 $N$ 的文档,再使用完整 BERT 打分这样的昂贵方法只对前 $N$ 个文档重排序,而不是对整个集合重排序。
另一种中间方法是 Khattab and Zaharia (2020) 和 Khattab et al. (2021) 的 ColBERT 方法,如图 11.12 所示。该方法分别编码查询和文档,但不是把整个查询或文档编码为一个向量,而是分别把它们编码为每个词元的上下文表示。为提高效率,每个文档词的这些 BERT 表示可以预先存储。查询 $q$ 与文档 $d$ 之间的相关性分数,是查询中词元和文档中词元之间最大相似度(MaxSim)算子的总和。本质上,对于 $q$ 中的每个词元,ColBERT 找到 $d$ 中上下文最相似的词元,然后把这些相似度求和。相关文档会具有与查询在上下文上非常相似的词元。
更形式化地,问题 $q$ 被分词为 $[q_1,\ldots,q_n]$,前面加上 [CLS] 和特殊的 [Q] 词元,截断到 $N=32$ 个词元(如果更短,则用 [MASK] 词元填充),并通过 BERT 得到输出向量 $\mathbf{q}=[\mathbf{q}_1,\ldots,\mathbf{q}_N]$。包含词元 $[d_1,\ldots,d_m]$ 的段落 $d$ 以类似方式处理,包括 [CLS] 和特殊 [D] 词元。为了控制输出维度、保持向量较小以便高效存储,会在 $\mathbf{d}$ 和 $\mathbf{q}$ 上方应用一个线性层;向量随后缩放到单位长度,得到最终向量序列 $E_q$(长度 $N$)和 $E_d$(长度 $m$)。ColBERT 的打分机制为:
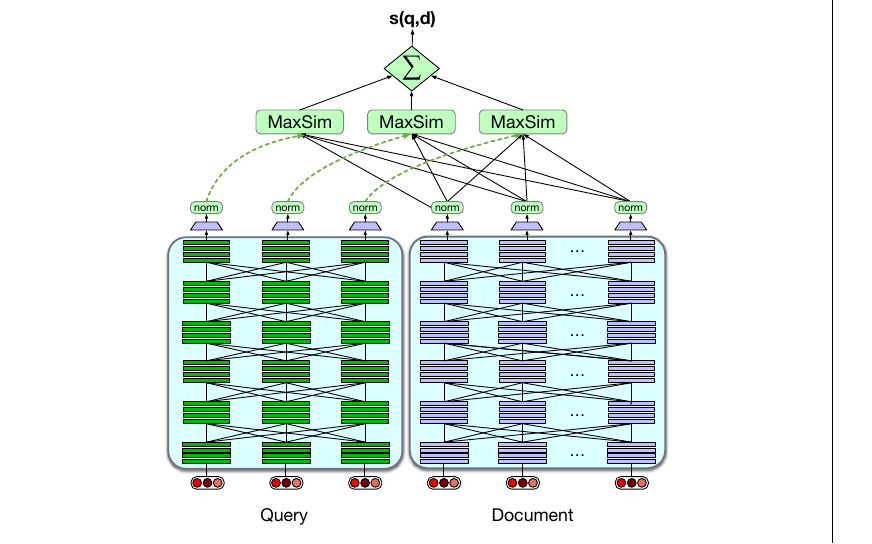
[CLS] 和 [Q:] 词元,文档前会加上 [CLS] 和 [D:] 词元。)图改编自 Khattab and Zaharia (2020)。虽然这个交互机制没有可调参数,ColBERT 架构本身仍需要端到端训练,以微调 BERT 编码器,并从头训练线性层(以及特殊的 [Q] 和 [D] 嵌入)。它在三元组 $\langle q,d^+,d^-\rangle$ 上训练,其中 $q$ 是查询,$d^+$ 是正文档,$d^-$ 是负文档;模型使用式 (11.19) 为每个文档生成分数,并用交叉熵损失优化模型参数。
所有监督算法(例如 ColBERT,或用于重排序的 BERT 全交互版本)都需要查询及相关、不相关段落或文档(正例和负例)形式的训练数据。可以通过多种半监督方式获得标签;一些数据集(如第 11.5 节的 MS MARCO Ranking)包含金标准正例。负例可以从某个现有 IR 系统的前 1000 个结果中随机采样。如果数据集没有标注的正例,可以使用 relevance-guided supervision 这样的迭代方法(Khattab et al., 2021),它依赖于许多数据集包含短答案字符串这一事实。在这种方法中,先用现有 IR 系统收集包含短答案字符串的样例(取前若干个作为正例)或不包含短答案字符串的样例(取前若干个作为负例),用它们训练新的检索器,然后迭代这个过程。
