2 词与词元
User: I need some help, that much seems certain.
ELIZA: WHAT WOULD IT MEAN TO YOU IF YOU GOT SOME HELP
User: Perhaps I could learn to get along with my mother.
ELIZA: TELL ME MORE ABOUT YOUR FAMILY
User: My mother takes care of me.
ELIZA: WHO ELSE IN YOU FAMILY TAKES CARE OF YOU
User: My father.
ELIZA: YOUR FATHER
User: You are like my father in some ways.
Weizenbaum (1966)
上面的对话来自 ELIZA,这是一个早期自然语言处理系统。它通过模仿罗杰斯式心理治疗师的回应,能够与用户进行有限的交谈(Weizenbaum, 1966)。ELIZA 是一个出人意料地简单的程序:它用词上的模式匹配识别诸如 “I need X” 这样的短语,再把其中的词改写成合适的输出,例如 “What would it mean to you if you got X?”。以今天的标准来看,ELIZA 对人类对话的模仿非常粗糙,但当时却相当成功:许多与 ELIZA 互动的人相信它真的理解了自己。也正因为如此,这项工作促使研究者开始思考聊天机器人对用户的影响(Weizenbaum, 1976)。
当然,现代聊天机器人并不使用 ELIZA 开创的这种简单的基于模式的模仿方法。不过,ELIZA 所体现的这种基于词的模式方法,在今天的词元化(tokenization)中仍然相关。词元化的任务,是从连续文本中切分出词和词的一部分。作为现代 NLP 的第一步,词元化仍包含可以追溯到 ELIZA 的基于模式的方法。
为了理解词元化,我们首先需要问:什么是词?um 算一个词吗?New York 呢?不同语言中的词具有相似性质吗?有些语言,如越南语或粤语,词很短;另一些语言,如土耳其语,词则很长。我们还需要思考如何用字符来表示词。本章将介绍 Unicode,即现代字符表示系统,以及 UTF-8 文本编码。我们还将介绍语素,即词中有意义的组成部分(例如 longer 中的语素 -er)。
切分文本的标准方法,是利用输入字符来指导切分。因此,在理解了词可能具有的组成部分之后,我们将介绍标准的 字节对编码(Byte-Pair Encoding, BPE)算法,它能自动把输入文本分解为词元。这个算法利用字母序列的简单统计量,归纳出一个子词词元词表。所有词元化系统也都依赖正则表达式作为处理步骤。正则表达式是一种用来形式化指定和操作文本字符串的语言,是所有现代 NLP 系统中的重要工具。本章将介绍正则表达式并展示其用法。
最后,我们将介绍一个称为编辑距离的度量,它根据把一个字符串变成另一个字符串所需的编辑次数(插入、删除、替换)来衡量两个词或字符串有多相似。只要 NLP 需要比较两个词或字符串,编辑距离就会发挥作用;例如,在自动语音识别中,关键的词错误率指标就用到了它。
2.1 词
下面这个句子里有多少个词?
They picnicked by the pool, then lay back on the grass and looked at the stars.
如果不把标点当作词,这个句子有 16 个词;如果把标点也算作词,则有 18 个词。是否把句号(“.”)、逗号(“,”)等标点视为词,取决于任务。标点对于寻找边界非常关键(逗号、句号、冒号),也有助于识别意义的某些方面(问号、感叹号、引号)。大型语言模型通常把标点当作独立的词来计数。
口语在定义词时还会带来其他复杂性。考虑下面这段口语对话中的话语(utterance)。话语是语言学中用来指代“口语中与句子对应的单位”的术语:
I do uh main- mainly business data processing
这句话包含两类不流畅现象。中途断开的词 main- 称为片段。像 uh 和 um 这样的词称为填充词或填充停顿。我们应该把它们看作词吗?答案仍然取决于应用。如果我们构建的是语音转写系统,也许最终想把这些不流畅现象去掉。但有时我们也会保留它们。像 uh 或 um 这样的不流畅现象,在语音识别中实际上有助于预测下一个词,因为它们可能表示说话者正在重新开始一个从句或想法;因此在语音识别中,它们会被当作普通词处理。由于不同人使用不同的不流畅形式,它们也可以成为说话人识别的线索。事实上,Clark 和 Fox Tree(2002)表明,英语中的 uh 和 um 具有不同含义。你认为它们分别表示什么?
也许最重要的是,在思考什么是词时,我们需要区分两种谈论词的方式,这将在全书中都很有用。词型(word type)指语料库中不同词的数量;如果词表中的词集合为 $V$,那么词型数就是词表大小 $|V|$。词实例(word instance)指连续文本中词出现的总数 $N$。[注 1] 如果忽略标点,前面的野餐句子有 14 个词型和 16 个词实例:
They picnicked by the pool, then lay back on the grass and looked at the stars.
我们仍然需要做决定。例如,像 They 这样的首字母大写字符串,是否应与 they 这样的非大写字符串视为同一个词型?答案是:取决于任务。在一些不太关心格式的任务中,They 和 they 可能被合并为同一词型;而在另一些任务中,大小写是有用特征,需要保留。有时我们会同时保留一个 NLP 模型的两个版本:一个保留大小写,另一个不保留大小写。
到目前为止,我们一直在谈论正字法词,也就是基于英语书写系统的词。但定义词还有许多其他可能方式。例如,从正字法上看,I'm 是一个词;但从语法上看,它相当于两个词:主语代词 I 和动词 'm,即 am 的缩写形式。

