4 逻辑回归与文本分类
在它遥远的书页中写道,动物可以分为: (a)属于皇帝的,(b)制成木乃伊的,(c)受过训练的,(d)乳猪, (e)美人鱼,(f)传说中的,(g)流浪狗,(h)包含在此分类中的, (i)像疯了一样颤抖的,(j)数不清的,(k)用极细的骆驼毛笔画出的, (l)其他,(m)刚打破花瓶的,(n)远看像苍蝇的。 Borges (1964)
分类处在语言处理和智能的核心。识别一个字母、一个词或一张脸,分拣邮件,给作业打分,这些都是把某个输入分配到某个类别中的例子。博尔赫斯用一部神话式古代百科全书中荒诞的动物分类,著名地展示了分类问题的难处。
好在语言处理中使用的类别通常比博尔赫斯的类别容易定义。本章介绍用于分类的逻辑回归算法,并将它用于文本分类(text categorization):给一段文本或一个文档分配标签或类别。我们会重点讨论一种文本分类任务:情感分析(sentiment analysis),即判断作者对某个对象表达的是正向还是负向态度。电影、图书或产品评论表达作者对产品的态度;社论或政治文本表达作者对行动或候选人的态度。因此,抽取情感与市场营销、政治分析等许多领域相关。
对于把文本标注为正向或负向立场的二分类任务,词本身常常非常有信息量。例如在电影或餐馆评论中,awesome、love 这样的词通常支持正向类别,而 awful、ridiculously 这样的词则支持负向类别:
+ … awesome caramel sauce and sweet toasty almonds. I love this place!
- … awful pizza and ridiculously overpriced…
文本分类任务有很多。垃圾邮件检测把电子邮件分到 spam 或 not-spam;语言识别判断文本使用的是哪种语言;作者归属判断文本作者,这既和人文学科相关,也和司法鉴定相关。
分类之所以重要,还有一个原因:语言建模也可以看作分类。每个词都可以看成一个类别,预测下一个词就是把目前为止的上下文分类到“下一个词”的各个类别中。这个直觉也是大型语言模型的基础之一。
本章介绍的逻辑回归在多方面都很重要。第一,逻辑回归与神经网络关系密切。第6章会看到,神经网络可以看作一系列叠在一起的逻辑回归分类器。第二,逻辑回归引入了神经网络和语言模型中的基本概念,例如 sigmoid 和 softmax 函数、logit,以及用于学习的核心算法梯度下降。最后,逻辑回归也是社会科学和自然科学中最重要的分析工具之一。
4.1 机器学习与分类
分类的目标是取一个输入(每个输入称为一个观测,observation),抽取输入中有用的特征或属性,然后把这个观测分类到一组离散类别之一。我们把输入记为 $\vct{x}$,输出来自一个固定的类别集合
目标是返回 $Y$ 中的一个预测类别。有时也会把输出类别集合记作 $C$。
在情感分析中,输入 $\vct{x}$ 可以是一条评论或其他文本,输出集合 $Y$ 可以是
也可以是
在语言识别中,输入是一段需要判断语种的文本,而输出集合 $Y$ 是语言集合,例如
分类有许多方法。一种方法是使用人工编写的规则。例如:
如果词 “love” 出现在 $\vct{x}$ 中,并且它前面没有 “don't”,则分类为 positive。
手写规则可以作为现代 NLP 系统的组成部分;后面会看到,情感分析中也会使用正向词和负向词的人工词表。但规则很脆弱,场景或数据一变就可能失效;而且很多任务中不同特征之间存在复杂交互,例如上面规则中的 “don't” 否定,因此人很难写出能在许多情形下都成功的规则。
另一种方法是向大型语言模型提示(prompt)文本并要求它给出标签。提示方法很强大,但也有弱点:语言模型可能幻觉,而且未必能解释为什么选择某个类别。
因此,分类最常见的做法是监督式机器学习(supervised machine learning)。在监督式机器学习中,除了输入和输出类别集合,还需要一个带标签训练集和一个学习算法。训练集包含一组输入观测,每个观测都与正确输出(监督信号)关联。对于文本分类,训练集可表示为 $m$ 个输入/输出对;每个输入 $\vct{x}$ 是文本,每个文本都人工标注了对应的正确类别:
带括号的上标表示训练集中的单个观测或实例。情感分类的训练集可以是一组句子或文本,每个文本有正确的情感标签。
目标是从训练集中学到一个分类器,使它能把新的输入 $\vct{x}$ 映射到正确类别 $y\in Y$。分类器通过学习训练句子中的特征来做到这一点,例如 awesome 或 awful 这样的词。逻辑回归这类概率分类器不仅给出类别,还给出观测属于该类别的概率。类别上的概率分布常常对下游决策有用;在组合多个系统时,尽量推迟离散决策也很有价值。
逻辑回归这样的概率分类器有四个组成部分:
- 输入的特征表示。对每个输入观测 $\vct{x}^{(i)}$,这会是一个特征向量 $[x_1,x_2,…,x_n]$。第 $j$ 个输入的第 $i$ 个特征可写作 $x_i^{(j)}$,有时简写为 $x_i$;也会看到 $f_i$、$f_i(x)$,或多分类时的 $f_i(c,x)$。
- 分类函数。它为每个输出类别 $y_i$ 计算概率 $P(y=y_i|\vct{x})$,从而计算估计类别。本章会介绍用于分类的 sigmoid 和 softmax。
- 学习时要优化的目标函数。通常是最小化一个与训练样例误差对应的损失函数。本章介绍交叉熵损失。
- 优化目标函数的算法。本章介绍随机梯度下降算法。
从最高层看,逻辑回归以及几乎所有概率机器学习分类器都有两个阶段:
- 训练: 对逻辑回归而言,就是使用随机梯度下降和交叉熵损失来训练权重 $\vct{w}$ 和偏置 $b$。
- 测试: 对测试样例 $\vct{x}$,计算每个输出类别 $y_i$ 的概率 $P(y=y_i|\vct{x})$。根据概率向量返回概率更高的标签,例如 $y=1$ 或 $y=0$。
逻辑回归既可以把观测分类到两个类别之一(例如正向情感和负向情感),也可以分类到多个类别之一。二分类情形的数学更简单,因此接下来的几节先讨论二分类逻辑回归,从 sigmoid 函数开始;第4.7节再转向多于两个类别的多项逻辑回归,以及 softmax 函数。
4.2 sigmoid 函数
二元逻辑回归的目标是训练一个能对新输入观测做二元决策的分类器。这里介绍 sigmoid 分类器,它帮助我们做这个决策。
考虑一个输入观测 $\vct{x}$,用特征向量 $[x_1,x_2,…,x_n]$ 表示。分类器输出 $y$ 可以为 1(表示该观测属于该类)或 0(表示不属于该类)。我们想知道该观测属于该类的概率 $P(y=1|\vct{x})$。例如决策可以是“正向情感”对“负向情感”,特征可以表示文档中的词计数,$P(y=1|\vct{x})$ 是文档为正向情感的概率,$P(y=0|\vct{x})$ 是文档为负向情感的概率。
逻辑回归通过从训练集中学习一个权重向量和一个偏置项来解决这个问题。每个权重 $w_i$ 是实数,并与输入特征 $x_i$ 关联。$w_i$ 表示该输入特征对分类决策的重要程度,可以为正(为正类提供证据),也可以为负(为负类提供证据)。因此在情感任务中,awesome 可能具有很高的正权重,而 abysmal 可能具有很大的负权重。偏置项(bias term,也叫截距 intercept)是另一个加到加权输入上的实数。
在训练得到权重之后,为了对测试实例做决策,分类器先把每个 $x_i$ 乘以相应权重 $w_i$,把所有加权特征求和,再加上偏置 $b$。得到的单个数字 $z$ 表示该类别证据的加权和:
本书后面会用线性代数中的点积记号表示这类求和。两个向量 $\vct{a}$ 和 $\vct{b}$ 的点积 $\vct{a}\cdot\vct{b}$ 是对应元素乘积之和。于是式(4.2)可等价写为
但是式(4.3)并不保证 $z$ 是合法概率,即位于 0 和 1 之间。因为权重是实数,输出甚至可能为负;$z$ 的范围是 $-\infty$ 到 $\infty$。
为了得到概率,我们把 $z$ 传入 sigmoid 函数 $\sigma(z)$。sigmoid 因形状像字母 S 得名,也叫 logistic 函数,逻辑回归的名称也由此而来:
其中 $\exp(x)$ 表示 $e^x$。
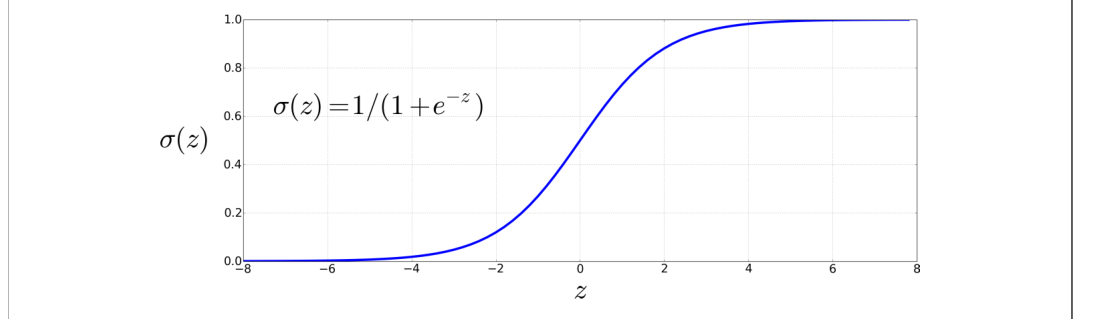
sigmoid 有几个优点:它把实数映射到 $(0,1)$,正好适合作为概率;它在 0 附近近似线性,在两端逐渐变平,因此倾向于把离群值压到 0 或 1;并且它可微,这在第4.15节推导学习规则时会很方便。
如果把 sigmoid 作用于加权特征和,就得到 0 到 1 之间的数。要把它变成概率,只需要保证两种情形 $P(y=1)$ 和 $P(y=0)$ 之和为 1:
sigmoid 函数满足
因此 $P(y=0)$ 也可写成 $\sigma(-(\vct{w}\cdot\vct{x}+b))$。
最后说明两个术语。第一,sigmoid 函数的输入,即式(4.3)中的分数 $z=\vct{w}\cdot\vct{x}+b$,常称为 logit。这是因为 logit 函数是 sigmoid 的反函数;logit 是 odds ratio 的对数:
把 $z$ 称为 logit,是在提醒我们:用 sigmoid 把范围为 $-\infty$ 到 $\infty$ 的 $z$ 转为概率时,我们实际上把 $z$ 解释为对数几率,而不是任意实数。
第二,在二分类中,通常把 sigmoid 输出 $\sigma(\vct{w}\cdot\vct{x}+b)$(也就是 $P(y=1)$)称为 $\hat{y}$,读作 “y hat”。因此 $\hat{y}$ 表示“输入观测属于正类的概率”。第4.7节介绍多项或 softmax 逻辑回归时,$\hat{y}$ 会扩展为覆盖所有输出类别的概率向量;二分类时只保留一个标量概率,因为另一个概率总能由 $1-P(y=1)$ 得到。
4.3 用逻辑回归分类
上一节的 sigmoid 函数给了我们一种方法:取一个实例 $\vct{x}$,计算概率 $P(y=1|\vct{x})$。那么如何决定测试实例应该属于哪个类别?对给定的 $\vct{x}$,如果 $P(y=1|\vct{x})>0.5$,我们回答“是”,否则回答“否”。0.5 称为决策边界:
4.3.1 情感分类
假设我们要对电影评论文本做二元情感分类,需要判断评论文档 doc 的情感类别是 $+$ 还是 $-$。我们用下表的 6 个特征 $x_1,…,x_6$ 表示每个输入观测;图4.2展示了一个小型测试文档中的这些特征。
| 变量 | 定义 | 图4.2中的值 |
|---|---|---|
| $x_1$ | $\operatorname{count}(\text{positive lexicon words}\in doc)$ | 3 |
| $x_2$ | $\operatorname{count}(\text{negative lexicon words}\in doc)$ | 2 |
| $x_3$ | $1$ if “no” $\in doc$, otherwise $0$ | 1 |
| $x_4$ | $\operatorname{count}(\text{1st and 2nd pronouns}\in doc)$ | 3 |
| $x_5$ | $1$ if “!” $\in doc$, otherwise $0$ | 0 |
| $x_6$ | $\ln(\text{word+punctuation count of doc})$ | $\ln(66)=4.19$ |

暂且假设我们已经为这些特征学到了实值权重,六个特征对应的权重为 $[2.5,-5.0,-1.2,0.5,2.0,0.7]$,偏置 $b=0.1$。权重 $w_1$ 表示正向词表词数量(great、nice、enjoyable 等)对正向情感决策的重要性,而 $w_2$ 表示负向词的重要性。注意 $w_1=2.5$ 为正,而 $w_2=-5.0$,说明负向词与正向情感决策负相关,且其重要性大约是正向词的两倍。
给定这 6 个特征和输入评论 $\vct{x}$,可由式(4.5)计算 $P(+|\vct{x})$ 和 $P(-|\vct{x})$:
4.3.2 其他分类任务和特征