效率是一个重要问题,因为每个可能的文档都必须按其与查询的相似度排序。对于稀疏词计数向量,倒排索引可以非常高效地完成这件事。对于稠密向量算法,寻找与稠密查询向量点积最高的一组稠密文档向量,是最近邻搜索问题的一个实例。因此,现代系统会使用 Faiss 这样的近似最近邻向量搜索算法(Johnson et al., 2017)。
11.4 检索增强生成(RAG)
上一节介绍的信息检索技术可以通过一种称为检索增强生成(retrieval-augmented generation, RAG)的方法整合进语言模型。本节描述的基本 RAG 场景中,我们使用 IR 技术从某个指定文档库中检索可能含有有用信息的文档。随后,我们让大型语言模型在原始查询之外,也以这些文档为条件生成答案。
正如本章引言中总结的,检索增强生成有许多目标。RAG 通过给模型一组可信文档,有助于缓解幻觉。RAG 也能帮助语言模型围绕专有数据生成事实文本,例如个人电子邮件、健康记录、公司内部文档或其他法律文档。RAG 还可以帮助处理知识动态且具有时效性的问题,例如当我们知道用户的信息需求引用了语言模型训练之后才出现的数据时。
RAG 系统基于两个主要组件:检索器和生成器;后者有时由于历史原因也称为阅读器(Chen et al., 2017a)。图 11.13 概述了用于回答问题的标准模型。
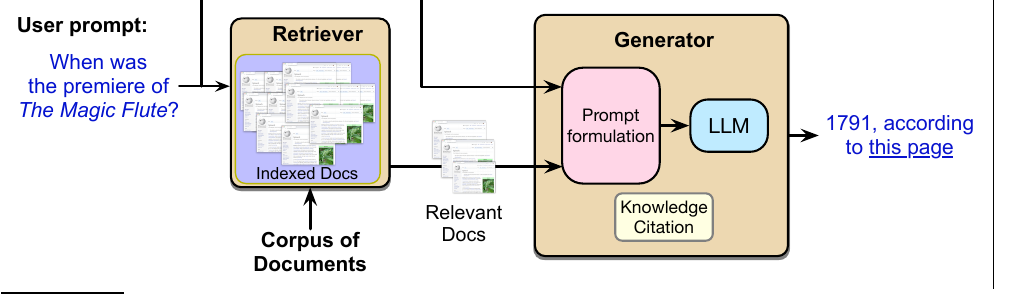
图 11.13 所示的检索增强生成(RAG)模型第一阶段,是从某个预先指定的文本集合中检索相关段落,例如使用上一节中的稠密检索器。第二个生成阶段中,我们取检索出的段落集合,把它与用户提示整合起来,然后把某个版本的这些内容传给大型语言模型,使其在这两类信息条件下生成答案。
例如,假设用户问:What year was the premiere of The Magic Flute? 我们把这个问题传给稠密检索器,并返回一系列关于 The Magic Flute 的段落。
检索增强生成的思想,是让模型同时以检索出的段落和某些提示文本为条件,例如 “Based on these texts, answer this question:”。因此,给定文档集合 $\mathcal{D}$ 和用户查询 $q$,最基本的 RAG 算法是:
- 调用检索器,返回 $R(q)=d_1\cdots d_k$,即 $\mathcal{D}$ 中相关度最高的 $k$ 个段落。
- 创建一个包含 $q$ 和检索段落的提示。
- 用该提示调用 LLM。
得到的提示可能类似下面这样:
Schematic of a RAG Prompt
retrieved passage 1
retrieved passage 2
...
