“你始终令人愉快!” 他微笑着喊道,一边联想,一边我不时鞠躬,而他们看见一辆四匹马拉的马车,便心生向往。
—— 由 Jane Austen 三元语言模型随机生成的句子
3 N-gram 语言模型
俗话说,预测很难,尤其是预测未来。但如果要预测的东西看起来容易得多,比如某人接下来要说的下一个词呢?例如,在下面这段之后,什么词最可能出现?
The water of Walden Pond is so beautifully ...
你也许会认为可能的词是 blue、green 或 clear,而大概不会是 refrigerator 或 this。本章将通过引入 n-gram 语言模型(language model, LM)来形式化这种直觉。语言模型是一种预测后续词的机器学习模型。更正式地说,语言模型为每个可能的下一个词分配概率,或者等价地,给出可能下一个词上的概率分布。语言模型也可以为整个句子分配概率。因此,一个 LM 可以告诉我们,下面这个序列出现在文本中的概率很高:
all of a sudden I notice three guys standing on the sidewalk
而同一组词按另一种顺序排列时,概率则低得多:
on guys all I of notice sidewalk three a sudden standing the
为什么我们要预测后续词?最主要的原因是:大型语言模型正是通过训练它们预测词来构建的。正如第 5–9 章将看到的,大型语言模型仅仅通过从相邻词预测后续词,就能学到关于语言的大量知识。
这种概率知识也非常实用。考虑纠正语法或拼写错误,例如 Their are two midterms,其中 There 被误打成 Their;或者 Everything has improve,其中 improve 应为 improved。There are 比 Their are 更可能,has improved 比 has improve 更可能,因此语言模型可以帮助用户选择更合乎语法的变体。
又如,在语音系统中,要识别你说的是 I will be back soonish 而不是 I will be bassoon dish,知道 back soonish 是概率更高的序列会很有帮助。语言模型还可以用于增强和替代性沟通(augmentative and alternative communication, AAC)(Trnka et al. 2007; Kane et al. 2017)。如果人们因身体原因无法说话或打手语,可以用眼动或其他动作从菜单中选择词。词预测可以用来向菜单推荐可能的词。
本章介绍最简单的一类语言模型:n-gram 语言模型。一个 n-gram 是由 $n$ 个词组成的序列:2-gram(我们称为 bigram)是两个词的序列,如 The water 或 water of;3-gram(三元组,trigram)是三个词的序列,如 The water of 或 water of Walden。不过我们也会有一点术语上的歧义,把 “n-gram” 用来指一种概率模型:它能估计在前 $n-1$ 个词给定时某个词出现的概率,并由此为整个序列分配概率。
在后续章节中,我们会介绍功能强大得多的神经大型语言模型,它们基于第 8 章的 transformer 架构。不过 n-gram 形式化极其简单清晰,因此我们用它来引入大型语言建模中的若干核心概念,包括训练集和测试集、困惑度、采样以及插值。
3.1 N-Grams
先从计算 $P(w\mid h)$ 这个任务开始:即在某个历史 $h$ 给定时,词 $w$ 的概率。假设历史 $h$ 是 “The water of Walden Pond is so beautifully ”,我们想知道下一个词是 blue 的概率:
估计这个概率的一种方法是直接使用相对频率计数:取一个非常大的语料库,数一数 The water of Walden Pond is so beautifully 出现了多少次,再数一数它后面接 blue 的次数。这相当于回答问题:“在我们见到历史 $h$ 的所有情况中,有多少次它后面跟着词 $w$?” 即:
如果语料库足够大,我们就可以计算这两个计数并用式 (3.2) 估计概率。但即使整个互联网也不足以让我们可靠估计完整句子的计数。这是因为语言具有创造性:新的句子一直在被发明出来,我们不能指望像完整句子这样大的对象都能得到准确计数。因此,我们需要更聪明的方法来估计在历史 $h$ 给定时词 $w$ 的概率,或者估计整个词序列 $W$ 的概率。
先引入一些记号。本章仍然沿用 “词” 的说法,尽管实践中语言模型通常是在词元上计算的,例如第 2 章介绍的 BPE 词元。为了表示某个随机变量 $X_i$ 取值为 “the” 的概率,也就是 $P(X_i=\mathrm{the})$,我们简写为 $P(\mathrm{the})$。一个由 $n$ 个词组成的序列可写作 $w_1\ldots w_n$ 或 $w_{1:n}$。因此,$w_{1:n-1}$ 表示字符串 $w_1,w_2,\ldots,w_{n-1}$;我们也会使用等价记号 $w_{\lt n}$,读作 “$w$ 中从 $w_1$ 到 $w_{n-1}$ 的所有元素”。对于序列中每个词都取特定值的联合概率 $P(X_1=w_1,X_2=w_2,X_3=w_3,\ldots,X_n=w_n)$,我们写作 $P(w_1,w_2,\ldots,w_n)$。
那么,如何计算像 $P(w_1,w_2,\ldots,w_n)$ 这样的完整序列概率?一种做法是使用概率的链式法则把它分解:
把链式法则应用到词上,得到
链式法则展示了计算序列联合概率与计算词在前文给定时的条件概率之间的联系。式 (3.4) 表明,我们可以把许多条件概率相乘,来估计整个词序列的联合概率。但链式法则本身似乎并没有真正帮上忙:我们仍然不知道如何精确计算在很长一串前文给定时某个词的概率 $P(w_n\mid w_{1:n-1})$。如前所述,我们不能只靠数语料中每个长字符串后面接每个词的次数来估计,因为语言具有创造性,任何特定上下文都可能从未出现过。
3.1.1 马尔可夫假设
n-gram 模型的直觉是:与其计算一个词在完整历史给定时的概率,不如只用最后几个词来近似这段历史。
例如,bigram 模型用前一个词给定时的条件概率 $P(w_n\mid w_{n-1})$,来近似所有先前词给定时的概率 $P(w_n\mid w_{1:n-1})$。换言之,我们不再计算
而是用下面这个概率近似:
当用 bigram 模型预测下一个词的条件概率时,我们做出如下近似:
认为一个词的概率只依赖于前一个词的假设称为马尔可夫假设。马尔可夫模型是一类概率模型,它假定我们可以在不向过去看太远的情况下预测某个未来单位的概率。我们可以把 bigram(向过去看一个词)推广到 trigram(向过去看两个词),进而推广到 n-gram(向过去看 $n-1$ 个词)。
下面给出 n-gram 近似下一个词条件概率的一般公式。这里用 $N$ 表示 n-gram 的阶数,因此 $N=2$ 表示 bigram,$N=3$ 表示 trigram。于是我们把一个词在完整上下文给定时的概率近似为:
有了单个词概率的 bigram 假设,就可以把式 (3.7) 代入式 (3.4),计算完整词序列的概率:
3.1.2 如何估计概率
如何估计这些 bigram 或 n-gram 概率?一种直观的概率估计方法称为最大似然估计(maximum likelihood estimation, MLE)。我们通过从语料库中获得计数,并把这些计数归一化到 0 和 1 之间,得到 n-gram 模型参数的 MLE 估计。对概率模型来说,归一化就是除以某个总计数,使结果概率落在 0 到 1 之间,并且总和为 1。
例如,要计算给定前一个词 $w_{n-1}$ 时某个词 $w_n$ 的 bigram 概率,我们计算 bigram $C(w_{n-1}w_n)$ 的计数,并用所有共享同一个第一个词 $w_{n-1}$ 的 bigram 计数之和来归一化:
这个公式可以简化,因为所有以给定词 $w_{n-1}$ 开头的 bigram 计数之和,必然等于这个词 $w_{n-1}$ 的 unigram 计数(读者可以花一点时间说服自己这一点):
下面用一个由三个句子组成的小语料走一遍例子。首先需要在每个句子开头加入特殊符号 <s>,从而给第一个词提供 bigram 上下文。我们还需要一个特殊的句末符号 </s>。[注 1]
<s> I am Sam </s>
<s> Sam I am </s>
<s> I do not like green eggs and ham </s>
下面是这个语料中的若干 bigram 概率计算:
对于 MLE n-gram 参数估计的一般情形:
式 (3.12)(和式 (3.11) 一样)通过用某个特定序列的观测频率除以前缀的观测频率来估计 n-gram 概率。这个比率称为相对频率。我们上面说过,用相对频率估计概率是最大似然估计的一个例子。在 MLE 中,得到的参数集合会使训练集 $T$ 在模型 $M$ 给定时的似然最大,也就是最大化 $P(T\mid M)$。例如,假设词 Chinese 在一个一百万词的语料中出现 400 次。那么,从另一篇例如一百万词的文本中随机选一个词,它是 Chinese 的概率是多少?它的 MLE 概率是 $\frac{400}{1000000}$,即 0.0004。0.0004 并不是 Chinese 在所有场景中出现概率的最佳可能估计;在另一个语料或上下文中,Chinese 也许是一个非常不可能出现的词。但它是让 Chinese 在一百万词语料中出现 400 次这一事实最可能的概率。第 3.6 节会介绍如何稍微修改 MLE 估计,以获得更好的概率估计。
接下来看看一个真实但很小的语料例子,它来自已经停用的 Berkeley Restaurant Project:这是上世纪的一个对话系统,用来回答关于加州 Berkeley 餐馆数据库的问题(Jurafsky et al., 1994)。下面是一些用户查询样例(经过文本规范化,包括小写化和去除标点;网站上有 9332 个句子的样本):
can you tell me about any good cantonese restaurants close by
tell me about chez panisse
i'm looking for a good place to eat breakfast
when is caffe venezia open during the day
图 3.1 给出了从文本规范化后的 Berkeley Restaurant Project 句子中得到的一部分 bigram 文法计数。注意,大多数值都是零。实际上,我们特意选择了一组彼此相互关联的样例词;如果从八个随机词中抽取矩阵,矩阵会更加稀疏。
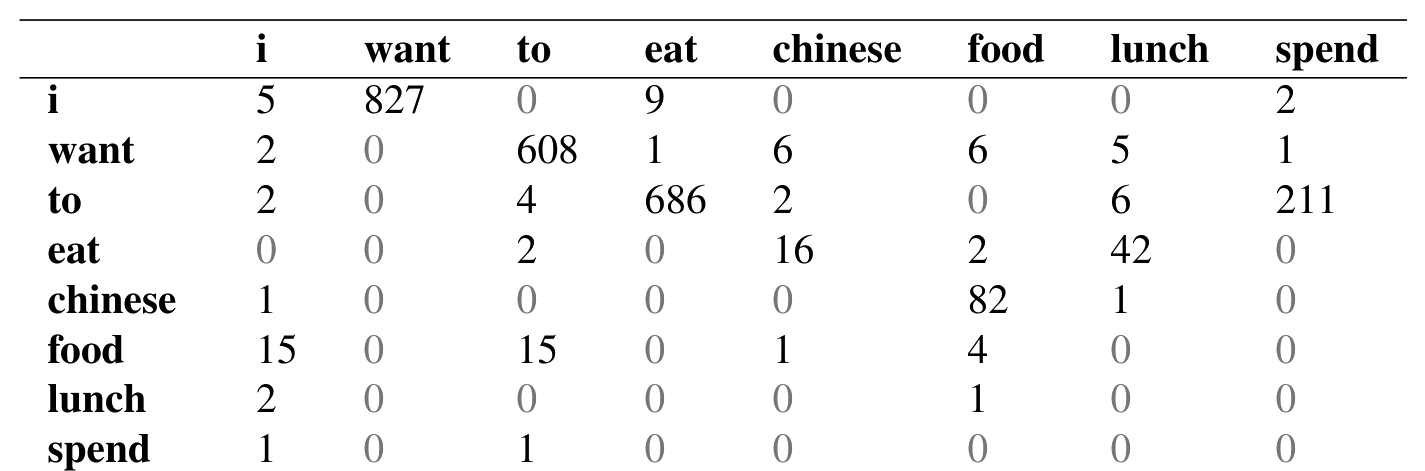
图 3.2 给出了归一化后的 bigram 概率(把图 3.1 中每个单元格除以其所在行对应的 unigram 计数;这些 unigram 计数如下):
| i | want | to | eat | chinese | food | lunch | spend | |
|---|---|---|---|---|---|---|---|---|
| count | 2533 | 927 | 2417 | 746 | 158 | 1093 | 341 | 278 |
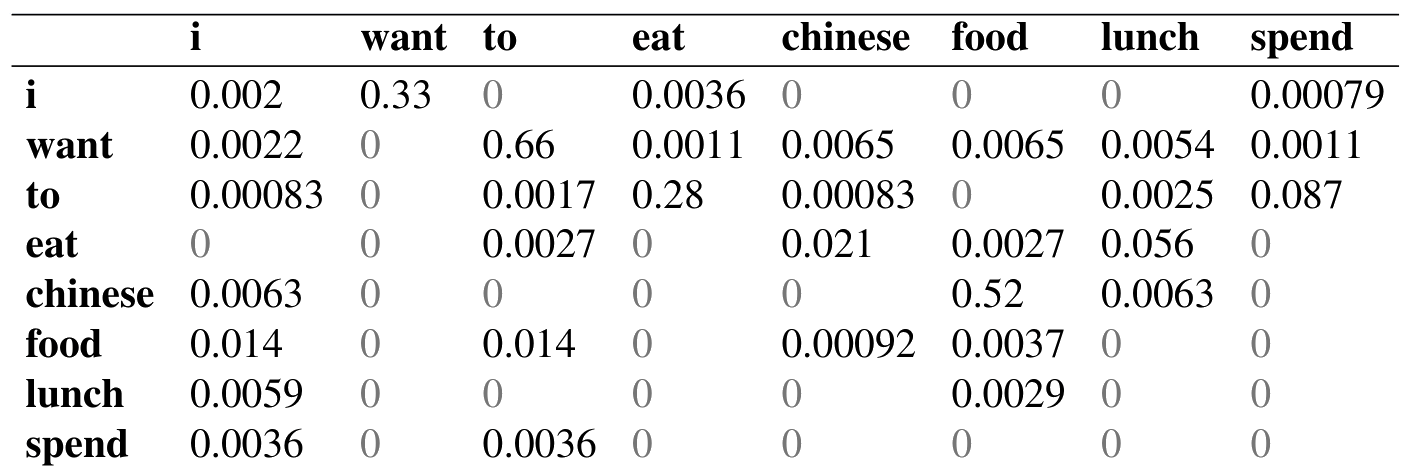
下面还有一些有用的概率:
现在,我们可以通过简单地把相应的 bigram 概率相乘,计算像 I want English food 或 I want Chinese food 这样的句子的概率:
练习 3.2 会让读者计算 i want chinese food 的概率。这些 bigram 统计捕捉了哪些语言现象?上面的一些 bigram 概率编码了我们认为具有严格句法性质的事实,例如 eat 后面通常是名词或形容词,to 后面通常是动词。另一些可能是关于个人助理任务的事实,例如以 I 开头的句子概率很高。还有一些甚至可能是文化事实而非语言事实,例如人们寻找中餐的概率高于寻找英餐。
3.1.3 大规模 n-gram 模型中的尺度问题
在实践中,语言模型可能非常大,因此会带来实际问题。
对数概率
语言模型概率总是在对数空间中存储和计算,称为对数概率。这是因为概率按定义小于等于 1,所以相乘的概率越多,乘积越小。把足够多的 n-gram 概率相乘会导致数值下溢。在对数空间中相加等价于在线性空间中相乘,因此我们通过相加来组合对数概率。使用对数概率相加,而不是直接相乘概率,可以避免结果过小。所有计算和存储都在对数空间完成;如果最后需要报告概率,再对 logprob 取指数转回概率:
本书中,在没有特别说明底数时,$\log$ 都表示自然对数(ln)。
更长的上下文
虽然为了教学目的我们只介绍了 bigram 模型,但在训练数据足够时,我们会使用 trigram 模型,即以前两个词为条件;也会使用 4-gram 或 5-gram 模型。对于这些更大的 n-gram,需要在句子左右两端假设额外上下文。例如,为了计算句首的 trigram 概率,我们会为第一个 trigram 使用两个伪词(即 $P(I\mid \mathtt{\langle s\rangle\langle s\rangle})$)。
人们已经构建了一些大型 n-gram 数据集,例如从 Corpus of Contemporary American English(COCA)中抽取的一百万个最高频 n-gram;COCA 是一个精心整理的 10 亿词美国英语语料库(Davies, 2020)。还有 Google 的 Web 5-gram 语料库,来自 1 万亿词的英文网页文本(Franz and Brants, 2006);以及 Google Books Ngrams 语料库,包含来自中文、英文、法文、德文、希伯来文、意大利文、俄文和西班牙文的 8000 亿个词元(Lin et al., 2012a)。