一旦开始考虑其他语言,这些区分会变得更难。例如,汉语、日语和泰语等语言的书写系统根本没有正字法意义上的词;也就是说,它们不使用空格来标出潜在的词边界。以汉语为例,词由汉字组成。每个汉字通常表示一个单一意义单位(下文会介绍,这称为语素),并且可以作为一个音节发音。汉语词平均约有 2.4 个汉字。但由于汉语没有正字法词,判定什么算作一个词就很复杂。例如,考虑下面的句子:
(2.1) 姚明进入总决赛 yao ming jin ru zong jue sai
“Yao Ming reaches the finals”
正如 Chen 等(2017b)指出的,这个句子可以被看作 3 个词(这是一种称为“中国树库”的词定义,其中中文姓名,即姓加名,被看作一个词):
(2.2) 姚明 进入 总决赛
YaoMing reaches finals
同一个句子也可以被看作 5 个词(“北京大学”标准),其中姓名被拆成自己的单位,某些形容成分也被视为独立词:
(2.3) 姚 明 进入 总 决赛
Yao Ming reaches overall finals
最后,在汉语中也可以完全忽略词,把字符作为基本元素,将句子看作 7 个字符的序列。因为汉字在大多数应用中处在相当合理的语义层级上,这种方法对汉语效果很好(Li et al., 2019):
(2.4) 姚 明 进 入 总 决 赛
Yao Ming enter enter overall decision game
但这种方法并不适用于日语和泰语,因为这些语言中的单个字符作为单位过小。
这些词定义上的问题,使得跨语言 NLP 很难以词作为文本词元化的基础。
但词还有另一个问题:词太多了!英语到底有多少词?当我们谈论一种语言中的词数时,通常指的是词型数。图 2.1 给出了一些英语语料库中词型和词实例的大致数量。
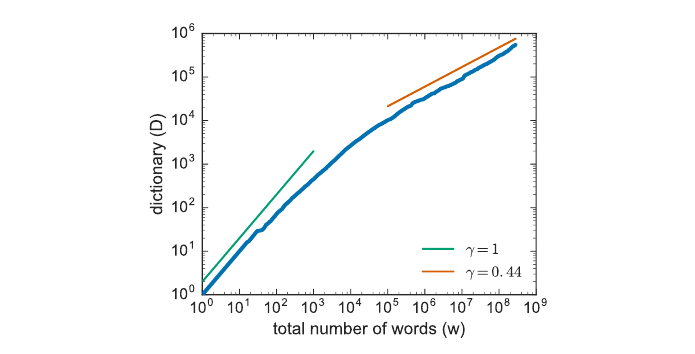
你会注意到,我们查看的语料库越大,发现的词型就越多。这说明“英语有多少词”没有一个明确答案;答案会随着我们看到更多数据而不断增长。这个事实也可以用数学方式表达:词型数 $|V|$ 与词实例数 $N$ 之间的关系称为 Herdan 定律(Herdan, 1960)或 Heaps 定律(Heaps, 1978),分别以其在语言学和信息检索中的发现者命名。式 (2.5) 给出该关系,其中 $k$ 和 $\beta$ 是正的常数,且 $0<\beta<1$。
$\beta$ 的值依赖于语料库大小和体裁;常见报告值在 0.44 到 0.56 之间,有时甚至更高。粗略地说,一段文本的词表大小会以略快于词数平方根的速度增长。
这个定律还有一些变体,它们反映了一个事实:我们大致可以区分两类词。一类是功能词,如英语中的 a 和 of 这类语法词,它们通常不会无限增长(一种语言往往有固定数量的这类词)。另一类是内容词:名词、形容词和动词,它们通常带有关于人、地点和事件的意义。名词,尤其是姓名和技术术语等专有名词,确实会持续增长。因此,对功能词和内容词之间差异敏感的模型,会在语料库开始部分所有词还都在出现时使用一个 $\beta$ 值,然后在之后只有内容词仍在出现时使用另一个 $\beta$ 值。图 2.2 来自 Tria 等(2018),展示了在 Gutenberg 图书语料库上计算的 Heaps 定律,其中有两个 $\beta$ 值(在他们的图中称为 $\gamma$)。
词会无止境增长这一事实,会给任何计算模型带来问题。无论词表有多大,我们永远无法拥有一个涵盖所有可能出现词的词表。这意味着计算模型会不断遇到未知词,也就是它从未见过的词。对于机器学习模型来说,这是一个很大的问题。
正因为这两个问题:第一,许多语言没有正字法词,事后定义词很困难;第二,词数没有上界,所以语言模型和其他 NLP 模型通常不把词作为处理单位。相反,它们使用称为子词的更小单位,这些单位可以重新组合,用来建模模型从未见过的新词。为了思考如何定义子词,我们先需要谈论比词更小的单位:语素和字符。
2.2 语素:词的一部分
词有组成部分。从字符层面看,这显而易见。词 cats 由四个字符 `c'、`a'、`t'、`s' 构成。但在更细微的层面上也是如此:词包含一些自身具有连贯意义的组成部分。这些组成部分称为语素,研究语素的学科称为形态学。语素是一种语言中最小的意义承载单位。例如,词 fox 由一个语素构成(语素 fox),而词 cats 由两个语素构成:语素 cat 和表示复数的语素 -s。
下面是一个用连字符把英语句子切分为语素的例子:
(2.6) Doc work-ed care-ful-ly wash-ing the glass-es
如上所述,在汉语中,书写系统很方便地使每个字符主要描述一个语素。下面是一句普通话句子,每个语素字符下面给出逐词 gloss,随后给出翻译:
(2.7) 梅 干 菜 用 清 水 泡 软,捞 出 后,沥 干
plum dry vegetable use clear water soak soft, remove out after, drip dry
切 碎
chop fragment
Soak the preserved vegetable in water until soft, remove, drain, and chop
我们通常把语素大致分为两大类:词根,也就是词的中心语素,提供主要意义;以及词缀,它添加各种“额外”意义。在上面的英语例子中,对于词 worked,work 是词根,-ed 是词缀;类似地,对于 glasses,glass 是词根,-es 是词缀。
词缀本身又可分为两类,更准确地说,是两个端点之间的连续统。一端是屈折语素,它们是语法性语素,往往发挥句法作用,例如标记一致关系。比如,英语中有屈折语素 -s(或 -es)来标记名词复数,有屈折语素 -ed 来标记动词过去时。屈折语素往往具有能产性,常常是必需的,其意义也通常可预测。
派生语素在适用范围和意义上更具特异性。它们通常只适用于某个特定词类子集,并产生与词根语法类别不同的词,意义也常常难以精确预测。在上面的例子中,词 care(名词)可以与派生词缀 -ful 结合生成形容词 careful,再与另一个派生词缀 -ly 结合生成副词 carefully。
还有另一类语素:附着词。附着词在句法上像词一样起作用,但形式上被弱化,并附着在另一个词上(在音系上,有时也在正字法上)。例如,英语 I've 中的 've 是一个附着词;它具有词 have 的语法意义,但在形式上不能单独出现(你不能只说句子 “'ve”)。英语短语 the teacher's book 中的所有格语素 's 也是附着词。法语词 l'opera 中的定冠词 l' 是附着词;阿拉伯语中的介词如 b “by/with”和连词如 w “and”也是如此。
研究语言在形态上如何变化,也就是词如何分解成各组成部分,称为形态类型学。虽然语言形态可以沿许多维度变化,但对于计算词元化来说,有两个维度尤其相关。
第一个维度是每个词包含多少语素。在一些语言中,如越南语和粤语,每个词平均只有略多于一个语素。我们把这个尺度一端的语言称为孤立语。例如,下面这句粤语中的每个词都有一个语素(和一个音节):
(2.8) keoi5 waa6 cyun4 gwok3 zeoi3 daai6 gaan1 uk1 hai6 ni1 gaan1
he say entire country most big building house is this building
“He said the biggest house in the country was this one”
另一端,在科里亚克语这类语言中,一个词可能包含很多语素,相当于英语中的一整句话。科里亚克语属于楚科奇-堪察加语系,使用于俄罗斯堪察加半岛北部(Arkadiev, 2020; Kurebito, 2017)。我们把接近这一端的语言称为综合语,把尺度最末端的语言称为多式综合语。
(2.9) t-@-nk'e-mejN-@-jetem@-nni-k
1SG.S-E-midnight-big-E-yurt.cover-E-sew-1SG.S[PFV]
“I sewed a lot of yurt covers in the middle of a night.”
(Koryak, Chukotko-Kamchatkan, Russia; Kurebito (2017, 844))
图 2.3 展示了语言类型学家 Joseph Greenberg(1960)对若干语言中每词语素数的早期估计。

第二个维度是语素是否容易切分:从土耳其语这类黏着语(语素边界相对清楚),到俄语这类融合语(单个词缀可能融合多个语素)。例如,俄语 stolom(table-SG-INSTR-DECL 1)中的 -om 融合了工具格、单数和第一变格这几个不同形态范畴。
英语句子 She reads the article 中的后缀 -s 是融合的例子,因为这个后缀同时表示第三人称单数和现在时,而且无法把这两个意义分配到 -s 的不同部分。
尽管我们一直把分析性、多式综合性、融合性、黏着性这些性质粗略说成语言的性质,但实际上,一种语言可以使用不同的形态系统,所以更准确的说法是把它们看成一般倾向。
尽管如此,语素很难定义,而且许多语言可能具有复杂语素,不容易拆分成小片段。这些事实使得在跨语言场景中用语素作为词元化标准非常困难。
2.3 Unicode
词元化还可以考虑另一个层级:单个字符。我们究竟如何表示不同语言和书写系统中的字符?Unicode 标准是一种表示文本的方法,能够表示世界各语言中任何文字系统的任何字符(包括苏美尔楔形文字这类已消亡语言,以及克林贡语这类发明语言)。
我们先从 Unicode 的一个英语专用子集开始做一个简短历史说明。这个子集在 Unicode 中的技术名称是 “Basic Latin”,通常称为 ASCII。从 20 世纪 60 年代开始,用于书写英语的拉丁字符(如本句中的字符)用一种称为 ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)的编码来表示。ASCII 用一个字节表示每个字符。一个字节可以表示 256 个不同字符,但 ASCII 只使用其中 127 个;ASCII 字节的最高位总是设为 0。(实际上它只用了其中 95 个,其余是为一种已过时的电传打字机准备的控制码。)下面列出若干 ASCII 字符及其十六进制和十进制表示。

当然,ASCII 是不够的,因为世界上的书写系统中还有许多其他字符。即便是使用拉丁字符的文字,也远远超过 ASCII 中的 95 个字符。例如,下面这个西班牙语短语(意思是 “Sir, replied Sancho”)包含两个非 ASCII 字符:n~ 和 ó:
(2.10) Señor- respondió Sancho-
还有大量语言根本不基于拉丁字符。天城文(Devanagari)用于 120 种语言(包括印地语、马拉地语、尼泊尔语、信德语和梵语)。下面是《世界人权宣言》印地语文本中的一个天城文例子:
{अनुच्छेद १(एक): सभी मनुष्य जन्म से स्वतन्त्र तथा मर्यादा और अधिकारों में समान होते हैं। वे तर्क और विवेक से सम्पन्न हैं तथा उन्हें भ्रातृत्व की भावना से परस्पर के प्रति कार्य करना चाहिये।}
Unicode 中大约有 100,000 个汉字字符(包括中、日、韩、越所用字符中重叠和非重叠的变体,统称为 CJKV)。
总的来说,Unicode 16.0 支持超过 150,000 个字符和 168 种不同文字。尽管世界各地仍有许多文字尚未加入 Unicode,但现有集合已经非常庞大:既有现代语言使用的文字(汉字、阿拉伯字母、印地文字、切罗基文、埃塞俄比亚文、高棉文、N'Ko、土耳其语、西班牙语等),也有古代语言文字(楔形文字、乌加里特文字、埃及象形文字、巴列维文),还有数学符号、表情符号、货币符号等。
2.3.1 码点
Unicode 如何工作?它为这 150,000 多个字符中的每一个分配一个唯一 id,称为码点。
码点是字符的抽象表示,每个码点由一个数字表示,传统上写成十六进制,范围从 0 到 0x10FFFF(十进制为 1,114,111)。超过一百万个码点意味着有大量空间可以容纳新字符。通常用前缀 “U+” 表示这些码点(意思只是“接下来是一个 Unicode 码点的十六进制表示”)。因此,字符 a 的码点是 U+0061,也就是 0x0061。(注意,Unicode 的设计向后兼容 ASCII,这意味着前 127 个码点,包括 a 的编码,都与 ASCII 相同。)下面是一些示例码点;其中有些附带说明:
U+0061 a LATIN SMALL LETTER A
U+0062 b LATIN SMALL LETTER B
U+0063 c LATIN SMALL LETTER C
U+00F9 ù LATIN SMALL LETTER U WITH GRAVE
U+00FA ú LATIN SMALL LETTER U WITH ACUTE
U+00FB û LATIN SMALL LETTER U WITH CIRCUMFLEX
U+00FC ü LATIN SMALL LETTER U WITH DIAERESIS
U+8FDB 进
U+8FDC 远
U+8FDD 违
U+8FDE 连
U+1F600 GRINNING FACE
U+1F00E MAHJONG TILE EIGHT OF CHARACTERS注意,码点并不指定字形,也就是字符的视觉表现。字形存储在字体中。码点 U+0061 是 a 的抽象表示。它可以有无限多种视觉表现,例如不同字体中的 Times Roman(a)或 Courier(a),或者粗体(a)和斜体(a)等不同字体样式。但所有这些都由同一个码点 U+0061 表示。
2.3.2 UTF-8 编码
码点(唯一 id)是字符的抽象 Unicode 表示,但我们不会直接把这个 id 放进文本文件里。
相反,每当我们需要在文本字符串中表示一个字符时,我们写入的是该字符的一种编码。可能的编码方法有很多,但称为 UTF-8 的编码方法是迄今最常见的(例如,几乎整个 Web 都用 UTF-8 编码)。
先谈编码。单词 hello 的 Unicode 表示由如下 5 个码点序列构成:
U+0068 U+0065 U+006C U+006C U+006F我们可以想象一种非常简单的编码方法:把码点 id 直接写入文件。由于字符超过一百万个,16 位(2 字节)不够,因此需要使用 4 字节(32 位)来容纳表示 110 万字符所需的 21 位。(3 字节也能装下,但以 3 为倍数使用字节不方便。)
在这种 4 字节表示下,单词 hello 会编码为下面这组字节:
00 00 00 68 00 00 00 65 00 00 00 6C 00 00 00 6C 00 00 00 6F但我们不使用这种编码(技术上称为 UTF-32),因为它会让每个文件比 ASCII 情况长 4 倍,使文件很大且充满 0。那些 0 还会造成另一个问题:历史上,基于 ASCII 的系统使用 0 字节作为字符串结束标记,因此任何全零字节都会破坏向后兼容性。
相反,最常见的编码标准是 UTF-8(Unicode Transformation Format 8)。它通过让某些字符使用较少字节、某些字符使用较多字节,来高效表示字符(平均使用更少字节)。因此,UTF-8 是一种变长编码。
对于某些字符(前 127 个码点,即 ASCII 字符集合),UTF-8 用一个字节编码。所以 hello 的 UTF-8 编码是:
68 65 6C 6C 6F这很方便地意味着:ASCII 编码的文件也是合法的 UTF-8 编码文件。
但 UTF-8 是变长编码,也就是说,码点 $\geq 128$ 的字符会被编码为二、三或四个字节的序列。这些字节都在 128 到 255 之间,因此不会与 ASCII 混淆;每个字节的前几位还会标明它属于 2 字节、3 字节还是 4 字节编码。