逻辑回归可用于各种 NLP 任务,输入的任何属性都可以作为特征。考虑句点消歧任务:判断一个句点是句子结束符(EOS, end-of-sentence),还是某个词的一部分。下面的 $x_1$ 可能表示当前词是小写,且具有正权重;$x_2$ 可能表示当前词在缩写词典中,且具有负权重;$x_3$ 则表达属性组合。例如跟在大写词后面的句点很可能是句末,但如果该词是 St. 且前一个词首字母大写,那么句点很可能是街道名中 street 的缩写。
在经典模型中,特征通常由人手工设计:研究训练集,结合语言学直觉和文献,并通过早期系统在训练集上的错误分析来补充。也可以考虑特征交互,即由更原始特征组合成的复杂特征。句点消歧中的 St. 例子就是这样的交互。
特征还可以通过特征模板(feature templates)自动创建。模板是特征的抽象规格。例如,句点消歧的二元词模板可以为训练集中每个出现在句点前的词对创建一个特征。由于只有某个 n-gram 在训练集中出现在相应位置时才创建特征,特征空间是稀疏的。特征通常由字符串描述哈希得到;例如 “bigram(American breakfast)” 会被哈希为唯一整数 $i$,成为特征编号 $f_i$。
手工设计特征需要大量人力,因此现代 NLP 系统通常避免手工特征,转而关注表示学习:从输入中以无监督方式自动学习特征。第5章和第6章会介绍表示学习方法。
缩放输入特征。
当不同输入特征的取值范围差异很大时,通常会重新缩放特征,使其范围可比。标准化会把输入值中心化为零均值、单位标准差(这个变换也叫 z-score)。若 $\mu_i$ 是输入数据集中 $m$ 个观测在特征 $x_i$ 上的均值,$\sigma_i$ 是该特征的标准差,则可以用下面的新特征 $x_i'$ 替换 $x_i$:
也可以把输入特征归一化到 0 和 1 之间:
输入数据具有可比范围有助于跨特征比较数值。数据缩放在大型神经网络中特别重要,因为它能加速梯度下降。自然语言数据中另一个常见缩放方式是取对数,例如输入为词计数、二元词计数或其他服从 Zipf 分布的计数时。
4.3.3 一次处理多个样例
前面给出了单个样例的逻辑回归方程。实践中当然要处理包含多个样例的整个测试集。假设测试集有 $m$ 个测试样例,每个都要分类。按照第4.1节的记号,带括号的上标表示数据集中的样例索引;测试样例 $\vct{x}^{(i)}$ 的特征向量也记为 $\vct{x}^{(i)}$,$1\le i\le m$。
一种计算 $\hat{y}^{(i)}=P(y^{(i)}=1)$ 的方式是用循环逐个计算:
对前三个测试样例,就是分别计算
但可以稍微改写原方程,使它高效得多:用一次矩阵运算为所有样例分配类别。把每个输入 $\vct{x}$ 的特征向量打包到一个输入矩阵 $\vct{X}$ 中。矩阵第 $i$ 行是输入样例 $\vct{x}^{(i)}$ 的特征向量。若每个样例有 $f$ 个特征和权重,则 $\vct{X}$ 的形状为 $[m\times f]$:
令 $\vct{b}=[b,b,…,b]$ 为长度 $m$ 的向量,$\hat{\vct{y}}=[\hat{y}^{(1)},\hat{y}^{(2)},…,\hat{y}^{(m)}]$ 为输出向量,并把权重向量 $\vct{w}$ 表示为列向量,则所有输出可由一次矩阵乘法和一次加法得到:
可以验证,式(4.13)与式(4.11)中的循环等价。例如输出向量第一个元素为
式(4.13)带形状写作
现代编译器和硬件能高效计算这种矩阵运算,在大型数据集训练或测试时速度优势很重要。通常我们把输入表示为行,因此采用 $\vct{X}\vct{w}$;如果把每个输入样例表示为列,也可以写作 $\vct{w}\vct{X}+\vct{b}$,但那会改变矩阵形状。
4.4 逻辑回归中的学习
模型参数,也就是权重 $\vct{w}$ 和偏置 $b$,是如何学到的?二元逻辑回归是一种监督分类:对每个观测 $\vct{x}$,我们知道正确标签 $y$(0 或 1)。系统通过式(4.5)产生 $\hat{y}$,即系统认为 $y=1$ 的概率,可看作对真实 $y$ 的估计。我们希望学到的参数使每个训练观测的概率值 $\hat{y}$ 尽可能接近真实 $y$。如果 $y=1$,希望 $\hat{y}=P(y=1)$ 尽可能高;如果 $y=0$,希望 $\hat{y}$ 尽可能低。