甚至可以使用极长范围的 n-gram 上下文。infini-gram($\infty$-gram)项目(Liu et al., 2024)允许任意长度的 n-gram。其思想是避免昂贵的巨大 n-gram 计数表预计算(无论空间还是时间都昂贵)。相反,它使用一种称为后缀数组的高效表示,在推理时快速计算任意 $n$ 的 n-gram 概率。这使得在 5 万亿词元的超大语料上计算各种长度的 n-gram 成为可能。
构建大型 n-gram 语言模型时,效率考虑非常重要。标准做法包括:只用 4–8 bit 对概率量化(而不是 8 字节浮点数);把词字符串存储在磁盘上,在内存中只用 64 位哈希表示;用特殊数据结构如 “反向 trie” 表示 n-gram。也常常对 n-gram 语言模型做剪枝,例如只保留计数高于某个阈值的 n-gram,或者用熵来剪掉较不重要的 n-gram(Stolcke, 1998)。KenLM 这样的高效语言模型工具包(Heafield 2011; Heafield et al. 2013)使用排序数组,并用归并排序以最少的语料遍历次数高效构建概率表。
3.2 评估语言模型:训练集和测试集
评估语言模型性能的最佳方式,是把它嵌入到应用中,并衡量应用提升了多少。这种端到端评估称为外在评估。外在评估是判断语言模型(或任何组件)的某个改进是否真正有助于当前任务的唯一方法。因此,对于作为语音识别或机器翻译等任务组件的 n-gram 语言模型,我们可以通过分别使用两个候选语言模型运行语音识别器或机器翻译器,再看哪一个给出更准确的转写或翻译,来比较它们的性能。
遗憾的是,端到端运行大型 NLP 系统往往非常昂贵。因此,拥有一个可以快速评估语言模型潜在改进的指标会很有帮助。内在评估指标是在独立于任何应用的情况下衡量模型质量的指标。下一节将介绍困惑度(perplexity),它是衡量语言模型性能的标准内在指标,既用于简单的 n-gram 语言模型,也用于第 8 章中更复杂的神经大型语言模型。
为了评估任何机器学习模型,我们至少需要三个不同的数据集:训练集、开发集和测试集。
训练集是我们用来学习模型参数的数据;对于简单 n-gram 语言模型,它就是我们从中获得计数、再把计数归一化为 n-gram 概率的语料。
测试集是另一个不同的、保留出的数据集,它不与训练集重叠,用来评估模型。我们需要一个独立的测试集,才能无偏地估计训练出的模型在应用到某个新的未知数据集时能泛化得多好。一个机器学习模型如果完美记住训练数据,却在其他任何数据上表现糟糕,那么当我们要把它用于新的数据或问题时就没有多大用处。因此,我们通过 n-gram 模型在这个未见过的测试集或测试语料上的表现来衡量其质量。
应该如何选择训练集和测试集?测试集应当反映我们希望模型用于的语言。如果要把语言模型用于化学课讲座的语音识别,测试集就应当是化学课讲座文本。如果要把它作为中文酒店预订请求英译系统的一部分,测试集就应当是酒店预订请求文本。如果希望语言模型是通用的,那么测试集就应当从多种文本中抽取。在这种情况下,我们可能会从不同来源收集大量文本,再把它们划分为训练集和测试集。划分时要谨慎:如果构建的是通用模型,就不希望测试集只由一篇文档或一位作者的文本组成,因为那样不能很好衡量通用性能。
因此,如果给定一个文本语料,并希望比较两个不同 n-gram 模型的性能,我们就把数据划分为训练集和测试集,并在训练集上训练两个模型的参数。然后比较这两个训练好的模型对测试集的拟合程度。
但 “拟合测试集” 是什么意思?标准答案很简单:哪个语言模型给测试集分配更高概率,也就是更准确地预测测试集,哪个模型就更好。给定两个概率模型,更好的模型是那个更能预测测试数据细节的模型,因此它会给测试数据分配更高概率。
由于我们的评估指标基于测试集概率,重要的是不要让测试句子进入训练集。假设我们试图计算某个 “测试” 句子的概率。如果这个测试句子是训练语料的一部分,那么当它出现在测试集中时,我们会错误地给它分配人为偏高的概率。我们称这种情况为在测试集上训练,也称为数据污染。在测试集上训练会引入偏差,使概率看起来全部偏高,并导致下面将介绍的基于概率的指标困惑度出现巨大误差。
即使我们没有在测试集上训练,如果在做出不同修改后反复在测试集上测试语言模型,也可能通过观察哪些修改使模型变好,而隐式地调到测试集的特征。因此,通常只有在确信模型已经准备好之后,才希望在测试集上运行一次,或者极少数几次。
出于这个原因,我们通常会有第三个数据集,称为开发测试集或开发集(devset)。直到最后之前,我们所有测试都在这个数据集上做;最后才在测试集上测试一次,看看模型到底有多好。
如何把数据划分为训练集、开发集和测试集?我们希望测试集尽可能大,因为太小的测试集可能偶然不具代表性;但也希望有尽可能多的训练数据。最低限度上,我们应当选取能够给出足够统计功效、从而测量两个候选模型之间统计显著差异的最小测试集。开发集应当和测试集来自同一类文本,这一点很重要,因为它的目标是估计我们在测试集上的表现。
3.3 评估语言模型:困惑度
上面说过,我们根据哪个语言模型给测试集分配更高概率来评估语言模型。更好的模型更擅长预测后续词,因此测试集中每个词出现时,它会更少 “惊讶”,也就是给每个词分配更高概率。实际上,一个完美语言模型会正确猜出语料中的每个下一个词,给它概率 1,并给所有其他词概率 0。因此,给定一个测试语料,更好的语言模型会给它分配比差模型更高的概率。
但实际上,我们通常不用原始概率作为评估语言模型的指标。原因是测试集(或任意序列)的概率依赖于其中词或词元的数量;文本越长,测试集概率越小。我们需要一个按词归一化、按长度标准化的指标,这样才能比较不同长度的文本。这样的指标确实存在:它是概率的一个函数,称为困惑度,既用于评估大型语言模型,也用于评估 n-gram 模型。
一个语言模型在测试集上的困惑度(常缩写为 PP 或 PPL)是测试集概率的倒数(一除以测试集概率),再按词(或词元)数归一化。因此它有时也叫逐词或逐词元困惑度。我们通过取第 $N$ 次方根来按词数 $N$ 归一化。对于测试集 $W=w_1w_2\ldots w_N$:
也可以用链式法则展开 $W$ 的概率:
注意,由于式 (3.15) 中有倒数,词序列概率越高,困惑度越低。因此,模型在数据上的困惑度越低,模型越好。最小化困惑度等价于按照语言模型最大化测试集概率。困惑度为什么使用倒数?这是因为困惑度最初来自信息论中交叉熵率的定义;感兴趣的读者可以阅读第 3.7 节的进阶解释。现在只需要记住:困惑度与概率成反比。
计算测试集 $W$ 困惑度的细节取决于使用哪种语言模型。下面是使用 unigram 语言模型时 $W$ 的困惑度(也就是 unigram 概率倒数的几何平均):
使用 bigram 语言模型计算 $W$ 的困惑度时,仍然是几何平均,不过现在取的是 bigram 概率的倒数:
式 (3.15) 或式 (3.17) 中通常使用的词序列,是某个测试集中的完整词序列。由于这个序列会跨越许多句子边界,如果词汇表包含句间词元 <EOS>,或者包含单独的句首、句末标记 <s> 和 </s>,那么我们可以把它们纳入概率计算。如果这样做,就也要在总词元数 $N$ 中按每个句子加入一个词元。[注 2]