图 2.5 展示了这种映射如何发生。例如,这些规则解释了字符 ñ 如何被编码。它的码点是 U+00F1,位序列是 00000000 11110001;其中一部分位会被填入 UTF-8 模板,得到二字节位序列 11000011 10110001,也就是 0xC3B1。根据这些规则,前 127 个字符(ASCII)映射为一个字节;欧洲、中东和非洲文字中多数其他字符映射为两个字节;多数中、日、韩字符映射为三个字节;较罕见的 CJKV 字符、表情符号和一些符号映射为四个字节。
UTF-8 有很多优点。它相对高效,对常见字符使用较少字节;除了表示 NULL 字符 U+0000 时以外,它不使用零字节;它向后兼容 ASCII;并且它是自同步的,这意味着如果文件损坏,只要向左或向右移动最多 3 个字节,就总能找到前一个或下一个字符的起点。
Unicode 与 Python
从 Python 3 开始,所有 Python 字符串内部都以 Unicode 存储,每个字符串都是 Unicode 码点序列。因此,字符串函数和正则表达式都原生作用于码点。例如,字符串的 len() 函数返回的是字符数,也就是码点数,而不是字节数。
不过,在从文件读取或写入文件时,码点需要通过 UTF-8 之类的方法进行编码和解码。也就是说,每个文件都有某种编码。如果不是 UTF-8,就是 ASCII 或 Latin-1(iso 8859 1)等更旧的编码方法。不存在没有编码的文本文件。在 Python 中,打开文件进行读写时需要指定编码方法。
2.4 子词词元化:字节对编码
词元化是自然语言处理的第一阶段,是把连续的输入文本分割成词元的过程。
我们已经看到三种词元候选:词、语素和字符。但作为单位,它们各有问题。词和语素似乎大致处在 NLP 处理所需的层级,因为它们往往具有稳定意义,但形式化定义困难。字符更容易定义,却又显得过小,不太适合作为词元。
本节介绍 NLP 实践中的做法:使用数据驱动的方法定义词元。其结果通常是大小接近语素或词的单位,但偶尔也会使用小到单个字符的单位。
为什么要对输入做词元化?一个原因是,把输入转换为确定性的固定单位集合,可以让不同算法和系统在简单问题上达成一致。例如:这段文本有多长?(里面有多少单位?)或者:don't 是一个词元还是两个?New York 是一个还是两个?因此,标准化对于 NLP 实验的可复现性至关重要;本书将介绍的许多算法(例如语言模型的困惑度指标)都假设所有文本具有固定的词元化方式。
包含语素和字母等较小词元的词元化算法,也消除了未知词问题。什么是未知词?正如下一章将看到的,NLP 算法通常从一个语料库(训练语料)中学习关于语言的一些事实,然后用这些事实对另一个独立测试语料及其语言做决策。因此,如果我们的训练语料包含 low、new 和 newer,但不包含 lower,那么当 lower 出现在测试语料中时,系统就不知道该如何处理它。
为了解决未知词问题,现代词元化器会自动归纳出一组词元,其中包括比词更小的词元,称为子词。子词可以是任意子串,也可以是像 -est 或 -er 这样承载意义的单位。在现代词元化方案中,许多词元是词,但其他词元常常是高频语素或其他子词,如 -er。因此,每个未见过的词都可以表示为某个已知子词单位序列。例如,如果我们恰好从未见过 lower,当它出现时,我们仍可以成功地把它切分为已经见过的 low 和 er。在最坏情况下,一个非常罕见的词(也许是像 GRPO 这样的缩写)必要时可以被切分为单个字母序列。
现代语言模型广泛使用两种词元化算法:字节对编码(Byte-Pair Encoding, BPE)(Sennrich et al., 2016)和 unigram language modeling(ULM)(Kudo, 2018)。[注 2] 本节介绍字节对编码,即 BPE 算法(Sennrich et al., 2016; Gage, 1994),见图 2.6。
与大多数词元化方案一样,BPE 算法有两个部分:训练器和编码器。一般来说,在词元训练阶段,我们取一个原始训练语料(通常已经大致预先分为词,例如按空白切分),归纳出一个词表,即一组词元。随后,词元编码器接收一个原始测试句子,并把它编码成训练阶段学到的词表中的词元。
2.4.1 BPE 训练
BPE 训练算法反复合并频繁相邻的词元,从而创建越来越长的词元。算法从一个只包含所有单个字符的词表开始。随后它查看训练语料,找到最频繁相邻的两个字符。假设我们的原始语料有 10 个字符,使用包含 5 个字符的词表 $\{A,B,C,D,E\}$:
A B D C A B E C A B最频繁的相邻字符对是 “A B”,所以我们合并它们,把新的合并词元 `AB' 加入词表,并把语料中每个相邻的 `A' `B' 替换成新的 `AB':
AB D C AB E C AB现在词表有 6 个可能词元 $\{A,B,C,D,E,AB\}$,语料长度为 7。此时最频繁的词元对是 “C AB”,所以合并它们,得到包含 7 个词元的词表 $\{A,B,C,D,E,AB,CAB\}$,语料长度变为 5。
AB D CAB E CAB算法继续计数并合并,创建越来越长的字符串,直到完成 $k$ 次合并并创建 $k$ 个新词元;因此 $k$ 是算法的一个参数。所得词表由原始字符集合加上 $k$ 个新符号构成。这就是算法核心。
唯一额外的复杂之处是:实践中,算法通常不是直接运行在原始字符序列上,而是只在词内部运行。也就是说,算法不会跨越词边界合并。为此,输入语料通常首先按空白和标点切开(使用本章后面会定义的正则表达式)。这样会得到一组初始字符串,每个字符串对应某个词的字符序列(空白通常附着在词开头),并带有该词的计数。因此,计数来自语料,但合并只允许在这些字符串内部发生。
来看完整算法如何在这个很小的人工语料上运行;我们显式标出了词之间的空格:[注 3]
(2.11) set new new renew reset renew
首先,我们把语料拆成带前导空白的词,并记录计数;合并不允许越过这些词边界。结果是 4 个词的列表,以及包含 7 个字符的初始词表:
corpus vocabulary
2 _ n e w _, e, n, r, s, t, w
2 _ r e n e w
1 s e t
1 _ r e s e tBPE 训练算法首先统计所有相邻符号对:最频繁的是 n e,因为它出现在 new 中(频率 2)和 renew 中(频率 2),总共 4 次。随后我们合并这些符号,把 ne 当作一个符号,并再次计数:
corpus vocabulary
2 _ ne w _, e, n, r, s, t, w, ne
2 _ r e ne w
1 s e t
1 _ r e s e t现在最频繁的符号对是 ne w(总计数 4),于是合并它。
corpus vocabulary
2 _ new _, e, n, r, s, t, w, ne, new
2 _ r e new
1 s e t
1 _ r e s e t接下来 _ r(总计数 3)被合并为 _r,然后 _r e(总计数 3)被合并为 _re。系统实际上归纳出了一个词首前缀 re-:
corpus vocabulary
2 _ new _, e, n, r, s, t, w, ne, new, _r, _re
2 _re new
1 s e t
1 _re s e t如果继续,下一个合并为:
merge current vocabulary
(_, new) _, e, n, r, s, t, w, ne, new, _r, _re, _new
(_re, new) _, e, n, r, s, t, w, ne, new, _r, _re, _new, _renew
(s, e) _, e, n, r, s, t, w, ne, new, _r, _re, _new, _renew, se
(se, t) _, e, n, r, s, t, w, ne, new, _r, _re, _new, _renew, se, set
2.4.2 BPE 编码器
一旦学到了词表,就用 BPE 编码器对测试句子进行词元化。编码器只是把从训练数据中学到的合并操作运行在测试数据上。它按学习到的顺序贪心执行这些合并。(因此,测试数据中的频率不起作用;起作用的是训练数据中的频率。)首先,我们把每个测试句子中的词分割成字符。然后应用第一条规则:把测试语料中每个 n e 实例替换为 ne;再应用第二条规则:把测试语料中每个 ne w 实例替换为 new,依此类推。
当然,最终许多合并只是重新创建了训练集中已有的词。但这些合并也创建了关于语素的知识,例如前缀 re-(它可能出现在未见过的组合中,如 revisit 或 rearrange),以及没有初始空格的语素 new(因此是词内部的),它可能出现在句首或未见过的词中,如 anew。
实际系统中,BPE 会在非常大的输入语料上运行数万次合并,产生 50,000、100,000,甚至 200,000 个词元的词表。结果是大多数词可以表示为单个词元,只有较罕见的词(以及未知词)才需要由多个词元表示。至少对英语是如此。对于多语言系统,词元可能被英语占据大部分,留给其他语言的词元更少;下面会讨论这一点。
2.4.3 实践中的 BPE
上面的例子展示的是从 ASCII 字节序列学习的简单 BPE。BPE 如何处理 Unicode 输入?通常我们在 UTF-8 编码文本的单个字节上运行 BPE。也就是说,我们把文本的 Unicode 表示看成一串码点,再用 UTF-8 编码成字节,并把每个单独字节作为 BPE 的输入。因此,BPE 很可能一开始会重新发现 UTF-8 用来编码各种码点的 2 字节和常见 3 字节序列。再次强调,只在预先切好的词内部运行 BPE 有助于避免问题。由于一个字节只有 256 个可能取值,不会出现未知词元;不过 BPE 也可能跨字符边界学到一些非法 UTF-8 序列。这些情况非常罕见,可以用过滤器消除。
来看一些大规模系统中所用 BPE 词元化器的工业应用例子,例如 OpenAI GPT-4o 使用的词元化器。这个词元化器有 200K 个词元,规模相对较大。我们可以使用 Tat Dat Duong 的 Tiktokenizer 可视化工具(https://tiktokenizer.vercel.app/)查看给定句子的词元数量。例如,下面是我们编造的一个无意义句子的词元化结果;可视化器用中心点表示空格:

可视化图用颜色区分词,但词元化器的真实输出当然只是一个唯一词元 id 序列。(如果你感兴趣,它们是下面 13 个词元:11865, 8923, 11, 31211, 6177, 23919, 885, 220, 19427, 7633, 18887, 147065, 0。)
注意,大多数词本身就是一个词元,通常包括前导空格。像 's 这样的附着词,在出现在 Jane 这类专名之后时会被切分出来,但在 she's 这类高频词中则被看作词的一部分。数字往往被切成 3 位一组。有些词(如 anyhow)会因出现位置不同而切分不同:句首大写时为两个词元 Any 和 how;出现在空格之后且小写时为一个词元 anyhow。
其中一些现象与预处理步骤有关。如上面简要提到的,语言模型通常在预词元化阶段创建词元:先用正则表达式切分输入,例如在空格和标点处断开,剥离附着词,并把数字分成若干组。第 2.6 节会看到如何使用正则表达式。
也可以改变预词元化,使 BPE 词元跨越多个词。例如 SuperBPE(Liu et al., 2025)和 BoundlessBPE(Schmidt et al., 2025)算法,先通过强制预词元化来归纳常规 BPE 子词词元;然后运行第二阶段 BPE,允许跨空格和标点合并。其结果是一组规模较大且可能更高效的词元(图 2.7)。

实际用于大型语言模型的许多词元化器是多语言的,用许多语言训练。但由于大型语言模型的训练数据绝大部分是英语文本,这些多语言 BPE 词元化器往往把大部分词元用于英语,留给其他语言的词元更少。结果是,它们对英语的词元化效果更好,而其他语言的词往往会被切成更短的词元。比如,我们看一个来自大蕉食谱的西班牙语句子及其英语翻译。
英语句子有 18 个词元;14 个词中的每个词都是一个词元(没有任何词被拆成多个词元):

相比之下,原始西班牙语中的 16 个词被编码成了 33 个词元,数量多得多。注意,许多基本词都被拆成了碎片。例如,hondo(“deep”)被切成 h 和 ondo。类似地,jugo(“juice”)、nuez(“nut”)和 jenjibre(“ginger”)也被拆分:

西班牙语并不是特别低资源的语言;这种过度切分在低资源语言中可能更严重,常常细到单个字符。把文本过度切分成这些很小的词元,会给语言的下游处理造成各种问题。第 8 章介绍 transformer 模型后会更清楚地看到,这样的碎片化可能导致意义表示变差、需要更长上下文,并提高模型训练成本(Rust et al., 2021; Ahia et al., 2023)。
2.5 语料库
词不会凭空出现。我们研究的任何一段具体文本,都是由一个或多个特定说话者或写作者,在某种特定语言的特定方言中,于特定时间、特定地点、为了特定功能而产生的。
也许最重要的变异维度是语言。NLP 算法只有在能适用于多种语言时才最有用。根据在线 Ethnologue 目录(Simons and Fennig, 2018),截至本书写作时,世界上有 7097 种语言。测试算法时,重要的是不要只测试一种语言,尤其应该测试性质不同的语言;相反,目前 NLP 算法常常只在英语上开发或测试,这是一个不幸的倾向(Bender, 2019)。即使算法超越英语进行开发,也往往集中在大型工业化国家的官方语言上(中文、西班牙语、日语、德语等),但我们并不希望工具只局限于这少数语言。此外,大多数语言还有多个变体,常常由不同地区或不同社会群体使用。例如,如果我们处理的文本具有非裔美国英语(AAE)或非裔美国白话英语(AAVE)的特征,也就是数百万非裔美国社区成员可能使用的英语变体(King, 2020),我们就必须使用能够处理这些变体特征的 NLP 工具。Twitter 帖子可能使用非裔美国英语说话者常用的特征,例如 iont(主流美国英语 MAE 中的 I don't)或 talmbout(对应 MAE 的 talking about),这些都会影响词切分(Blodgett et al., 2016; Jones, 2015)。
说话者或写作者在同一句话中使用多种语言也非常常见,这种现象称为语码转换。语码转换在全世界都极其普遍;下面是西班牙语和音译印地语与英语发生语码转换的例子(Solorio et al., 2014; Jurgens et al., 2017):
(2.12) Por primera vez veo a @username actually being hateful! it was beautiful:)
[For the first time I get to see @username actually being hateful! it was beautiful:) ]
(2.13) dost tha or ra- hega ... dont wory ... but dherya rakhe
[“he was and will remain a friend ... don't worry ... but have faith”]
另一个变异维度是体裁。算法需要处理的文本可能来自新闻电讯、小说或非小说类图书、科学论文、维基百科或宗教文本。它可能来自口语体裁,如电话交谈、商务会议、警用随身摄像机、医疗访谈,或电视节目和电影的转写。它也可能来自工作场景,如医生笔记、法律文本,或议会、国会记录。
文本还反映写作者(或说话者)的人口统计特征:年龄、性别、种族、社会经济阶层都会影响我们所处理文本的语言性质。
最后,时间也很重要。语言会随时间变化;对于某些语言,我们拥有来自不同时期的良好文本语料库。
因为语言高度依赖情境,所以在基于语料库开发语言处理计算模型时,必须考虑语言由谁产生、在什么语境中产生、出于什么目的产生。数据集用户如何知道所有这些细节?最好的方法是语料库创建者为每个语料库建立一份数据表(Gebru et al., 2020)或数据声明(Bender et al., 2021)。数据表说明数据集的属性,例如:
- 动机:
- 语料库为什么被收集,由谁收集,由谁资助?
- 情境:
- 文本是在何时、何种情境中写出或说出的?例如,是否有任务?语言原本是口语会话、编辑文本、社交媒体交流,还是独白/对话?
- 语言变体:
- 语料库使用什么语言(包括方言/地区)?
- 说话者人口统计:
- 文本作者的年龄或性别等信息是什么?
- 收集过程:
- 数据有多大?如果是子样本,如何采样?数据是否经同意收集?数据如何预处理?有哪些元数据?
- 标注过程:
- 标注内容是什么?标注者的人口统计特征是什么?他们如何接受训练?数据如何被标注?
- 分发:
- 是否存在版权或其他知识产权限制?
2.6 正则表达式
计算机科学中用于文本处理的最有用工具之一,是正则表达式(regular expression,或 regex),也就是一种用来指定文本字符串的语言。正则表达式用于每一种计算机语言、Unix grep 这样的文本处理工具,以及 vim 或 Emacs 等编辑器。它们也在 BPE 这类词元化算法的预词元化步骤中发挥重要作用。形式上,正则表达式是一种刻画字符串集合的代数记法。实践中,我们可以用正则表达式在文本中搜索某个字符串,也可以指定如何改变该字符串;这两者都是词元化的关键。
我们使用正则表达式在一个字符串中搜索某个模式;这个字符串可以是一行,也可以是一段较长文本。例如,Python 函数
re.search(pattern, string)会扫描字符串,并返回其中与 pattern 匹配的第一个片段。在下面的例子中,我们通常会高亮显示正则表达式精确匹配的字符串,并只显示第一个匹配。我们将使用 Python 语法,用双引号限定原始字符串来表示正则表达式:r"regex"。原始字符串会把反斜杠当作字面字符;这很重要,因为后面介绍的许多正则表达式模式都会使用反斜杠。
正则表达式有不同变体,因此使用在线正则表达式测试器可以帮助确认你的正则表达式确实做了你以为它会做的事情。
2.6.1 字符析取:方括号
最简单的正则表达式是一串普通字符。模式 r"Buttercup" 会匹配任意字符串中的子串 Buttercup(例如字符串 I'm called little Buttercup)。但我们经常需要使用特殊字符。例如,我们可能想匹配某个字符或另一个字符。正则表达式通常区分大小写:r"s" 会匹配小写 s,但不匹配大写 S。要同时匹配 s 和 S,可以使用字符析取运算符,即方括号 [ 和 ]。括号中的字符集合指定要匹配的一组候选字符。例如,图 2.8 表明模式 r"[mM]" 会匹配包含 m 或 M 的模式。
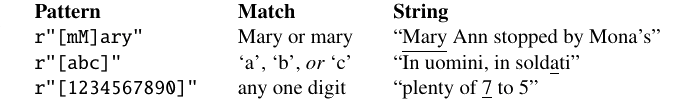
[] 指定字符析取。正则表达式 r"[1234567890]" 指定任意一个数字。这样写可能很笨拙;想象一下为了表示一个大写字母而输入一个列出 A 到 Z 的长模式。因此方括号还可以与短横线(-)一起使用,用来指定某个范围内的任一字符。模式 r"[2-5]" 指定字符 2、3、4 或 5 中的任意一个。模式 r"[b-g]" 指定字符 b、c、d、e、f 或 g 中的一个。图 2.9 给出一些其他例子。