retrieved passage k
Based on these texts, answer this question:
What year was the premiere of The Magic Flute?随后,语言模型的任务是根据下面的概率模型生成文本:
这个基本 RAG 范式有许多增强形式。一个新增方向是使用基于智能体的 RAG。在目前描述的 RAG 范式中,系统总是运行一次搜索,然后把检索出的段落与用户问题合并成提示。但在实际应用中,我们可能不希望每个用户轮次都运行检索;或者针对不同用户需求,我们可能希望从不同集合检索(有时是 Web,有时是私有集合)。在基于智能体的 RAG 中,系统会决定何时调用检索智能体,以及针对哪个集合调用。
另一个研究方向涉及检索器与生成器之间的关系。例如,检索出的段落中可能有噪声;有些段落可能不相关或错误,或顺序不利于使用。我们如何鼓励 LLM 关注好的段落?一些 RAG 架构在检索之后加入重排序器,对段落重新排序。或者,某些复杂问题可能需要多跳架构:先用一个查询检索文档,再把这些文档附加到原始查询之后,进行第二阶段检索。
另一类解决方案是为 RAG 训练 LLM。上面描述的基本 RAG 版本不涉及训练;我们取一个现成 LLM,把段落和提示交给它,希望它能正确判断哪些段落对生成答案有用或相关。一种学习变体是对 LLM 做指令微调:先创建一个问题数据集,其中每个问题都标注了检索段落和正确答案,然后指令微调 LLM,使其能根据段落正确回答问题。另一种方法是通过测试时计算完成:提示 LLM 回答问题,同时生成关于哪些段落有用的反思。生成这些反思的过程可能会使 LLM 更擅长识别好的段落。得到的反思文本也可用于上下文学习,例如把这些文本作为后续问题提示的一部分。
除了训练 LLM,我们也可以训练 IR 引擎。毕竟 IR 引擎本身并没有针对 RAG 场景优化。它可能没有训练过;即便训练过,也很可能是为简单 IR 或事实型问答任务训练,而不是为 RAG 场景训练,在 RAG 中检索出的段落专门要由另一个 LLM 用于生成文本。对于可训练的 IR 算法,可以通过在某组问题和答案上端到端训练整个架构,同时训练 IR 模型和 LLM 的参数,来缓解这种不匹配。
最后,让 LLM 为任何事实陈述向用户提供证据通常很有用。这可以采用知识引用的形式,例如可信来源的 URL,或特定文献的引用。例如,一个问答系统可能生成指向 URL 的编号指针:
Q: Which films have Gong Li as a member of their cast?
A: The Story of Qiu Ju [1], Farewell My Concubine [2], The Monkey King 2 [3], Mulan [3], Saturday Fiction [3] ...
生成知识引用最简单的方法,是把它指定为提示的一部分。例如,Gao et al. (2023) 使用的提示包含类似如下文本:
“Write an answer for the given question using only the provided search results (some of which might be irrelevant) and cite them properly... Always cite for any factual claim”.
11.5 数据集
有大量数据集包含以问题形式表达的信息需求,并标注了答案。它们既可以用于指令微调,也可以用于评估语言模型的问答能力。
我们可以沿许多维度区分这些数据集,Rogers et al. (2023) 对此做了很好的总结。一个维度是数据中问题的原始目的:它们是自然的信息寻求问题,还是为探测而设计的问题,即用于评估或测试系统或人类的问题。
在自然问题一侧,有 Natural Questions(Kwiatkowski et al., 2019)这样的数据集,它包含匿名化的英文 Google 搜索查询及其答案。答案由标注者基于 Wikipedia 信息创建,包括段落长度的长答案和短片段答案。例如,问题 “When are hops added to the brewing process?” 的短答案是 the boiling process,长答案则是 Wikipedia 中 Brewing 页面上的整个段落。
类似的自然问题集合是 MS MARCO(Microsoft Machine Reading Comprehension)数据集集合,其中包括来自 Microsoft Bing 查询日志的 100 万个真实匿名英文问题,以及人工生成的答案和 900 万个段落(Bajaj et al., 2016),可用于测试检索排序和问答。
虽然许多数据集聚焦英语,其他语言中也存在自然信息寻求问题数据集。DuReader 数据集是一个基于搜索引擎查询和社区问答的中文 QA 资源(He et al., 2018)。TyDi QA 数据集包含来自 11 种类型学上多样语言的 20.4 万个问答对,包括阿拉伯语、孟加拉语、斯瓦希里语、俄语和泰语(Clark et al., 2020a)。在 TyDi QA 任务中,系统会得到一个问题和一篇 Wikipedia 文章中的段落,并必须(a)选择包含答案的段落(如果没有段落包含答案,则选择 NULL),以及(b)标记最小答案片段(或 NULL)。