上面提到,困惑度是文本和语言模型二者的函数:给定文本 $W$,不同语言模型会有不同困惑度。因此,困惑度可以用来比较不同语言模型。下面的例子中,我们在 Wall Street Journal 报纸的 3800 万词上训练了 unigram、bigram 和 trigram 模型。然后分别用式 (3.16)、式 (3.17) 以及 trigram 的对应公式,在一个 WSJ 测试集上计算各模型的困惑度。下表给出每个语言模型在 150 万词测试集上的困惑度:
| Unigram | Bigram | Trigram | |
|---|---|---|---|
| Perplexity | 962 | 170 | 109 |
如上所示,n-gram 提供的关于词序列的信息越多,它分配给字符串的概率就越高。trigram 模型比 unigram 模型更少惊讶,因为它更清楚接下来可能出现哪些词,因此给这些词分配更高概率。概率越高,困惑度越低(正如式 (3.15) 所示,困惑度与模型给测试序列分配的概率成反比)。因此,较低困惑度说明语言模型是测试集的更好预测器。
注意,计算困惑度时,语言模型必须在不知道测试集的情况下构建,否则困惑度会人为偏低。并且,只有两个语言模型使用完全相同词汇表时,它们的困惑度才可比较。
困惑度上的(内在)改进,并不保证语音识别或机器翻译等语言处理任务性能上的(外在)改进。尽管如此,由于困惑度通常与任务改进相关,它常被用作方便的评估指标。只要可能,模型困惑度的改进仍应通过真实任务上的端到端评估来确认。
3.3.1 困惑度作为加权平均分支因子
困惑度也可以理解为一种语言的加权平均分支因子。语言的分支因子是任意一个词后面可能出现的下一个词的数量。考虑一个小型人工语言,它是确定性的(没有概率),任意词都可以跟在任意词后面,词汇表只有三种颜色:
这个语言的分支因子是 3。
现在构造同一个 LM 的概率版本,称为 $A$,其中每个词以相同概率 $\frac{1}{3}$ 跟在其他词后面(它是在三种颜色计数相等的训练集上训练出来的),并设测试集 $T=$ “red red red red blue”。
先确认一下:如果在这个测试集(或任何这样的测试集)上计算这个人工颜色语言的困惑度,确实得到 3。根据式 (3.15),$A$ 在 $T$ 上的困惑度为:
但现在假设在另一个 LM $B$ 的训练集中,red 非常常见,因此 $B$ 有如下概率:
我们应当预期同一个测试集 red red red red blue 对语言模型 $B$ 的困惑度更低,因为大多数时候下一个颜色会是 red,它非常可预测,也就是概率很高。因此测试集概率会更高,而困惑度与概率成反比,所以困惑度会更低。于是,尽管分支因子仍为 3,困惑度或加权分支因子更小:
3.4 从语言模型中采样句子
可视化一个语言模型体现了什么知识的重要方法之一,是从中采样。从分布中采样指的是按概率大小随机选择点。因此,从语言模型中采样,也就是从一个句子分布中采样,意味着生成一些句子,并按照模型定义的概率选择每个句子。于是,模型认为概率高的句子更可能被生成,模型认为概率低的句子较不可能被生成。
这种通过采样来可视化语言模型的技术,很早由 Shannon (1948) 以及 Miller and Selfridge (1950) 提出。最容易说明的是 unigram 情形。想象英语中的所有词覆盖 0 到 1 之间的数轴,每个词覆盖一个与其频率成比例的区间。图 3.3 显示了一个可视化例子,它使用的是从本书文本计算出的 unigram LM。我们在 0 和 1 之间选择一个随机值,找到它在概率线上的位置,并输出包含该值的区间对应的词。我们不断选择随机数并生成词,直到随机生成句末词元 </s>。
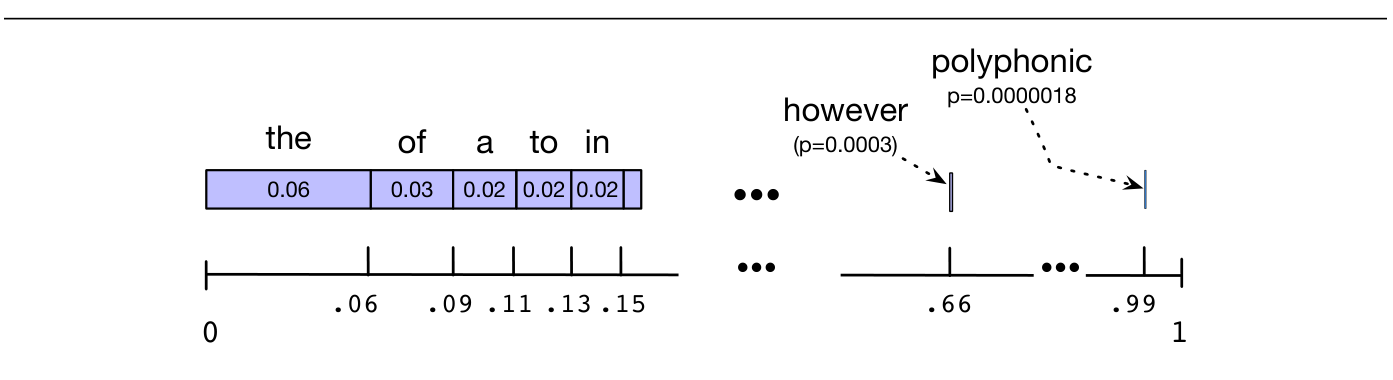
我们可以用同样技术生成 bigram:先按 bigram 概率生成一个以 <s> 开头的随机 bigram。假设该 bigram 的第二个词是 $w$。接着选择一个以 $w$ 开头的随机 bigram(同样按其 bigram 概率抽取),依此类推。
3.5 泛化与过拟合训练集
n-gram 模型像许多统计模型一样依赖训练语料。其一个含义是,这些概率常常编码某个训练语料的特定事实。另一个含义是,随着 $n$ 值增大,n-gram 会越来越好地建模训练语料。
我们可以用上一节的采样方法把这两个事实可视化。为了直观展示高阶 n-gram 的能力逐渐增强,图 3.4 给出了用 Shakespeare 作品训练出的 unigram、bigram、trigram 和 4-gram 模型随机生成的句子。
上下文越长,句子越连贯。unigram 句子中的词彼此没有连贯关系,也没有句末标点。bigram 句子有一些局部的词到词连贯性(尤其当标点也被当作词时)。trigram 句子开始看起来很像 Shakespeare。实际上,4-gram 句子看起来有点太像 Shakespeare 了。It cannot be but so 直接来自 King John。原因是,并非要贬低 Shakespeare,而是就语料而言,他的作品规模并不大($N=884,647,V=29,066$),而我们的 n-gram 概率矩阵极其稀疏。仅 bigram 就有 $V^2=844,000,000$ 种可能;4-gram 的可能数量是 $V^4=7\times10^{17}$。因此,一旦生成器选中了前三元组 It cannot be,第 4 个元素就只有七个可能的下一个词(but, I, that, thus, this 以及句号)。

为了理解对训练集的依赖,再看一下用完全不同语料训练出的 LM:Wall Street Journal(WSJ)报纸。Shakespeare 和 WSJ 都是英语,所以也许我们会预期两种体裁的 n-gram 有一些重叠。图 3.5 给出了用 4000 万词 WSJ 训练出的 unigram、bigram 和 trigram 模型生成的句子。

把这些例子与图 3.4 中的伪 Shakespeare 比较。虽然二者都在建模 “类似英语的句子”,但生成句子没有重叠,甚至短语层面的重叠也很少。如果训练集和测试集像 Shakespeare 与 WSJ 这样不同,统计模型作为预测器就相当无用。
构建 n-gram 模型时应如何处理这个问题?一个步骤是确保训练语料与我们要完成的任务具有相似体裁。要为法律文档翻译构建语言模型,就需要法律文档训练语料。要为问答系统构建语言模型,就需要问题语料。
获得适当方言或变体的训练数据同样重要,尤其是在处理社交媒体帖子或口语转写时。例如,有些推文会使用非裔美国英语(African American English, AAE)的特征;AAE 是非裔美国社群中使用的多种语言变体的总称(King, 2020)。这些特征可以包括其他变体中没有的词,如表示立即将来时的助动词 finna,或把 then 拼作 den,如下列推文所示(Blodgett and O'Connor, 2017):
(3.22) Bored af den my phone finna die!!!