这需要两个组成部分。第一,需要度量 $\hat{y}$(系统估计观测属于正类的概率)与真实金标准标签 $y$ 有多接近。通常不说相似度,而说相反的量:系统输出和金标准输出之间的距离,称为损失函数(loss function)或代价函数(cost function)。下一节介绍逻辑回归和神经网络常用的交叉熵损失。
第二,需要一个优化算法,迭代更新权重以最小化损失函数。标准算法是梯度下降;下一节介绍随机梯度下降。接下来先在二元逻辑回归中介绍这些算法,再在第4.8节转向多项逻辑回归。
4.5 交叉熵损失函数
我们需要一个损失函数,表达对观测 $\vct{x}$ 而言,分类器输出 $\hat{y}=\sigma(\vct{w}\cdot\vct{x}+b)$ 与正确输出 $y$(0 或 1)有多接近。$\hat{y}$ 表示分类器分配给“观测属于正类1”的概率。$\hat{y}$ 和 $y$ 都可看作概率,但 $y$ 总是 0 或 1,而 $\hat{y}$ 可以取中间值。我们把损失写成
做法是使用一个损失函数,使训练样例的正确类别标签具有更高概率。这叫条件最大似然估计:选择参数 $\vct{w},b$,最大化给定观测 $\vct{x}$ 时训练数据真实标签 $y$ 的对数概率。得到的损失函数是负对数似然损失,通常称为交叉熵损失。
先推导单个观测 $\vct{x}$ 的损失函数。我们想学习权重来最大化正确标签概率 $p(y|\vct{x})$。因为只有两个离散结果(1 或 0),这是 Bernoulli 分布,可写为
如果 $y=1$,它化简为 $\hat{y}$;如果 $y=0$,它化简为 $1-\hat{y}$。两边取对数:
式(4.18)是应当最大化的对数似然。为了把它变成需要最小化的损失函数,只需取负号:
代入 $\hat{y}=\sigma(\vct{w}\cdot\vct{x}+b)$ 得
看看这个损失函数在图4.2的例子中是否符合直觉。若正确金标准标签为正向,即 $y=1$,模型给正向的概率是 0.70、负向 0.30,因此表现不错。把 $\sigma(\vct{w}\cdot\vct{x}+b)=.70$ 和 $y=1$ 代入式(4.20),右侧第二项消失:
相反,若图4.2的例子实际上是负向,即 $y=0$,模型就混淆了,我们希望损失更大。代入 $1-\sigma(\vct{w}\cdot\vct{x}+b)=.30$:
果然,预测正确标签时的损失(.36)小于预测错误标签时的损失(1.2)。
为什么最小化负对数概率能达到我们的目标?完美分类器会给正确结果分配概率 1,给错误结果分配概率 0。如果 $y=1$,$\hat{y}$ 越高(越接近 1)分类器越好;越低(越接近 0)越差。如果 $y=0$,则 $1-\hat{y}$ 越高越好。负对数是方便的损失度量:从 0($-\log 1$,无损失)到无穷大($-\log 0$,无限损失)。这个损失还保证了正确答案概率最大化时,错误答案概率被最小化;二者之和为 1,正确答案概率增加必然来自错误答案概率减少。它叫交叉熵损失,是因为式(4.18)也是真实分布 $y$ 与估计分布 $\hat{y}$ 之间的交叉熵形式。
4.6 梯度下降
梯度下降的目标是找到最优权重:最小化模型的损失函数。机器学习中通常把待学习参数记作 $\theta$;对于逻辑回归,$\theta=\{\vct{w},b\}$。用 $f(\vct{x}^{(i)};\theta)$ 表示 $\hat{y}^{(i)}$,以强调它依赖于 $\theta$。目标是找到一组权重,使所有样例上的交叉熵损失平均值最小:
怎样找到这个损失函数的最小值?梯度下降会找出函数在参数空间 $\theta$ 中上升最快的方向,并朝相反方向移动。直觉上,这就像在峡谷中想最快下到谷底河流处:环顾四周,找出地面下降最陡的方向,然后沿着那个方向向下走。