[] 加短横线 - 指定范围。方括号还可以通过脱字符 ^ 来指定某个单字符不能是什么。如果 ^ 是开方括号 [ 后面的第一个符号,所得模式就是取反的。例如,模式 r"[^a]" 会匹配除 a 之外的任意单个字符(包括特殊字符)。只有当脱字符是开方括号后的第一个符号时才有这个意义。如果它出现在别处,通常只是表示一个普通脱字符。图 2.10 给出一些例子。

^ 可用于否定,也可以只是表示 ^。关于用反斜杠转义句点,见下文。2.6.2 计数、可选性与通配符
如果我们想同时匹配 koala 和 koalas,该如何描述可选的 s?不能使用方括号,因为方括号可以表示 “s 或 S”,但不能表示 “s 或什么都没有”。为此我们使用问号 r"?",它表示“前一个字符出现一次或不出现”。因此,r"colou?r" 可以匹配 color 和 colour,r"koalas?" 可以匹配 koala 或 koalas。
还有另一种谈论可能出现也可能不出现元素的方法。考虑某些绵羊的语言,它由如下形式的字符串构成:
baa!
baaa!
baaaa!
...这种绵羊语言由一个 b、至少两个(并且可以任意更多个)a,以及一个感叹号构成。为了表示这种语言,我们将使用一个用星号 * 表示的有用运算符,称为 Kleene 星号(通常读作 “cleany star”)。Kleene 星号表示“紧邻在前的字符或正则表达式出现零次或多次”。因此,r"a*" 表示“由零个或多个 a 构成的任意字符串”。
r"ba*" 能表示绵羊语言吗?它确实会匹配 ba 或 baaaaaa,但有个问题:它也会匹配没有 a 的 b,或只有一个 a 的 ba。这是因为 Kleene 星号表示“零次或多次”。对于绵羊语言,我们需要 r"baaa*",即 b 后跟 aa,再跟零个或多个额外的 a。更复杂的模式也可以重复。因此,r"[ab]*" 表示“零个或多个 a 或 b”(不是“零个或多个右方括号”)。它会匹配 aaaa、ababab、bbbb,以及空字符串。要指定整数(数字串),可以使用 r"[0-9][0-9]*"。(为什么不直接用 r"[0-9]*"?)
有一种稍短的方法可以表示某个字符“至少出现一次”:Kleene 加号 +,它表示“紧邻在前的字符或正则表达式出现一次或多次”。因此,r"[0-9]+" 是指定“一串数字”的常用方法;绵羊语言也可以写成 r"baa+!"。
除了 Kleene 星号和 Kleene 加号,还可以用花括号中的显式数字作为计数器。运算符 r"{3}" 表示“前一个字符或表达式恰好出现 3 次”。因此,r"ax{10}z" 会匹配 a 后跟恰好 10 个 x,再跟 z。
一个重要的特殊字符是句点(r"."),它是一个通配符表达式,可以匹配任意单个字符(换行符除外)。
通配符常与 Kleene 星号一起使用,表示“任意字符构成的任意字符串”。例如,假设我们要找任意一行,其中某个特定词(如 rose)出现两次。可以用正则表达式 r"rose.*rose" 来指定,也就是两个 rose,中间可以有任意种类、零个或多个字符。图 2.11 作了总结。

2.6.3 锚点与边界
锚点是把正则表达式固定到字符串中特定位置的特殊字符。最常见的锚点是脱字符 ^ 和美元符号 $。脱字符 ^ 匹配一行的开头。模式 r"^The" 只在行首匹配词 The。因此,脱字符有三种用途:匹配行首、在方括号中表示否定、以及只是表示普通脱字符。(系统如何根据上下文判断某个脱字符应当发挥哪种功能?)美元符号 $ 匹配行尾。因此,模式 $ 可用来匹配行尾空格,而 r"^The dog\.$" 匹配只包含短语 The dog. 并以句号结束的一行。
注意,前一个例子中必须使用反斜杠,因为我们希望 . 表示“句点”,而不是通配符。相比之下,正则表达式 r"^The dog.$" 会匹配 The dog.,也会匹配 The dog! 和 The dogo。如下文会讨论的,到目前为止定义的所有特殊字符(* + ? . [ ])在想按字面意义使用时都需要加反斜杠。
还有其他锚点:\b 匹配词边界,\B 匹配非词边界。因此,r"\bthe\b" 匹配词 the,但不匹配 other 中的 the。

在正则表达式中,“词”的定义(基于编程语言中的词)是数字、下划线或字母构成的序列。因此,r"\b99\b" 会匹配 There are 99 bottles of beer on the wall 中的字符串 99(因为 99 前面是空格),但不匹配 There are 299 bottles of beer on the wall 中的 99(因为 99 前面是数字)。不过它会匹配 $99 中的 99(因为 99 前面是美元符号 $,它不是数字、下划线或字母)。
注意,所有这些锚点和边界运算符从技术上说都匹配空字符串,这意味着它们不会消耗字符串中的任何字符。模式 r"^The" 中的脱字符匹配 "The" 的开头,但并不会真正越过第一个字符 T。而模式 r"the\b the" 匹配 the the;其中 \b 知道空格是一个边界,但它匹配的是空格之前的空字符串,而不是空格本身,因此空格字符仍然可被后续模式匹配。
2.6.4 析取、分组与优先级
假设我们需要搜索关于宠物的文本,尤其关心猫和狗。此时我们可能想搜索字符串 cat 或字符串 dog。由于不能用方括号来搜索“cat 或 dog”(为什么 r"[catdog]" 不行?),我们需要一个新运算符:析取运算符,也称为管道符号 |。模式 r"cat|dog" 会匹配字符串 cat 或字符串 dog。
有时我们需要在更大的序列中使用析取运算符。例如,假设我想搜索宠物鱼的提及。如何同时指定 guppy 和 guppies?不能简单写成 r"guppy|ies",因为那只会匹配字符串 guppy 和 ies。这是因为像 guppy 这样的序列优先于析取运算符 |。要让析取运算符只作用于特定模式,需要使用括号运算符 ( 和 )。把模式放在括号中,会让它在相邻运算符(如管道符和 Kleene 星号)看来像一个单个字符。因此,模式 r"gupp(y|ies)" 表示我们希望析取只作用于后缀 y 和 ies。
在使用 Kleene 星号等计数器时,括号运算符也很有用。与 | 运算符不同,Kleene 星号默认只作用于一个字符,而不是整个序列。假设我们要匹配某个字符串的重复实例。也许有一行包含形如 Column 1 Column 2 Column 3 的列标签。表达式 r"Column [0-9]+ *" 不会匹配任意数量的列;相反,它只会匹配一个列标签,后面跟任意数量的空格。这里星号只作用于其前面的空格,而不是整个序列。使用括号后,可以写成 r"(Column [0-9]+ +)*",以匹配词 Column 后跟一个数字和空格,整个模式重复零次或多次。
一个运算符可能优先于另一个运算符,因此有时需要括号来指定意图;这一思想由正则表达式的运算符优先级层级形式化。下表给出从最高到最低的优先级顺序:
| 括号 | () |
| 计数器 | * + ? {} |
| 序列和锚点 | the ^my end$ |
| 析取 | | |
因此,由于计数器的优先级高于序列,r"the*" 会匹配 theeeee,但不会匹配 thethe。由于序列的优先级高于析取,r"the|any" 会匹配 the 或 any,但不会匹配 thany 或 theny。
模式还可能以另一种方式产生歧义。考虑表达式 r"[a-z]*",用它去匹配文本 once upon a time。由于 r"[a-z]*" 匹配零个或多个字母,这个表达式可以匹配空字符串,也可以匹配第一个字母 o、on、onc 或 once。在这种情况下,正则表达式总是匹配它能匹配的最大字符串;我们说模式是贪婪的,会尽可能扩展以覆盖更多字符串。
不过,也可以强制非贪婪匹配,这使用限定符 ? 的另一种含义。运算符 *? 是尽可能少匹配文本的 Kleene 星号。运算符 +? 是尽可能少匹配文本的 Kleene 加号。
2.6.5 一个简单例子
假设我们想写一个正则表达式来寻找英语冠词 the。一个简单但不正确的模式可能是:
r"the" (2.14)一个问题是,当这个词出现在句首并因此大写时(即 The),该模式会漏掉它。这可能引导我们写出下面的模式:
r"[tT]he" (2.15)但它仍会过度泛化,错误地返回嵌在其他词中的 the(例如 other 或 there)。因此,我们需要指定两侧都有词边界:
r"\b[tT]he\b" (2.16)刚才这个简单过程,是基于修正两类错误:假阳性,即像 other 或 there 这样被我们错误匹配的字符串;以及假阴性,即像 The 这样被我们错误漏掉的字符串。这两类错误会在语言处理中反复出现。因此,降低某个应用的总体错误率涉及两个相互制约的努力:
- 提高精确率(最小化假阳性)
- 提高召回率(最小化假阴性)
第 4 章会回到精确率和召回率,并给出更精确的定义。
2.6.6 更多运算符
图 2.13 展示了一些常用范围的有用别名。