而来自英语系语言的推文,如 Nigerian Pidgin,其词汇和 n-gram 模式又与美国英语明显不同(Jurgens et al., 2017):
(3.23)@username R u a wizard or wat gan sef: in d mornin - u tweet,
afternoon - u tweet, nyt gan u dey tweet. beta get ur IT
placement wiv twitter
测试集中仍然可能包含训练时从未见过的词吗?如果词 Jurafsky 从未出现在训练集中,却出现在测试集中,会发生什么?答案是,尽管词可能没见过,我们通常并不是在词上运行 NLP 算法,而是在子词词元上运行。使用子词词元化(如第 2 章中的 BPE 算法),任何词都可以被建模为一串已知的小子词;必要时,也可以是一串对应单个字母的词元。因此,虽然本章为方便起见一直说 “词”,语言模型词汇表通常是词元集合而不是词集合。这样,测试集就永远不会包含未见过的词元。
3.6 平滑、插值与回退
使用最大似然估计来估计概率有一个问题:任何有限训练语料都会漏掉一些完全可以接受的英语词序列。也就是说,某个 n-gram 从未在训练数据中出现,却可能出现在测试集中。也许我们的训练语料中包含 ruby 和 slippers 两个词,但碰巧没有短语 ruby slippers。
这些未见序列或零项,也就是训练集中没有出现但测试集中出现的序列,会带来两个问题。第一,它们意味着我们低估了可能出现的词序列的概率,从而损害任何要在这些数据上运行的应用。第二,如果测试集中任意词在上下文中的概率为 0,那么整个测试集的概率就是 0。困惑度基于测试集概率的倒数定义。因此,如果某些上下文中的词具有零概率,我们完全无法计算困惑度,因为不能除以零。
处理这种理论上应当具有非零概率的 “零概率 n-gram” 的标准方法,称为平滑或折扣。平滑算法会从一些更频繁事件上削去一点概率质量,并把它分配给未见事件。这里介绍几种简单平滑算法:Laplace(加一)平滑、stupid backoff,以及 n-gram 插值。
3.6.1 Laplace 平滑
最简单的平滑方法是在归一化为概率之前,给所有 n-gram 计数加一。所有原来为零的计数现在变为 1,原来为 1 的计数变为 2,依此类推。这种算法称为Laplace 平滑。Laplace 平滑的效果不足以用于现代 n-gram 模型,但它有助于引入许多其他平滑算法中也会出现的概念,提供有用的基线,并且也是文本分类等其他任务中的实用平滑算法(附录 K)。
先从把 Laplace 平滑应用到 unigram 概率开始。回忆一下,词 $w_i$ 的未平滑最大似然 unigram 概率,是其计数 $c_i$ 除以词元总数 $N$:
Laplace 平滑只是给每个计数加一(因此也叫加一平滑)。由于词汇表中有 $V$ 个词,每个词都被加了一次,我们还必须调整分母,以计入额外的 $V$ 个观测。(如果不增加分母,我们的 $P$ 值会发生什么?)
有了 unigram 情形的直觉,现在来平滑 Berkeley Restaurant Project 的 bigram。图 3.6 给出图 3.1 中 bigram 的加一平滑计数。
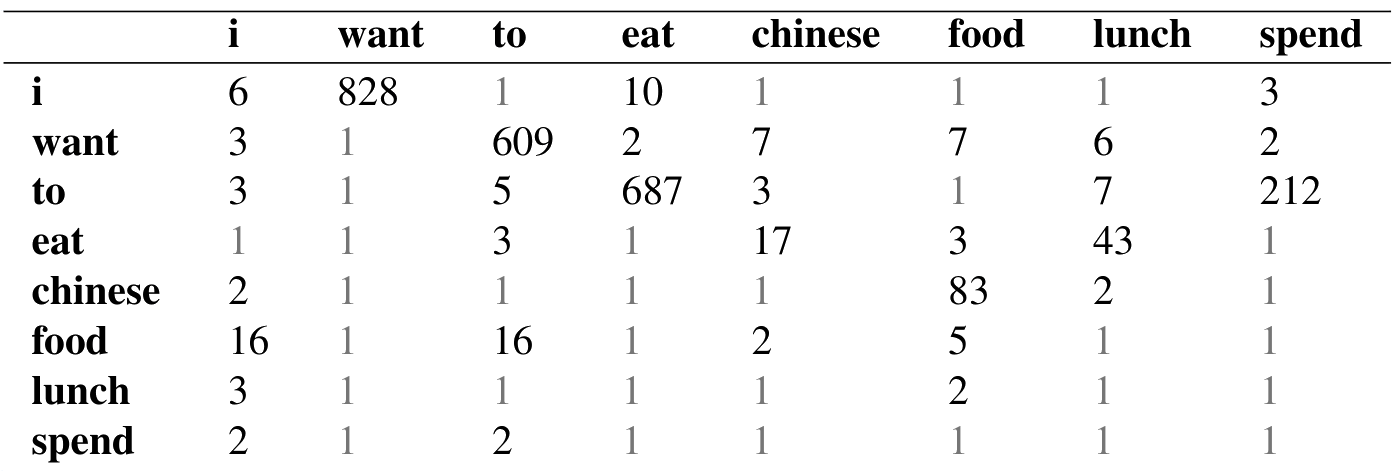
图 3.7 给出了用下方式 (3.26) 计算的图 3.2 中 bigram 的加一平滑概率。回忆普通 bigram 概率通过用 unigram 计数归一化每行计数来计算:
对于加一平滑的 bigram 计数,我们需要把分母中的 unigram 计数增加词汇表中词类型总数 $V$。下面的公式说明了原因:它明确写出分母中的 unigram 计数实际上是所有以 $w_{n-1}$ 开头的 bigram 计数之和。由于我们给每个这样的计数都加一,而一共有 $V$ 个,所以分母总共要加 $V$:
因此,第 42 页给出的每个 unigram 计数都需要增加 $V=1446$。使用式 (3.26) 的结果就是图 3.7 中的平滑 bigram 概率。
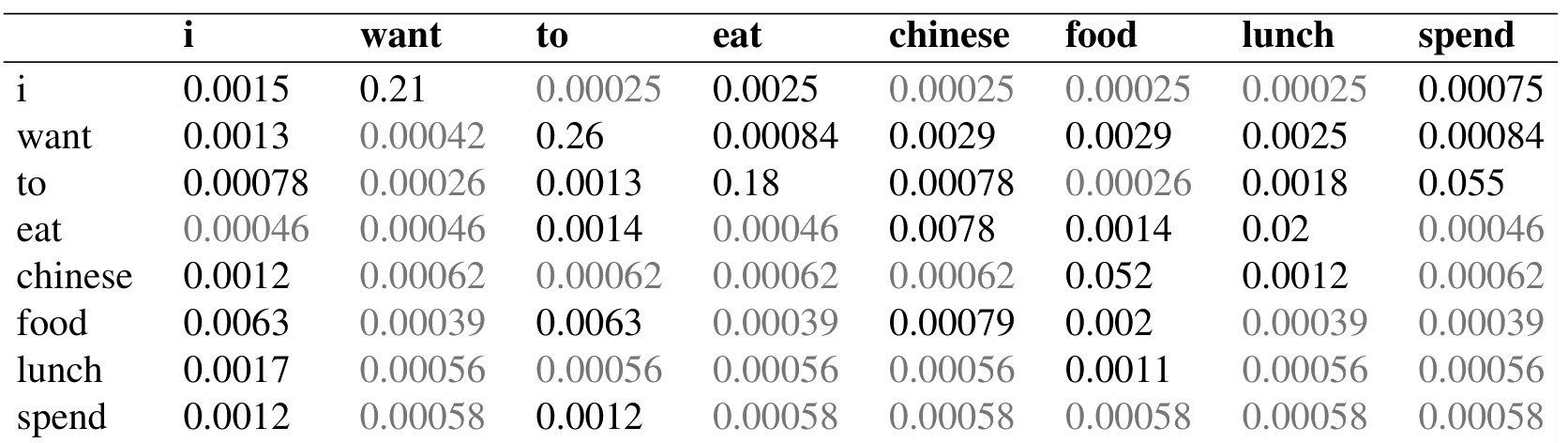
一个有用的可视化技巧,是重构一个调整后的计数矩阵,从而观察平滑算法对原始计数造成了多大改变。这个调整后的计数 $C^*$ 是这样一个计数:如果它除以 $C(w_{n-1})$,就会得到平滑概率。这个调整计数更容易与 MLE 计数直接比较。也就是说,Laplace 概率也可以表示为调整计数除以式 (3.25) 中的未平滑分母:
整理各项,可以解出 $C^*(w_{n-1}w_n)$:
图 3.8 展示了由式 (3.27) 计算出的重构计数。
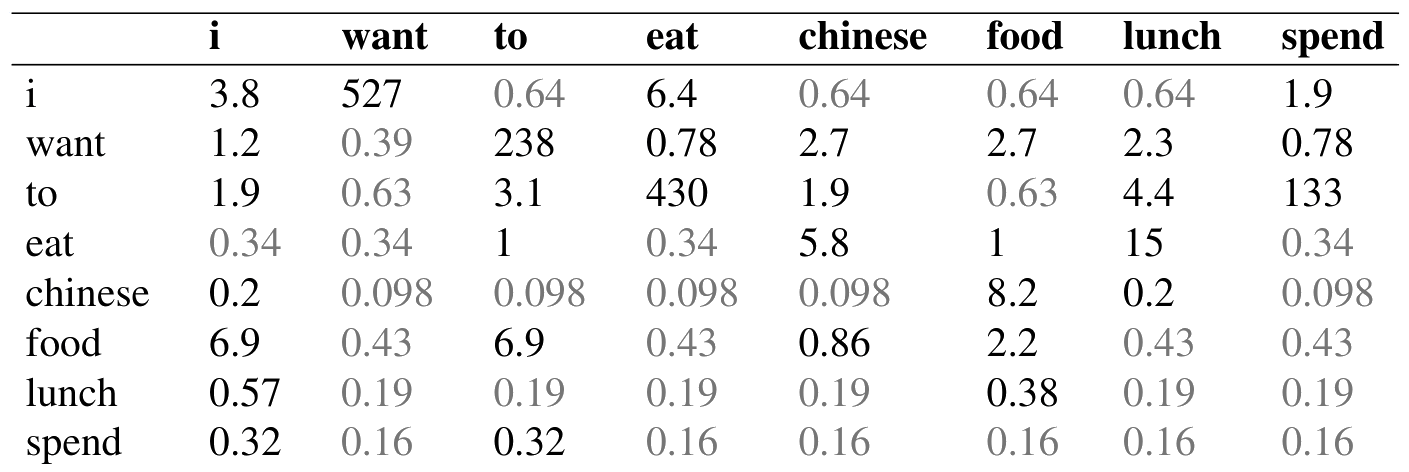
注意,加一平滑对计数做出了非常大的改变。比较图 3.8 与图 3.1 的原始计数,可以看到 $C(want\ to)$ 从 608 变成了 238。从概率空间也可以看到这一点:$P(to\mid want)$ 从未平滑情形的 0.66 降到平滑情形的 0.26。考察折扣 $d$,也就是新旧计数之比,可以看出每个前缀词的计数被削减得多么显著;bigram want to 的折扣是 0.39,而 Chinese food 的折扣是 0.10,相差 10 倍。这个剧烈变化发生的原因是太多概率质量被转移给了所有零项。
3.6.2 加 $k$ 平滑
加一平滑的一种替代方法,是把更少一点的概率质量从已见事件移到未见事件。与其给每个计数加 1,不如加一个分数计数 $k$(0.5?0.01?)。因此这个算法称为加 $k$ 平滑。
加 $k$ 平滑需要一种选择 $k$ 的方法,例如可以在开发集上优化。虽然加 $k$ 对某些任务(包括文本分类)有用,但事实证明它仍然不适合语言建模,会产生方差很差的计数以及常常不合适的折扣(Gale and Church, 1994)。
3.6.3 语言模型插值