对逻辑回归而言,损失函数是凸函数(convex)。凸函数至多只有一个最小值,不存在会被困住的局部最小值,所以从任意点开始的梯度下降都能找到最小值。相反,多层神经网络的损失非凸,训练神经网络时梯度下降可能陷入局部最小值。
虽然算法和“梯度”概念是为方向向量设计的,我们先看只有一个标量参数 $w$ 的情形。给定 $w$ 的一个随机初始值 $w^1$,若损失函数 $L$ 形状如图4.3,算法需要告诉我们下一次迭代应该向左(使 $w^2
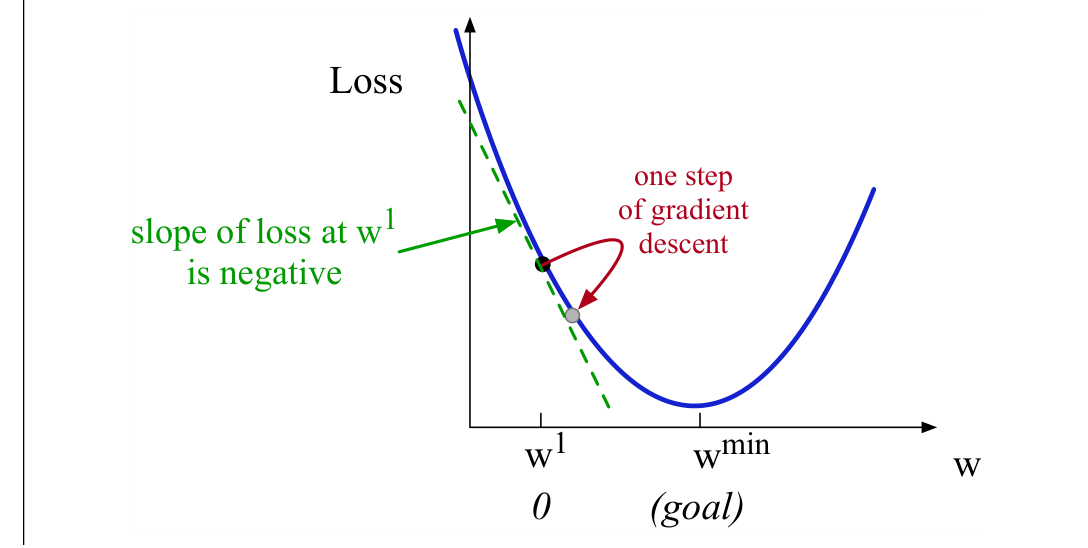
梯度下降通过计算当前点的损失函数梯度,并朝相反方向移动来回答这个问题。多变量函数的梯度是指向函数增长最快方向的向量。梯度是斜率的多变量推广;对图4.3中一元函数而言,可把梯度直观地理解为斜率。图中虚线表示假设损失函数在 $w=w^1$ 处的斜率。斜率为负,因此为了找到最小值,梯度下降让我们沿相反方向移动,即向 $w$ 的正方向移动。
梯度下降的移动幅度是斜率 $\frac{d}{dw}L(f(\vct{x};w),y)$ 乘以学习率 $\eta$。较高的学习率表示每一步应让 $w$ 移动更多。参数更新为
现在把直觉从一个标量变量 $w$ 扩展到多个变量。我们不只想知道向左还是向右,而是想知道在由 $N$ 个参数组成的 $N$ 维空间中该往哪里移动。梯度正是这样的向量:它表达沿每个维度的最陡上升方向分量。若只有两个权重维度(例如一个权重 $w$ 和一个偏置 $b$),梯度就是有两个正交分量的向量,每个分量说明在 $w$ 维和 $b$ 维上地面有多陡。图4.4展示了在红点处取得的二维梯度向量。
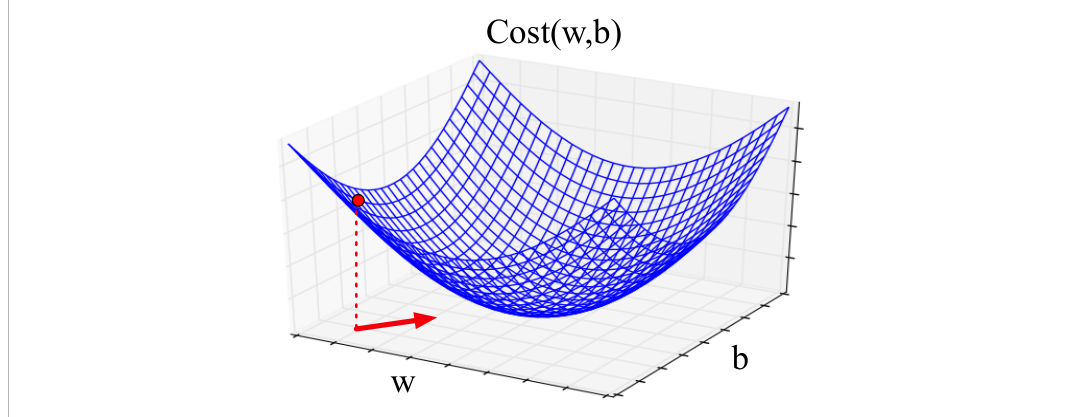
实际逻辑回归中的参数向量 $\vct{w}$ 通常远长于 1 或 2,因为输入特征向量 $\vct{x}$ 可以很长,且每个 $x_i$ 都需要一个权重 $w_i$。对 $\vct{w}$ 中每个维度/变量 $w_i$(以及偏置 $b$),梯度都有一个分量,说明损失函数相对于该变量的斜率。在每个维度 $w_i$ 上,这个斜率写作损失函数的偏导数 $\frac{\partial}{\partial w_i}$。
形式上,多变量函数 $f$ 的梯度是一个向量,每个分量表示 $f$ 对某个变量的偏导数。用倒三角符号 $\nabla$ 表示梯度:
因此基于梯度更新 $\theta$ 的最终方程为
4.6.1 逻辑回归的梯度
要更新 $\theta$,需要定义梯度 $\nabla L(f(\vct{x};\theta),y)$。逻辑回归的交叉熵损失为
这个函数对单个观测向量 $\vct{x}$ 的导数为
等价地也可写为
这个梯度项很直观:它是真实 $y$ 与估计 $\hat{y}=\sigma(\vct{w}\cdot\vct{x}+b)$ 之间的差,乘以对应输入值 $x_j$。
对偏置 $b$ 的偏导数为
4.6.2 随机梯度下降算法
随机梯度下降(stochastic gradient descent, SGD)是一种在线算法:对每个训练样例计算损失梯度,并把 $\theta$ 向正确方向(梯度的相反方向)轻推。在线算法逐个处理输入样例,而不是等到看完整个输入之后再处理。SGD 称为 stochastic,是因为它每次选择一个随机样例;第4.6.4节会讨论一次批处理多个样例的梯度下降版本。

学习率 $\eta$ 是必须调节的超参数。如果太高,学习器每一步太大,可能越过损失函数最小值;如果太低,每一步太小,达到最小值会太慢。常见做法是从较高学习率开始,然后逐渐降低,使其成为训练迭代 $k$ 的函数;$\eta_k$ 可表示第 $k$ 次迭代时的学习率。超参数不同于模型的普通参数(如 $\vct{w}$ 和 $b$);普通参数由算法从训练集中学到,超参数由算法设计者选择,并影响算法如何运行。
4.6.3 一个例子
来看梯度下降算法的一步。使用图4.2的简化版本:单个观测 $\vct{x}$ 的正确值 $y=1$(正向评论),特征向量 $\vct{x}=[x_1,x_2]$ 包含两个特征:
假设 $\theta^0$ 中初始权重和偏置全为 0,初始学习率 $\eta=0.1$:
单次更新需要计算梯度并乘以学习率:
这个小例子有三个参数,所以梯度向量有三个维度,分别对应 $w_1,w_2,b$:
得到梯度后,沿梯度的相反方向移动:
因此经过一步梯度下降后,权重变为 $w_1=.15$、$w_2=.1$、$b=.05$。这个观测是正例;如果之后看到更多含大量负向词的负例,$w_2$ 会逐渐变为负值。
4.6.4 小批量训练
SGD 每次选择一个随机样例,移动权重以改善该样例上的表现。这可能导致移动非常抖动,因此常常在一批训练实例上计算梯度,而不是只在单个实例上计算。
在批训练(batch training)中,我们在整个数据集上计算梯度。由于看到许多样例,批训练能极好地估计权重应向哪个方向移动,但代价是每次都要处理训练集中每个样例。
折中方法是小批量训练(mini-batch training):在一组少于整个数据集的 $m$ 个样例上训练(例如 512 或 1024 个)。如果 $m$ 等于数据集大小,就是批量梯度下降;如果 $m=1$,就是随机梯度下降。小批量训练还有计算效率优势:可轻松向量化,并根据计算资源选择小批量大小,从而并行处理小批量中的所有样例并累积损失。
把单个样例的交叉熵损失扩展到大小为 $m$ 的小批量。假设训练样例独立:
小批量 $m$ 个样例的代价函数是每个样例损失的平均:
小批量梯度是各个梯度的平均:
用矩阵形式可更高效地计算。设 $\vct{X}$ 是 $[m\times f]$ 的输入矩阵,$\vct{y}$ 是 $[m\times 1]$ 的正确输出向量:
4.7 多项逻辑回归
有时我们需要两个以上的类别。例如三分类情感分类(正向、负向或中性),词性标注(从 10、30 甚至 50 个词性中选择),命名实体类型识别(人名、地点、组织等),或在大型语言模型中从词表 $|V|$ 个可能词中预测下一个词,也就是 $|V|$ 路分类。
这时使用多项逻辑回归(multinomial logistic regression),也叫 softmax 回归;在较早的 NLP 文献中有时称为最大熵分类器(maxent classifier)。在多项逻辑回归中,要从 $K$ 个类别中为每个观测标注一个类别 $k$,并假设只有一个类别是正确的(硬分类)。
对每个输入 $\vct{x}$,输出 $\vct{y}$ 是长度 $K$ 的向量。如果正确类别是 $c$,则 $y_c=1$,其他元素 $y_j=0$($j\ne c$)。这种只有一个值为 1、其他为 0 的向量称为 one-hot 向量。分类器的任务是产生估计向量 $\hat{\vct{y}}$;对每个类别 $k$,$\hat{y}_k$ 是分类器对 $P(y_k=1|\vct{x})$ 的估计。
4.7.1 Softmax
多项逻辑分类器使用 sigmoid 的推广形式 softmax 函数来计算 $p(y_k=1|\vct{x})$。softmax 函数把一个含 $K$ 个任意值的向量 $\vct{z}=[z_1,z_2,…,z_K]$ 映射为概率分布:每个值在 $[0,1]$ 中,所有值之和为 1。和 sigmoid 一样,它也是指数函数。
对维度为 $K$ 的向量 $\vct{z}$,softmax 定义为
因此
分母用于把所有值归一化为概率。例如给定
四舍五入后的 $\operatorname{softmax}(\vct{z})$ 为
softmax 也会把值压向 0 或 1。如果某个输入比其他输入大得多,它会倾向于把对应概率推向 1,并压低较小输入的概率。和 sigmoid 一样,softmax 的输入分数向量 $\vct{z}$ 称为 logits。
4.7.2 在逻辑回归中应用 softmax
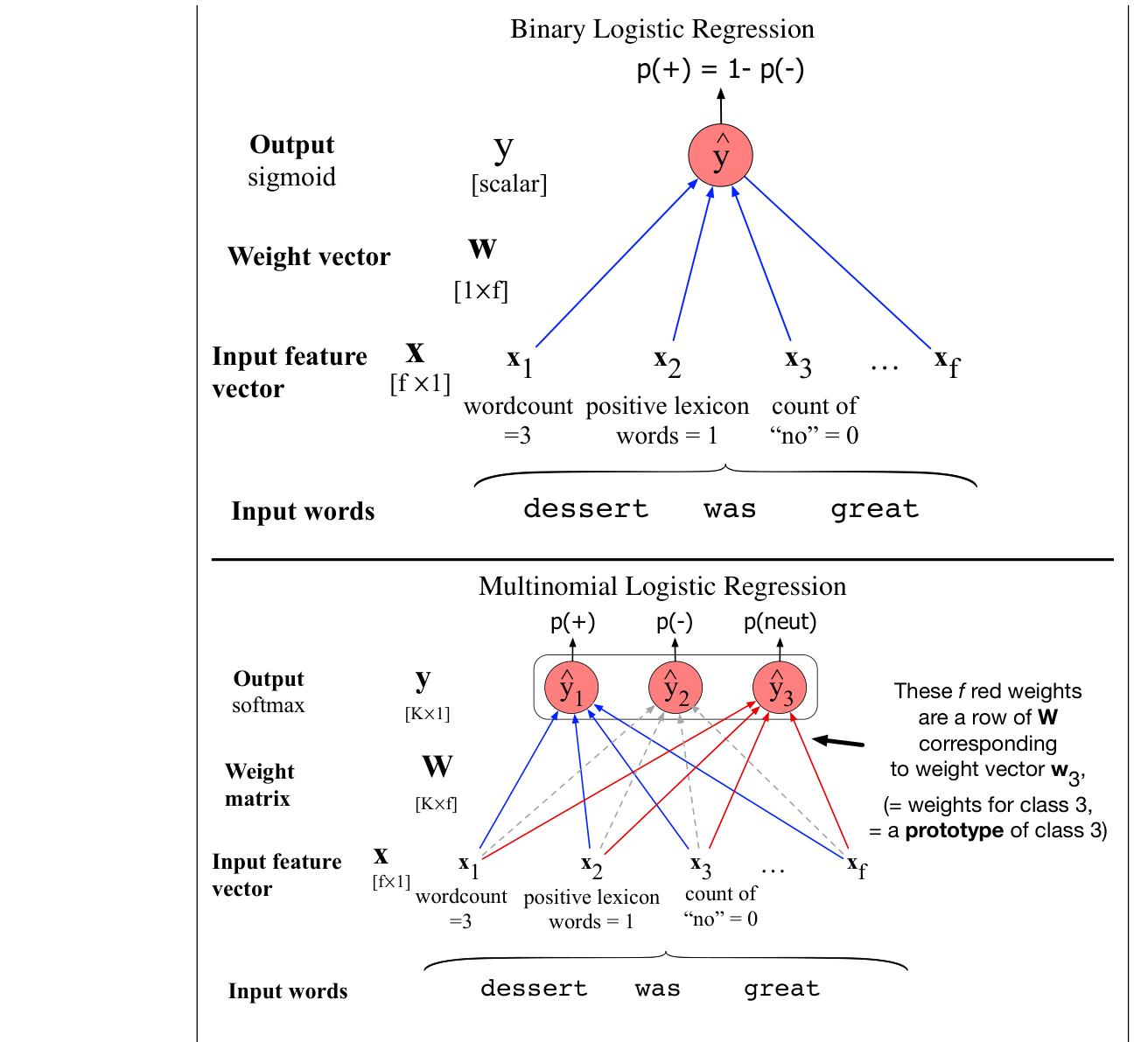
在逻辑回归中应用 softmax 时,输入仍然是权重向量 $\vct{w}$ 和输入向量 $\vct{x}$ 的点积(再加偏置)。但现在 $K$ 个类别各自需要一个权重向量 $\vct{w}_k$ 和偏置 $b_k$。每个输出类别的概率 $\hat{y}_k$ 可计算为