在探测类数据集一侧,有 MMLU(Massive Multitask Language Understanding)这样的数据集。它是一个常用数据集,包含 15908 个知识与推理问题,覆盖 57 个领域,包括医学、数学、计算机科学、法律等。MMLU 问题来自面向人类的各种考试,例如美国研究生入学考试、医师执照考试和大学先修课程考试。因此,这些问题并不代表人们的信息需求,而是为测试人类在学术或执照场景中的知识而设计。图 11.14 展示了一些示例,正确答案以粗体显示。

上面描述的一些问题数据集会为每个问题附加可从中抽取答案的段落。这些数据集主要为一种较早的 QA 任务创建,称为阅读理解(reading comprehension):模型给定一个问题和一个文档,需要从给定文档中抽取答案。给定一个或多个文档(例如通过 RAG)来进行问答的任务,有时称为开卷 QA;完全不使用检索组件、直接从 LM 回答的任务称为闭卷 QA。[注 5] 因此,Natural Questions 这样的数据集,如果求解器使用每个问题附带的文档,就可以视为开卷;如果不使用文档,就可以视为闭卷;而 MMLU 这样的数据集则完全是闭卷。
另一个变化维度是答案格式:多项选择还是自由形式。当然,提示方式也有变化,例如模型只得到问题(零样本),还是也得到类似问题答案的示例(少样本)。MMLU 同时提供零样本和少样本提示选项。
11.6 问答评估
评估问答系统通常使用两种技术,具体选择取决于问题类型和 QA 场景。对于 MMLU 这样的多项选择问题,我们报告 exact match:
- Exact match:
- 预测答案与金标准答案完全匹配的百分比。
对于 Natural Questions 这样的自由文本答案问题,通常使用词元 F1 分数来粗略度量答案与参考答案之间的部分字符串重叠:
- F1 score:
- 预测答案与金标准答案之间的平均词元重叠。把预测和金标准都视为词元袋,为每个问题计算 F1,然后返回所有问题上的平均 F1。
11.7 小结
本章介绍了信息检索任务,以及使用检索增强生成(RAG)利用检索段落改进 LLM 问答和其他事实生成的方式。
- 本章聚焦信息检索在问答及相关事实任务中的使用。其思想是利用某个文档集合(可能是 Web)中的材料来满足用户的信息需求。
- 信息检索(IR)是根据用户以查询表达的信息需求,向用户返回文档的任务。在排序检索中,文档按排序顺序返回。
- IR 有两种范式:稀疏检索和稠密检索。两种范式都用文档与查询的相似度来估计文档与用户信息需求的相关性。
- 在稀疏检索技术中,我们把查询和文档都表示为其中词的一元计数稀疏向量,每个计数由 tf-idf 或 BM25 加权。随后可以用这些稀疏向量之间的余弦度量查询-文档相似度。
- 倒排索引是一种用于稀疏检索的存储机制,使查找包含特定词的文档非常高效。
- 在稠密检索技术中,文档或查询改用由语言模型计算得到的嵌入(稠密向量)表示,语言模型可以是 BERT 家族这样的 encoder-only 模型,也可以是 decoder-only 模型。文档-查询相似度在嵌入空间中用点积或余弦计算。
- 对于稠密检索,FAISS 是一种近似最近邻向量搜索算法,使得寻找与查询嵌入最相似的 $k$ 个文档嵌入非常高效,从而可以快速排序。
- 排序检索通常用平均精度均值或插值精确率来评估。
- 检索可以通过检索增强生成并入语言建模。在检索步骤中,用户查询被传给搜索引擎,以检索一组相关文档或段落。在生成阶段,大型语言模型得到包含查询和从集合中检索出的文档集合的提示,然后条件生成答案。
- 问答等事实任务,如果只有单个答案,可以用与已知答案的 exact match 来评估;如果是自由文本答案,可以用词元 F1 分数来评估。
历史注记
问答是最早的 NLP 任务之一。到 1961 年,BASEBALL 系统(Green et al., 1961)已经可以通过查询一个包含比赛信息的结构化数据库,回答关于棒球比赛的问题,例如 “Where did the Red Sox play on July 7”。该数据库存储为某种属性-值矩阵,其中包含每场比赛的属性值:
Month = July
Place = Boston
Day = 7
Game Serial No. = 96
(Team = Red Sox, Score = 5)
(Team = Yankees, Score = 3)每个问题都会使用宾夕法尼亚大学 Zellig Harris 的 TDAP 项目中的算法进行成分句法分析,本质上是一串有限状态转导器级联(见 Joshi and Hopely 1999 与 Karttunen 1999 中的历史讨论)。随后在内容分析阶段,每个词或短语都会关联到一个计算其部分意义的程序。因此,短语 “Where” 有代码把语义赋为 Place = ?,结果是问题 “Where did the Red Sox play on July 7” 被赋予如下意义:
Place = ?