为解决零频 n-gram 问题,我们还可以利用另一种知识来源。如果要计算 $P(w_n\mid w_{n-2}w_{n-1})$,但没有见过某个特定 trigram $w_{n-2}w_{n-1}w_n$ 的例子,就可以改用 bigram 概率 $P(w_n\mid w_{n-1})$ 来估计。同样,如果没有足够计数计算 $P(w_n\mid w_{n-1})$,可以退回 unigram $P(w_n)$。换言之,在模型对某些上下文学得不多时,使用更少上下文有时反而能帮助泛化。
使用这种 n-gram 层级结构最常见的方式称为插值:通过对 trigram、bigram 和 unigram 概率进行加权组合,计算新的概率。在简单线性插值中,我们对不同阶的 n-gram 做线性插值。因此,我们用 unigram、bigram 和 trigram 概率的混合来估计 trigram 概率 $P(w_n\mid w_{n-2}w_{n-1})$,每项由一个 $\lambda$ 加权:
这些 $\lambda$ 必须和为 1,因此式 (3.29) 等价于加权平均。在线性插值的一个稍复杂版本中,每个 $\lambda$ 权重都以上下文为条件来计算。这样,如果某个特定 bigram 的计数特别可靠,我们就假设基于这个 bigram 的 trigram 计数也更可信,于是可以让这些 trigram 的 $\lambda$ 更高,在插值中赋予该 trigram 更大权重。式 (3.30) 给出上下文条件权重插值公式,其中每个 $\lambda$ 的参数都是前两个词构成的上下文:
这些 $\lambda$ 值如何设定?简单插值和条件插值中的 $\lambda$ 都从一个保留语料中学习。保留语料是额外的训练语料,因为我们把它从训练数据中留出,用来设定这些 $\lambda$ 值。[注 3] 具体做法是选择使保留语料似然最大的 $\lambda$ 值。也就是说,固定 n-gram 概率,然后搜索一组 $\lambda$,使其代入式 (3.29) 后给保留集分配最高概率。有多种方法可以找到这组最优 $\lambda$。一种方法是使用 EM 算法,这是一种迭代学习算法,会收敛到局部最优的 $\lambda$(Jelinek and Mercer, 1980)。
3.6.4 Stupid Backoff
插值的另一种替代方法是回退。在回退模型中,如果我们需要的 n-gram 计数为零,就回退到 $(n-1)$-gram 来近似。我们持续回退,直到遇到某个有计数的历史。为了让回退模型给出正确的概率分布,必须对高阶 n-gram 做折扣,为低阶 n-gram 留出一些概率质量。实践中,人们常常不做折扣,而使用一种简单得多的无折扣回退算法,称为 stupid backoff(Brants et al., 2007)。
Stupid backoff 放弃了让语言模型成为真正概率分布的想法。它不对高阶概率折扣。如果高阶 n-gram 的计数为零,就简单地回退到低一阶 n-gram,并乘以一个固定的、与上下文无关的权重。这个算法不产生概率分布,因此沿用 Brants et al. (2007) 的记号,把它称为 $S$:
回退最终止于 unigram,其分数为 $S(w)=\frac{\mathrm{count}(w)}{N}$。Brants et al. (2007) 发现 $\lambda=0.4$ 效果很好。
3.7 进阶:困惑度与熵的关系
第 3.3 节引入困惑度,用来在测试集上评估 n-gram 模型。更好的 n-gram 模型会给测试数据分配更高概率,而困惑度是测试集概率的归一化版本。困惑度度量实际上来自信息论中的交叉熵概念;它解释了困惑度一些原本神秘的性质(例如为什么取倒数概率)以及它与熵的关系。熵是信息量的一种度量。给定一个随机变量 $X$,它在我们要预测的对象集合上取值(词、字母、词性等),这个集合记作 $\chi$,并有一个概率函数 $p(x)$,则随机变量 $X$ 的熵为:
原则上,对数可以使用任意底数。如果使用以 2 为底的对数,得到的熵值单位是 bit。
理解熵的一种直观方式是:在最优编码方案中,编码某个决策或某段信息所需 bit 数的下界。考虑标准信息论教材 Cover and Thomas (1991) 中的一个例子。假设我们想赌马,但去 Yonkers Racetrack 太远,于是希望给下注经纪人发一条短消息,告诉他八匹马中该押哪一匹。编码这条消息的一种方法,是直接用马编号的二进制表示作为代码;这样,1 号马为 001,2 号马为 010,3 号马为 011,依此类推,8 号马编码为 000。如果我们一整天都在下注,并且每匹马都用 3 bit 编码,那么平均每场比赛要发送 3 bit。
能不能做得更好?假设赔率分布就是投注的真实分布,我们把它表示为每匹马的先验概率:
| Horse 1 | $\frac{1}{2}$ | Horse 5 | $\frac{1}{64}$ |
| Horse 2 | $\frac{1}{4}$ | Horse 6 | $\frac{1}{64}$ |
| Horse 3 | $\frac{1}{8}$ | Horse 7 | $\frac{1}{64}$ |
| Horse 4 | $\frac{1}{16}$ | Horse 8 | $\frac{1}{64}$ |
随机变量 $X$ 在马匹上取值,其熵给出了 bit 数下界:
可以构造一个平均每场比赛 2 bit 的编码:对更可能的马使用较短编码,对较不可能的马使用较长编码。例如,可以把最可能的马编码为 0,其余马分别编码为 10、110、1110、111100、111101、111110 和 111111。
如果每匹马等可能又会怎样?上面已经看到,如果用等长二进制码表示马号,每匹马需要 3 bit,平均也是 3。熵是否相同?此时每匹马的概率都是 $\frac{1}{8}$。马匹选择的熵为:
到目前为止,我们一直在计算单个变量的熵。但我们使用熵的大多数场景都涉及序列。例如,对一个文法而言,我们会计算某个词序列 $W=\{w_1,w_2,\ldots,w_n\}$ 的熵。做法之一是定义一个在词序列上取值的变量。例如,可以计算某个语言 $L$ 中所有长度为 $n$ 的词序列上的随机变量熵:
我们可以把熵率(也可以理解为逐词熵)定义为该序列熵除以词数:
但要度量一种语言的真实熵,需要考虑无限长序列。如果把语言看作一个随机过程 $L$,它产生词序列,并让 $W$ 表示词序列 $w_1,\ldots,w_n$,那么 $L$ 的熵率 $H(L)$ 定义为:
Shannon-McMillan-Breiman 定理(Algoet and Cover 1988; Cover and Thomas 1991)指出,如果语言在某些方面是规则的(准确地说,如果它既平稳又遍历):
也就是说,我们可以取一个足够长的单个序列,而不必对所有可能序列求和。
Shannon-McMillan-Breiman 定理的直觉是:一个足够长的词序列会包含许多其他较短序列,并且这些较短序列会按照其概率在长序列中重复出现。
如果一个随机过程为序列分配的概率对于时间索引平移保持不变,就称这个过程是平稳的。换言之,时间 $t$ 处词的概率分布与时间 $t+1$ 处的概率分布相同。马尔可夫模型,以及 n-gram,都是平稳的。例如在 bigram 中,$P_i$ 只依赖于 $P_{i-1}$。如果把时间索引平移 $x$,$P_{i+x}$ 仍然只依赖于 $P_{i+x-1}$。但自然语言并不平稳,因为正如附录 D 所示,后续词的概率可以依赖于任意遥远且与时间有关的事件。因此,我们的统计模型只能近似自然语言的正确分布和熵。
总结来说,通过做出一些不正确但方便的简化假设,我们可以取某个随机过程输出的很长样本,并计算其平均对数概率,从而计算该随机过程的熵。
现在可以引入交叉熵了。当我们不知道生成某些数据的真实概率分布 $p$ 时,交叉熵很有用。它允许我们使用某个 $m$,也就是 $p$ 的一个模型(对 $p$ 的近似)。$m$ 在 $p$ 上的交叉熵定义为:
也就是说,我们按概率分布 $p$ 抽取序列,但求和时使用这些序列在 $m$ 下的概率的对数。
同样,根据 Shannon-McMillan-Breiman 定理,对于平稳遍历过程:
这意味着,和熵一样,我们可以通过取一个足够长的单个序列,而不是对所有可能序列求和,来估计模型 $m$ 在某个分布 $p$ 上的交叉熵。
交叉熵有用之处在于,$H(p,m)$ 是熵 $H(p)$ 的上界。对任意模型 $m$:
这意味着,我们可以用某个简化模型 $m$ 来帮助估计按概率 $p$ 抽取的符号序列的真实熵。$m$ 越准确,交叉熵 $H(p,m)$ 就越接近真实熵 $H(p)$。因此,$H(p,m)$ 和 $H(p)$ 之间的差距是模型准确度的度量。对于两个模型 $m_1$ 和 $m_2$,更准确的模型将是交叉熵更低的模型。(交叉熵永远不可能低于真实熵,所以模型不会因为低估真实熵而出错。)
最后可以看到困惑度与式 (3.40) 中交叉熵的关系。交叉熵定义在观测词序列长度趋于无穷的极限中。我们用一个足够长但固定长度的序列来近似这个交叉熵。模型 $M=P(w_i\mid w_{i-N+1:i-1})$ 在词序列 $W$ 上的交叉熵近似为:
模型 $P$ 在词序列 $W$ 上的困惑度现在可以正式定义为 2 的该交叉熵次方:
3.8 小结
本章通过 n-gram 模型引入了语言建模。n-gram 是经典模型,可以帮助我们介绍语言建模中的许多基本概念。
- 语言模型提供了一种为句子或其他词/词元序列分配概率的方法,也提供了一种根据前面的词或词元预测下一个词或词元的方法。
- N-gram 也许是最简单的语言模型。它们是马尔可夫模型,使用一个固定窗口中的先前词估计当前词。n-gram 模型可以通过在训练语料中计数并归一化计数来训练(最大似然估计)。
- N-gram 语言模型可以用困惑度在测试集上评估。
- 一个测试集相对于某个语言模型的困惑度,是测试集概率的函数:也就是模型给测试集分配概率的倒数,再按长度归一化。
- 从语言模型中采样,意味着生成一些句子,并按照模型定义的概率选择每个句子。
- 平滑算法提供了一种为训练中未见事件估计概率的方法。n-gram 常用平滑算法包括加一平滑,或通过插值利用低阶 n-gram 计数。
历史注记
n-gram 的底层数学最早由 Markov (1913) 提出。他使用现在称为马尔可夫链的模型(bigram 和 trigram)来预测 Pushkin 的 Eugene Onegin 中下一个字母会是元音还是辅音。Markov 把 20,000 个字母分类为 V 或 C,并计算在前一个或前两个字母给定时,某个字母为元音的 bigram 和 trigram 概率。Shannon (1948) 使用 n-gram 来计算英文词序列的近似。基于 Shannon 的工作,到 20 世纪 50 年代,马尔可夫模型已常用于工程、语言学和心理学中的词序列建模。在一系列极具影响力的论文中,从 Chomsky (1956) 开始,包括 Chomsky (1957) 和 Miller and Chomsky (1963),Noam Chomsky 认为 “有限状态马尔可夫过程” 虽然可能是有用的工程启发式方法,却无法成为人类语法知识的完整认知模型。这些论点使许多语言学家和计算语言学家在数十年里忽视统计建模工作。
n-gram 语言模型的复兴来自 IBM Thomas J. Watson Research Center 的 Fred Jelinek 及其同事,以及 CMU 的 James Baker。前者受到 Shannon 的影响;后者受到 Leonard Baum 及其同事在美国国防分析研究所(IDA)等实验室关于这些主题的早期机密工作的影响,这些工作后来解密。两个实验室几乎同时独立地在语音识别系统中成功使用 n-gram(Baker 1975b; Jelinek et al. 1975; Baker 1975a; Bahl et al. 1983; Jelinek 1990)。“language model” 和 “perplexity” 这两个术语最早由 IBM 团队用于这项技术。Jelinek 及其同事使用 language model 一词的方式相当现代:它指影响词序列概率的整套语言因素,包括语法、语义、篇章乃至说话人特征,而不仅仅是特定的 n-gram 模型本身。