最后,某些特殊字符用基于反斜杠(\)的特殊记法来表示(见图 2.14)。其中最常见的是换行符 \n 和制表符 \t。
当我们想按字面意义引用特殊字符本身(如 .、*、-、[ 和 \),而不是使用它们的特殊功能时,该怎么做?也就是说,如果我们想匹配句点、星号、方括号或圆括号怎么办?要得到特殊字符的字面意义,需要在它前面加反斜杠,例如 r"\."、r"\*"、r"\[" 和 r"\\"。

2.6.7 替换与捕获组
正则表达式的一个重要用途是替换,即把一个字符串替换为另一个字符串。正则表达式可以帮助我们指定被替换的字符串以及替换内容。在 Python 中,我们使用函数 re.sub()(其他语言和环境中也有类似函数)。
re.sub(pattern, repl, string) 接收三个参数:要搜索的模式、用于替换的替换串,以及在其中进行搜索和替换的字符串。例如,我们可以把 string 中每个 cherry 改成 apricot:
re.sub(r"cherry", r"apricot", string)也可以把某个特定名字的所有实例改为首字母大写:
re.sub(r"janet", r"Janet", string)然而,更常见的是,替换会以更复杂的方式依赖于匹配到的字符串。例如,假设我们有一个文档,所有日期都采用美国格式(mm/dd/yyyy),而我们想把它们改成欧盟和许多其他地区使用的格式(dd-mm-yyyy)。模式 r"\d{2}/\d{2}/\d{4}" 可以匹配一个日期。但如何在替换串中指定我们想交换日期和月份的值?
正则表达式中的工具是捕获组。捕获组使用圆括号来捕获(存储)搜索中匹配到的值,这样就可以在替换中复用它们。我们把一组圆括号放在想捕获的模式部分周围,它就会被存储到一个带编号的组中(组从左到右编号)。然后在 repl 中,用编号命令回指该组。
考虑下面的表达式:
re.sub(r"(\d{2})/(\d{2})/(\d{4})", r"\2-\1-\3", string)我们在两位月份、两位日期和四位年份周围分别放了圆括号,因此前 2 位存储在组 1,第二个 2 位存储在组 2,最后 4 位存储在组 3。随后在 repl 字符串中,用编号运算符 \1、\2 和 \3 回指第一、第二和第三个寄存器。结果会把这样的字符串:
The date is 10/15/2011转换为:
The date is 15-10-2011即使不做替换,捕获组也很有用。例如,我们可以用它们查找重复,这在文本处理中经常需要。为了在字符串中查找重复词,可以使用下面的模式:它搜索一个词,把它捕获到组中,然后在空白之后回指它:
r"\b([A-Za-z]+)\s+\1\b"因此,圆括号在正则表达式中具有双重功能:一方面,它们用于分组,指定运算符应用顺序;另一方面,它们用于捕获匹配。有时我们需要用圆括号分组,却不想捕获所得模式。在这种情况下使用非捕获组,其形式是在开圆括号后加上特殊命令 ?:,即 (?: pattern )。非捕获组通常用于我们只想捕获一个长而复杂模式中的某一部分时。也许我们正在匹配由空格分隔的一串日期(\d\d/\d\d/\d\d\d\d),并且只想提取第 15 个。为了对前 14 个日期使用计数运算符,我们需要圆括号,但不想存储所有无用信息。下面的模式只把第 15 个日期存储在组 1:
r"(?:\d\d/\d\d/\d\d\d\d\s+){14}(\d\d/\d\d/\d\d\d\d)" (2.17)替换和捕获组也可用于实现历史上重要的聊天机器人,如 ELIZA(Weizenbaum, 1966)。回忆一下,ELIZA 通过如下对话模拟罗杰斯式心理学家:
User2: They're always bugging us about something or other.
ELIZA2: CAN YOU THINK OF A SPECIFIC EXAMPLE
User3: Well, my boyfriend made me come here.
ELIZA3: YOUR BOYFRIEND MADE YOU COME HERE
User4: He says I'm depressed much of the time.
ELIZA4: I AM SORRY TO HEAR YOU ARE DEPRESSED
ELIZA 的工作方式,是有一系列或级联的正则表达式替换,每个替换都会匹配并改变输入行的某一部分。输入先被转换为大写,然后替换会把所有 MY 改成 YOUR,把 I'M 改成 YOU ARE,等等。这样,当 ELIZA 回显用户话语的一部分时,就似乎能正确地指向用户。下一组替换会匹配并替换输入中的其他模式,把输入变成完整回应。下面是一些例子:
re.sub(r".* YOU ARE (DEPRESSED|SAD) .*",
r"I AM SORRY TO HEAR YOU ARE \1", input)
re.sub(r".* YOU ARE (DEPRESSED|SAD) .*",
r"WHY DO YOU THINK YOU ARE \1", input)
re.sub(r".* ALWAYS .*",
r"CAN YOU THINK OF A SPECIFIC EXAMPLE", input)2.6.8 前瞻断言
最后,有些时候我们需要“预测未来”:向文本前方查看某个模式是否匹配,但暂时不推进我们在文本中的指针;这样,如果模式出现,就可以处理它,如果没有出现,则可以检查其他内容。
这些前瞻断言使用了上一节非捕获组中见到的 (? 语法。运算符 (?= pattern) 在 pattern 出现时为真,但它是零宽的,也就是说匹配指针不会前进,就像锚点和 \b 这类边界标记一样。运算符 (?! pattern) 只有在某个模式不匹配时才返回真,但同样是零宽的,并且不推进指针。负前瞻常用于解析某个复杂模式时排除一个特殊情况。例如,假设我们想捕获一行中的第一个词,但只在它不以字母 T 开头时捕获。可以用负前瞻做到这一点:
r"^(?![tT])(\w+)\b" (2.18)第一个负前瞻表示这一行不能以 t 或 T 开头,但它匹配的是空字符串,不移动匹配指针。随后捕获组捕获第一个词。
2.6.9 用于 BPE 预词元化的正则表达式
我们在第 2.4 节描述过,在语料库上运行 BPE 词元化算法之前,通常先做预词元化,大致按空白切分语料。随后,BPE 词元化算法在词内部的字符序列上构造词元,而不会跨越词边界进行词元化。
下面这个正则表达式用于一个有影响力的语言模型 GPT-2(Radford et al., 2019)中的预词元化:
r"'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"这是一个相当复杂的正则表达式,也使用了一些尚未介绍的 Unicode 相关高级特性。这些特性属于一个流行的 Python 3 外部库 regex,它比 Python 3 内置的 re 库更强大。
例如,regex 库有特殊的 \p 和 \P 运算符,可根据当前字符是否具有某些 Unicode 码点属性来匹配。例如,\p{L} 匹配任意 Unicode 字母,\P{L} 匹配任意非字母,\p{N} 匹配任意数字,\P{N} 匹配任意非数字。
图 2.15 更清楚地注释了这个正则表达式,也展示了在句子 We're 350 dogs! Um, lunch? 上运行 GPT-2 词元化器的输出。