Team = Red Sox
Month = July
Day = 7随后,问题与数据库匹配并返回答案。
Simmons et al. (1964) 的 Protosynthex 系统在给定问题时,会从问题中的内容词形成查询,然后在文档中检索候选答案句子,并按其与问题之间的频率加权项重叠排序。随后,查询和每个检索句都会用依存解析器解析,并选择结构与问题结构最匹配的句子。因此,问题 What do worms eat? 会匹配 worms eat grass:在当时使用的依存语法版本中,两者都有主语 worms 作为 eat 的依存成分,而 birds eat worms 的主语是 birds:
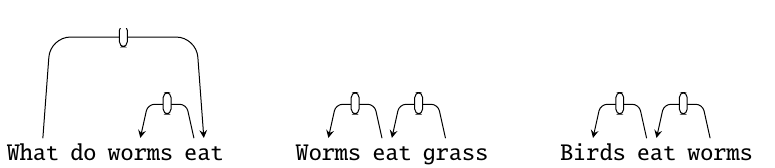
Simmons (1965) 总结了其他早期 QA 系统。
到 20 世纪 70 年代,系统使用谓词演算作为意义表示语言。LUNAR 系统(Woods et al. 1972, Woods 1978)被设计为一个面向月球地质化学事实数据库的自然语言接口。它可以回答诸如 Do any samples have greater than 13 percent aluminum 这样的问题,方法是把问题解析成逻辑形式:
(TEST (FOR SOME X16 / (SEQ SAMPLES) : T ; (CONTAIN' X16
(NPR* X17 / (QUOTE AL203)) (GREATERTHAN 13 PCT))))到 20 世纪 90 年代,问答转向机器学习。Zelle and Mooney (1996) 提出把问答视为语义解析任务,并创建了基于 Prolog 的 GEOQUERY 数据集,用于美国地理问题。这个模型后来由 Zettlemoyer and Collins (2005) 和 2007 扩展。十年之后,神经模型被用于语义解析(Dong and Lapata 2016, Jia and Liang 2016),随后也通过把文本映射到 SQL 用于基于知识的问答(Iyer et al., 2017)。
[TBD: IR 的历史。]
与此同时,另一种更依赖信息检索来回答问题的范式,受到 20 世纪 90 年代 Web 兴起的影响。美国政府资助的 TREC(Text REtrieval Conference)评测自 1992 年起每年举办,为评估信息检索任务与技术提供了测试平台(Voorhees and Harman, 2005)。TREC 在 1999 年增加了一个影响深远的 QA 赛道,由此推动了大量事实型与非事实型问答系统在年度评测中竞争。
同一时期,Hirschman et al. (1999) 提出使用儿童阅读理解测试来评估机器文本理解算法。他们获得了一个包含 120 个篇章的语料,每个篇章有 5 个问题,面向 3 到 6 年级儿童设计;他们构建了一个答案抽取系统,并测量系统给出的答案与测试出版方答案键的对应程度。他们的算法把词重叠作为特征;后续算法加入了命名实体特征,以及问题与答案片段之间更复杂的相似度(Riloff and Thelen 2000, Ng et al. 2000)。
Watson Jeopardy! 系统中的 DeepQA 组件,是在神经系统变得普遍之前开发的大型复杂特征系统。它在 IBM Journal of Research and Development 第 56 卷的一系列论文中描述,例如 Ferrucci (2012)。
早期神经阅读理解系统沿用了早期系统的一个共同洞见:答案查找应关注问题-篇章相似度。这些神经系统的许多架构轮廓由 Hermann et al. (2015)、Chen et al. (2017a) 和 Seo et al. (2017) 奠定。这些系统聚焦 Rajpurkar et al. (2016)、Rajpurkar et al. (2018) 及其后继数据集,通常使用独立 IR 算法作为神经阅读理解系统的输入。使用稠密检索加基于片段的阅读器、通常采用单一端到端架构的范式,可由 Lee et al. (2019) 或 Karpukhin et al. (2020) 等系统代表。开放域 QA 中稠密检索的一个重要研究方向是训练数据:使用自监督方法避免标注正负段落(Sachan et al., 2023)。
早期关于大型语言模型的工作表明,它们在预训练过程中存储了足够知识来回答问题(Petroni et al., 2019; Raffel et al., 2020; Radford et al., 2019; Roberts et al., 2020)。一开始它们还无法与专门的问答器竞争,但很快超过了这些系统。检索增强生成算法最早作为改进语言建模词预测的方法被引入(Khandelwal et al., 2019),但很快被应用于问答(Izacard et al., 2022; Ram et al., 2023; Shi et al., 2023)。
练习
(原稿暂未列出练习题。)