加一平滑源自 Laplace 1812 年的继承法则(law of succession),并由 Jeffreys (1948) 基于 Johnson (1932) 更早的 Add-K 建议,首次作为零频问题的工程解决方案使用。Gale and Church (1994) 总结了加一算法的问题。
20 世纪 80 和 90 年代提出了多种不同语言建模和平滑技术,包括 Good-Turing 折扣(由 Katz 在 IBM 首次应用于 n-gram 平滑;Nádas 1984; Church and Gale 1991)、Witten-Bell 折扣(Witten and Bell, 1991),以及多种基于类别的 n-gram 模型,它们使用词类信息。20 世纪 90 年代后期开始,Chen 和 Goodman 进行了多项严格控制的实验,比较不同算法和参数(Chen and Goodman 1999; Goodman 2006 等)。他们展示了 Modified Interpolated Kneser-Ney 的优势;这种方法在世纪之交成为 n-gram 语言建模的标准基线,尤其因为他们还表明缓存和基于类别的模型只带来很小的额外改进。SRILM(Stolcke, 2002)和 KenLM(Heafield 2011; Heafield et al. 2013)是公开可用的 n-gram 语言模型构建工具包。
大型语言模型基于神经网络而不是 n-gram,这使它们能够解决 n-gram 的两个主要问题:(1)参数数量随 n-gram 阶数增加而指数增长;(2)除非训练样例和测试样例使用完全相同的词,n-gram 无法从训练样例泛化到测试样例。神经语言模型则把词投影到连续空间中,使具有相似上下文的词具有相似表示。第 8 章会介绍基于 transformer 的大型语言模型;在此过程中,第 6 章会介绍前馈语言模型(Bengio et al. 2006; Schwenk 2007),第 13 章会介绍循环语言模型(Mikolov, 2012)。
练习
- 3.1 写出 trigram 概率估计公式(修改式 3.11)。然后写出第 41 页 I am Sam 语料中所有非零 trigram 概率。
- 3.2 计算句子
i want chinese food的概率。给出两个概率:一个使用图 3.2 以及第 43 页其下方的 “有用概率”,另一个使用图 3.7 中的加一平滑表。假设额外的加一平滑概率为 $P(i\mid \mathtt{\langle s\rangle})=0.19$ 且 $P(\mathtt{\langle/s\rangle}\mid food)=0.40$。 - 3.3 你在上一题中计算出的两个概率中,哪一个更高,未平滑的还是平滑的?解释原因。
- 3.4 给定下面这个由本章语料修改而来的语料:
使用带加一平滑的 bigram 语言模型,求 $P(Sam\mid am)$。像处理其他词元一样,把<s> I am Sam </s>
<s> Sam I am </s>
<s> I am Sam </s>
<s> I do not like green eggs and Sam </s><s>和</s>也计入计数。 - 3.5 假设我们没有使用句末符号
</s>。在下面的训练语料上训练一个未平滑 bigram 文法,不使用句末符号</s>:
证明你的 bigram 模型没有在所有句长上分配一个单一概率分布:展示字母表 $\{a,b\}$ 上所有可能的 2 词句子的概率之和为 1.0,而所有可能的 3 词句子的概率之和也为 1.0。<s> a b
<s> b b
<s> b a
<s> a a - 3.6 假设我们在某个给定语料上训练一个带加一平滑的 trigram 语言模型。语料包含 $V$ 个词类型。用各种 n-gram 计数和 $V$ 表达一个估计 $P(w_3\mid w_1,w_2)$ 的公式,其中 $w_3$ 是跟在 bigram $(w_1,w_2)$ 后面的词。使用记号 $c(w_1,w_2,w_3)$ 表示 trigram $(w_1,w_2,w_3)$ 在语料中出现的次数,bigram 和 unigram 依此类推。
- 3.7 给定下面这个由本章语料修改而来的语料:
如果在最大似然 bigram 模型和最大似然 unigram 模型之间使用线性插值平滑,且 $\lambda_1=\frac{1}{2}$、$\lambda_2=\frac{1}{2}$,那么 $P(Sam\mid am)$ 是多少?像处理其他词元一样,把<s> I am Sam </s>
<s> Sam I am </s>
<s> I am Sam </s>
<s> I do not like green eggs and Sam </s><s>和</s>也计入计数。 - 3.8 写一个程序计算未平滑的 unigram 和 bigram。
- 3.9 在你选择的两个不同小语料上运行你的 n-gram 程序(可以使用邮件文本或新闻组)。比较两个语料的统计量。两者最常见 unigram 有什么区别?有趣的 bigram 差异又有哪些?
- 3.10 为你的程序添加生成随机句子的选项。
- 3.11 为你的程序添加计算测试集困惑度的选项。
- 3.12 给定一个由 100 个数字组成的训练集,其中 91 个是 0,其余数字 1–9 各出现 1 次。现在看到如下测试集:
0 0 0 0 0 3 0 0 0 0。unigram 困惑度是多少?