注意,词元化器把 We're 切分为 We 和 're;标点从 dogs 和 lunch 后面分离出来;有些词元如 dogs 以空格开头,而 We 和 ! 则没有。
2.7 用简单 Unix 工具进行词词元化
对于英语,可以用一个 Unix 命令行完成简单朴素的词词元化和频率计算。正如 Church(1994)指出的,当我们需要快速了解文本语料库时,这很有用。我们将使用一些 Unix 命令:tr 用于系统性地改变输入中的特定字符;sort 按字母顺序排序输入行;uniq 合并并计数相邻的相同行。
例如,假设莎士比亚“全集词”在一个文件 sh.txt 中。我们可以用 tr 通过把每个非字母字符序列改成换行符来词元化这些词('A-Za-z' 表示字母,-c 选项表示取补集,也就是非字母;二者合起来表示把每个非字母字符改成换行符。-s(squeeze)选项用于把多次连续改变的结果压缩为单个输出,因此一串连续非字母字符会被“压缩”为一个换行符):
tr -sc 'A-Za-z' '\n' < sh.txt这个命令的输出是:
THE
SONNETS
by
William
Shakespeare
From
fairest
creatures
...现在每行只有一个词,我们可以排序这些行,并把它们传给 uniq -c,后者会合并并计数:
tr -sc 'A-Za-z' '\n' < sh.txt | sort | uniq -c输出如下:
1945 A
72 AARON
19 ABBESS
25 Aaron
6 Abate
1 Abates
...另一种做法是把所有大写折叠为小写:
tr -sc 'A-Za-z' '\n' < sh.txt | tr A-Z a-z | sort | uniq -c其输出为:
14725 a
97 aaron
1 abaissiez
10 abandon
2 abandoned
2 abase
1 abash
14 abate
...现在可以再次排序,以找到高频词。sort 的 -n 选项表示按数值而不是按字母排序,-r 选项表示反向排序(从高到低):
tr -sc 'A-Za-z' '\n' < sh.txt | tr A-Z a-z | sort | uniq -c | sort -n -r结果表明,和任何其他语料库一样,莎士比亚中最频繁的词是短功能词,如冠词、代词和介词:
27378 the
26084 and
22538 i
19771 to
17481 of
14725 a
13826 you
...这类 Unix 工具在为任何英语语料库快速构建词频统计时非常方便。对于更复杂的任务,我们通常转向前面讨论过的更复杂的词元化算法。
2.8 基于规则的词元化
尽管 BPE 这类基于数据的词元化是最常见的词元化方式,但有些情况下我们希望把词元限制为词,而不是子词。如果我们在英语上运行句法分析算法,而分析器需要语法词作为输入,这可能很有用。对于任何语言学应用,只要我们对想研究的词元有某种先验定义,这也会很有用。对于社会科学应用,如果正字法词是有用的研究对象,它同样有用。
在基于规则的词元化中,我们预先定义一个标准,并实现规则来达成这种词元化。下面以英语词词元化为例。
对于英语,我们有一些期望。我们常常希望把标点分离成独立词元;逗号为分析器提供有用信息,句号有助于指示句子边界。但我们也常常希望保留出现在词内部的标点,例如 m.p.h.、Ph.D.、AT&T 和 cap'n。特殊字符和数字需要保留在价格($45.55)和日期(01/02/06)中;我们不希望把这个价格切成 “45” 和 “55” 两个词元。还有 URL(https://www.stanford.edu)、Twitter 话题标签(#nlproc)和电子邮件地址(someone@cs.colorado.edu)。
数字表达式带来更多复杂性。在英语中,逗号除了出现在词边界处,还会出现在数字内部,每三位一个:555,500.50。不同语言的词元化也不同;例如,西班牙语、法语和德语用逗号标记小数点,用空格(有时用句点)放在英语使用逗号的位置,如 555 500,50。
基于规则的词元化器还可用于展开由撇号标记的附着词缩约形式,把 what're 转换为两个词元 what are,把 we're 转换为 we are。附着词是词的一部分,不能独立存在,只能附着在另一个词上。这样的缩约也出现在其他字母文字语言中,包括法语代词(j'ai)和冠词(l'homme)。
根据应用不同,词元化算法也可能把像 New York 或 rock 'n' roll 这样的多词表达式作为单个词元处理,这需要某种多词表达式词典。因此,基于规则的词元化与命名实体识别密切相关,后者是检测姓名、日期和组织等名称的任务(第 17 章)。
一个常用的词元化标准称为 Penn Treebank 词元化标准,用于 Linguistic Data Consortium(LDC)发布的已分析语料库(树库);LDC 是许多有用数据集的来源。这个标准会分离附着词(doesn't 变为 does 加 n't),保持带连字符的词为一个整体,并分离所有标点(为节省空间,下面用可见空格显示词元之间的分隔,尽管更常见的输出是换行):
Input:
"The San Francisco-based restaurant," they said,
"doesn't charge $10".
Output: " The San Francisco-based restaurant , " they said , " does n't charge $ 10 " .
在实践中,由于词元化先于任何其他语言处理运行,它必须非常快。对于基于规则的词词元化,我们通常使用基于正则表达式的确定性算法,并将其编译为高效的有限状态自动机。例如,图 2.16 展示了一个基本正则表达式,可与 Python 版 Natural Language Toolkit(NLTK)(Bird et al., 2009; https://www.nltk.org)中的 nltk.regexp_tokenize 函数一起用于英语词元化。
精心设计的确定性算法可以处理各种歧义,例如撇号在所有格标记(the book's cover)、引语(`The other class', she said)或 they're 这类附着词中需要采用不同词元化方式。

(?x) verbose 标志告诉 Python 去掉注释和空白。图来自 Bird 等(2009)第 3 章。2.8.1 句子切分
基于规则的切分也常用于另一种词元化过程:句子。句子切分是文本处理中可选应用的一个步骤。当把 NLP 算法用于检测结构的任务(如句法分析结构)时,它尤其重要。
句子切分依赖于语言和体裁。在英语书面文本中,把文本切成句子的最有用线索往往是标点,如句号、问号和感叹号。问号和感叹号是相对无歧义的句子边界标记;简单规则可以在它们出现时切分句子。
另一方面,句点字符 “.” 在句子边界标记和 Dr. 或 Inc. 等缩写标记之间存在歧义。你刚刚读到的前一句就展示了一个更复杂的歧义情况:Inc. 的最后一个句点既标记缩写,也标记句子边界。因此,句子词元化和词词元化可以联合处理。
许多英语句子词元化方法首先决定一个句点是词的一部分还是句子边界标记(通常基于确定性规则,有时也通过机器学习)。缩写词典可以帮助判断句点是否是常用缩写的一部分;这些词典可以手工构建,也可以机器学习得到(Kiss and Strunk, 2006),最终的句子切分器也同样如此。例如,在 Stanford CoreNLP 工具包(Manning et al., 2014)中,句子切分是基于规则的,是词元化的确定性结果:当句末标点(.、! 或 ?)尚未与其他字符组合为一个词元(如缩写或数字),并且后面可选地跟有最终引号或括号时,一个句子结束。
2.9 最小编辑距离
我们经常需要一种方法来比较两个词或字符串有多相似。后续章节会看到,这最常出现在自动语音识别或机器翻译等任务中;在这些任务里,我们想知道某个词序列与参考词序列有多相似。
编辑距离提供了一种量化字符串相似性直觉的方法。更形式化地说,两个字符串之间的最小编辑距离,定义为把一个字符串变成另一个字符串所需的最少编辑操作数(插入、删除、替换等操作)。本节会针对单词介绍编辑距离,但该算法同样适用于整个字符串。
例如,intention 和 execution 之间的差距是 5(删除一个 i,把 n 替换为 e,把 t 替换为 x,插入 c,把 n 替换为 u)。查看字符串距离最重要的可视化方式,也就是两个字符串之间的对齐,会更容易理解这一点,如图 2.17 所示。给定两个序列,对齐是两个序列中子串之间的对应关系。因此,我们说 I 与空字符串对齐,N 与 E 对齐,依此类推。在对齐的字符串下方还有另一种表示:一串符号,用操作列表表示如何把上方字符串转换成下方字符串;d 表示删除,s 表示替换,i 表示插入。
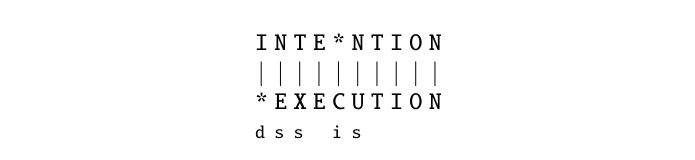
我们还可以给每个操作赋予特定成本或权重。两个序列之间的 Levenshtein 距离是最简单的加权方式,其中三类操作的成本均为 1(Levenshtein, 1966)。我们假设把一个字母替换为自身,例如 t 替换为 t,成本为 0。intention 与 execution 之间的 Levenshtein 距离是 5。Levenshtein 还提出了其度量的另一个版本,其中每次插入或删除成本为 1,但不允许替换。(这等价于允许替换,但给每次替换赋予成本 2,因为任何替换都可表示为一次插入和一次删除。)使用这个版本时,intention 和 execution 之间的 Levenshtein 距离是 8。
2.9.1 最小编辑距离算法
如何找到最小编辑距离?可以把它看成一个搜索任务:搜索从一个字符串到另一个字符串的最短路径,也就是一串编辑操作。

所有可能编辑的空间非常巨大,因此不能朴素搜索。然而,许多不同编辑路径会到达同一个状态(字符串),所以不必每次重新计算所有路径;我们可以在每次看到某个状态时只记住到达该状态的最短路径。这可以通过动态规划完成。动态规划是一类算法的名称,最早由 Bellman(1957)提出,它使用表格驱动方法,通过组合子问题的解来解决问题。自然语言处理中一些最常用的算法都使用动态规划,例如 Viterbi 算法(第 17 章)和用于句法分析的 CKY 算法(第 18 章)。
动态规划问题的直觉是:一个大问题可以通过恰当组合多个子问题的解来解决。考虑图 2.19 所示的转换词最短路径,它表示字符串 intention 与 execution 之间的最小编辑距离。

假设某个字符串(也许是 exention)位于这条最优路径上。动态规划的直觉是:如果 exention 位于最优操作列表中,那么最优序列也必须包含从 intention 到 exention 的最优路径。为什么?如果存在从 intention 到 exention 的更短路径,那么可以改用这条路径,从而得到一条更短的整体路径,这将与原序列最优矛盾。
最小编辑距离算法由 Wagner 和 Fischer(1974)命名,但也由许多人独立发现(见第 17 章历史注记)。
我们先定义两个字符串之间的最小编辑距离。给定两个字符串,源字符串 $X$ 长度为 $n$,目标字符串 $Y$ 长度为 $m$,定义 $D[i,j]$ 为 $X[1..i]$ 与 $Y[1..j]$ 之间的编辑距离,也就是 $X$ 的前 $i$ 个字符与 $Y$ 的前 $j$ 个字符之间的编辑距离。因此,$X$ 和 $Y$ 之间的编辑距离是 $D[n,m]$。
我们将使用动态规划自底向上计算 $D[n,m]$,组合子问题的解。在基本情形中,源子串长度为 $i$ 而目标字符串为空时,把 $i$ 个字符变成 0 个字符需要 $i$ 次删除;目标子串长度为 $j$ 而源字符串为空时,从 0 个字符变成 $j$ 个字符需要 $j$ 次插入。对于较小的 $i,j$ 已经计算出 $D[i,j]$ 后,就可以基于此前计算出的较小值计算更大的 $D[i,j]$。$D[i,j]$ 的值,是取到达该位置的三条可能矩阵路径中的最小值:
上面提到 Levenshtein 距离有两个版本:一个版本替换成本为 1,另一个版本替换成本为 2(即等价于一次插入加一次删除)。这里采用第二个版本,其中插入和删除成本各为 1($\mathrm{ins\mbox{-}cost}(\cdot)=\mathrm{del\mbox{-}cost}(\cdot)=1$),替换成本为 2(但相同字母之间的替换成本为 0)。在这个 Levenshtein 版本下,$D[i,j]$ 的计算为:
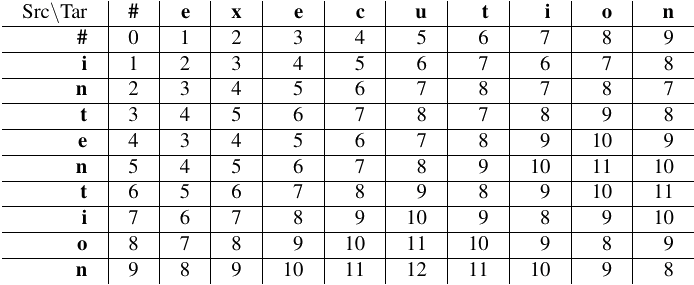
图 2.20 总结了该算法;图 2.21 显示了用式 (2.20) 中的 Levenshtein 版本计算 intention 和 execution 之间距离的结果。

对齐
知道最小编辑距离对一些算法很有用,例如寻找潜在拼写错误的修正。但编辑距离算法还有另一个重要用途:只需小幅修改,它也可以给出两个字符串之间的最小成本对齐。对齐两个字符串在语音和语言处理中都很有用。在语音识别中,最小编辑距离对齐用于计算词错误率(第 15 章)。在机器翻译中,对齐也起作用,因为平行语料库(包含两种语言文本的语料库)中的句子需要彼此匹配。
为了扩展编辑距离算法,使其产生一个对齐,我们可以先把对齐可视化为穿过编辑距离矩阵的一条路径。图 2.22 用粗体单元格展示了这条路径。每个粗体单元格表示两个字符串中的一对字母对齐。如果两个粗体单元格出现在同一行,那么从源到目标会有一次插入;如果两个粗体单元格出现在同一列,则表示一次删除。
图 2.22 也展示了如何计算这条对齐路径的直觉。计算分两步进行。第一步,我们扩展最小编辑距离算法,在每个单元格中存储回指针。单元格中的回指针指向进入当前单元格时来自的前一个单元格(或多个单元格)。图 2.22 示意了这些回指针。有些单元格有多个回指针,因为最小扩展可能来自多个前序单元格。第二步,我们执行回溯。回溯从最后一个单元格(最终行和最终列)开始,沿指针向回穿过动态规划矩阵。从最终单元格到初始单元格的每一条完整路径,都是一个最小距离对齐。习题 2.7 要求你修改最小编辑距离算法,使其存储指针并计算回溯以输出对齐。
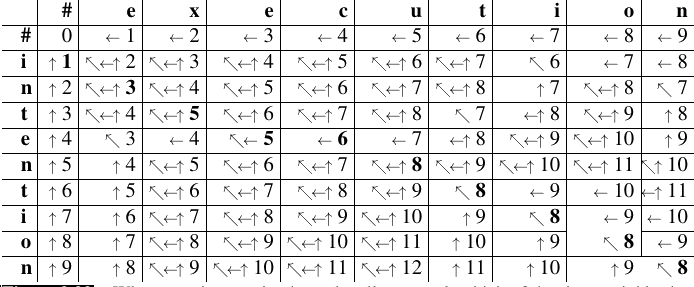
虽然我们的例子使用了简单的 Levenshtein 距离,但图 2.20 中的算法允许对操作赋任意权重。例如在拼写纠错中,键盘上相邻字母之间更可能发生替换。Viterbi 算法是最小编辑距离的概率扩展。它不是计算两个字符串之间的“最小编辑距离”,而是计算一个字符串与另一个字符串之间的“最大概率对齐”。第 17 章会进一步讨论这一点。
2.10 小结
本章介绍了语言处理中词元和词元化的基本概念。我们讨论了词、语素和字符这几个语言学层级,介绍了 Unicode 码点和 UTF-8 编码,介绍了用于词元化的 BPE 算法,还介绍了正则表达式以及用于比较字符串的最小编辑距离算法。下面概括本章关于这些思想的主要内容:
- 词和语素是有用的表示单位,但很难形式化定义。
- Unicode 是一种表示字符的系统,覆盖世界各语言使用的多种文字。
- 每个字符在内部用一个称为码点的唯一 id 表示,并可通过 UTF-8 等编码方法写入文件;UTF-8 是一种变长编码。
- 字节对编码(BPE)是以数据驱动方式归纳词元的标准方法。它是大多数大型语言模型的第一步。
- BPE 词元通常大致具有词或语素的大小,尽管也可能小到单个字符。
- 正则表达式语言是用于模式匹配的强大工具。
- 正则表达式中的基本操作包括符号析取(
[]、|)、计数器(*、+和{n,m})、锚点(^、$)、捕获组(())和替换。 - 两个字符串之间的最小编辑距离,是把一个字符串编辑成另一个字符串所需的最少操作数。最小编辑距离可由动态规划计算,并且计算结果还会给出两个字符串的对齐。
历史注记
关于 Herdan 定律和 Heaps 定律,见 Herdan(1960, p. 28)、Heaps(1978)、Egghe(2007)和 Baayen(2001)。
Unicode 借鉴了 ASCII 和 ISO 字符编码标准。早期草案是在 Xerox 和 Apple 工程师的讨论中形成的。1988 年发布了早期标准草案,1991 年 Unicode 在斯坦福发布了更正式的版本。后来成为 UTF-8 的方案源于 1989 年的 ISO 草案,并有多种扩展。其自同步特性 famously 由 Ken Thompson 于 1992 年在新泽西一家餐馆的餐垫上勾勒出来。
词词元化和其他文本规范化算法从该领域开始时就已被使用。这包括词干提取,例如 Lovins(1968)的广泛使用的词干分析器;也包括数字人文学应用,例如 Packard(1973)的工作,他为古希腊语构建了一个剥离词缀的形态分析器。
BPE 最初是 Gage(1994)提出的一种文本压缩方法,后来由 Sennrich 等(2016)应用于早期神经机器翻译背景下的子词词元化。随后,它在 OpenAI 的 GPT-2(Radford et al., 2019)中被采用为默认词元化方法,也被包含在开源 SentencePiece 库中(Kudo and Richardson, 2018b)。Andrej Karpathy 提供了一个很好的公开实现 minbpe:https://github.com/karpathy/minbpe,他还有一个很受欢迎的 BPE 介绍讲座:https://www.youtube.com/watch?v=zduSFxRajkE。
Kleene 在 1951 年和 1956 年首次基于 McCulloch-Pitts 神经元定义了正则表达式和有限自动机。Ken Thompson 是最早把正则表达式编译器构建到文本搜索编辑器中的人之一(Thompson, 1968)。他的编辑器 ed 包含命令 “g/regular expression/p”,即 Global Regular Expression Print,后来成为 Unix 的 grep 工具。
NLTK 是一个重要工具,既提供有用的 Python 库(https://www.nltk.org),也提供许多算法的教材式描述(Bird et al., 2009),包括文本规范化和语料库接口。
关于编辑距离的更多内容,见 Gusfield(1997)。我们测量 intention 到 execution 编辑距离的例子改编自 Kruskal(1983)。有多种公开可用的软件包可以计算编辑距离,包括 Unix diff 和 NIST 的 sclite 程序(NIST, 2005)。
Bellman(1984)在自传中解释了他最初如何想到 dynamic programming 这个术语:
“……20 世纪 50 年代对数学研究并不是好年月。[那位] 国防部长……对 research 这个词有一种病态的恐惧和厌恶……因此我决定使用 programming 这个词。我想传达这样的想法:这是 dynamic 的,是多阶段的……我想,那就……取一个有绝对精确定义的词,也就是 dynamic……不可能以贬义方式使用 dynamic 这个词。试着想一个可能赋予它贬义的组合,根本不可能。因此,我认为 dynamic programming 是个好名字。它是连国会议员都无法反对的东西。”
习题
- 2.1 为下列语言写出正则表达式。
- 所有字母字符串的集合;
- 所有以 b 结尾的小写字母字符串的集合;
- 来自字母表 $a,b$ 的所有字符串,其中每个 $a$ 都必须紧接在一个 $b$ 之后,并且紧接在一个 $b$ 之前。
- 2.2 为下列语言写出正则表达式。这里的“词”指由空白、相关标点、换行等与其他词分隔开的字母字符串。
- 包含两个连续重复词的所有字符串(例如 “Humbert Humbert” 和 “the the”,但不包括 “the bug” 或 “the big bug”);
- 所有在行首以整数开始、并在行尾以词结束的字符串;
- 所有同时包含词 grotto 和词 raven 的字符串(但不包括像 grottos 这样只是包含 grotto 作为子串的词);
- 写一个模式,把英语句子的第一个词放入寄存器。需要处理标点。
- 2.3 使用本章第 25 页描述的替换方式,实现一个类似 ELIZA 的程序。你可以选择不同于罗杰斯式心理学家的领域,不过要记住,你需要一个允许程序合理地进行大量简单重复的领域。
- 2.4 计算从 “leda” 到 “deal” 的编辑距离(插入成本 1,删除成本 1,替换成本 1)。展示你的计算过程(使用编辑距离网格)。
- 2.5 判断 drive 更接近 brief 还是 divers,并分别给出编辑距离。你可以使用任意版本的距离。
- 2.6 实现一个最小编辑距离算法,并用你手算的结果检查代码。
- 2.7 扩展最小编辑距离算法,使其输出对齐;你需要存储指针,并增加一个阶段来计算回溯。