式(4.35)看起来像是逐个计算输出。但为了更高效地使用现代向量处理硬件,通常把 $K$ 个权重向量组织为权重矩阵 $\vct{W}$,偏置组织为向量 $\vct{b}$。$\vct{W}$ 的第 $k$ 行对应权重向量 $\vct{w}_k$,形状为 $[K\times f]$。偏置向量 $\vct{b}$ 对 $K$ 个输出类别各有一个值。于是可以用一个优雅方程计算覆盖所有 $K$ 个类别的输出概率向量:
权重矩阵 $\vct{W}$ 的一个有用解释是:每一行 $\vct{w}_k$ 都是类别 $k$ 的原型(prototype)。学习到的权重向量 $\vct{w}_k$ 像一个模板一样表示该类别。两个向量越相似,点积越高,因此点积充当相似度函数。逻辑回归由此学习每个类别的原型表示,使输入向量被分配给 $K$ 个类别中最相似的类别。
4.7.3 多项逻辑回归中的特征
多项逻辑回归中的特征与二元逻辑回归类似,区别是每个类别都有自己的权重向量和偏置。回忆二元分类中的感叹号特征
在二分类中,该特征的正权重会把分类器推向 $y=1$,负权重推向 $y=0$。而在多项逻辑回归中,一个特征可以分别支持或反对每一个类别。
例如三分类情感分类需要把每个文档分为 $+$、$-$ 或 $0$(中性)。与感叹号相关的特征可能对中性文档有负权重,对正向或负向文档有正权重:
由于这些特征权重同时依赖输入文本和输出类别,有时会把依赖显式写成 $f(\vct{x},y)$:一个同时以输入和类别为参数的函数。上面的 $f_5(\vct{x})$ 可以表示为三个特征 $f_5(\vct{x},+)$、$f_5(\vct{x},-)$、$f_5(\vct{x},0)$,每个各有一个权重。
4.8 多项逻辑回归中的学习
多项逻辑回归的损失函数把二元逻辑回归的损失从 2 个类别推广到 $K$ 个类别。二元逻辑回归的交叉熵损失是
多项逻辑回归把这两个项推广为 $K$ 项。对多项回归,$\vct{y}$ 和 $\hat{\vct{y}}$ 都是向量。真实标签 $\vct{y}$ 有 $K$ 个元素,正确类别 $c$ 对应 $y_c=1$,其他为 0。分类器产生的估计向量 $\hat{\vct{y}}$ 也有 $K$ 个元素,每个 $\hat{y}_k$ 表示估计概率 $p(y_k=1|\vct{x})$。
单个样例 $\vct{x}$ 的损失是 $K$ 个输出类别对数的加权和,权重是指示函数 $y_k$:
从式(4.38)到式(4.39)的原因是:只有一个类别 $c$ 是正确的,向量 $\vct{y}$ 只在该位置为 1,其余全为 0。因此求和中只有真实类别 $c$ 对应的项非零,交叉熵损失就是正确类别输出概率的负对数,也称负对数似然损失。
梯度下降需要的是梯度。单个样例的梯度与二元逻辑回归中的 $(\hat{y}-y)x$ 很相似。对每个类别 $k$,输入 $\vct{x}$ 第 $i$ 个元素的权重为 $w_{k,i}$;损失对 $w_{k,i}$ 的偏导为
4.9 评价:精确率、召回率、F度量
为了介绍文本分类的评价方法,先考虑简单的二元检测任务。垃圾邮件检测的目标是把每个文本标为 spam(正类)或 not-spam(负类)。对每个邮件文档,需要知道系统是否把它称为 spam,也需要知道它实际上是不是 spam,即每个文档的人类定义标签。我们把这些人工标签称为金标准标签(gold labels)。
类似地,假设你是 Delicious Pie Company 的 CEO,想知道社交媒体上人们如何谈论你的馅饼,于是构建一个系统检测有关 Delicious Pie 的推文。正类是关于 Delicious Pie 的推文,负类是所有其他推文。
评价这类检测系统时,首先构建混淆矩阵(confusion matrix),如图4.7。混淆矩阵用系统输出和金标准标签两个维度可视化算法表现。以垃圾邮件检测为例,真正例(true positive)是确实为 spam 且系统也正确标为 spam 的文档;假负例(false negative)是确实为 spam 但系统错误标为 non-spam 的文档。
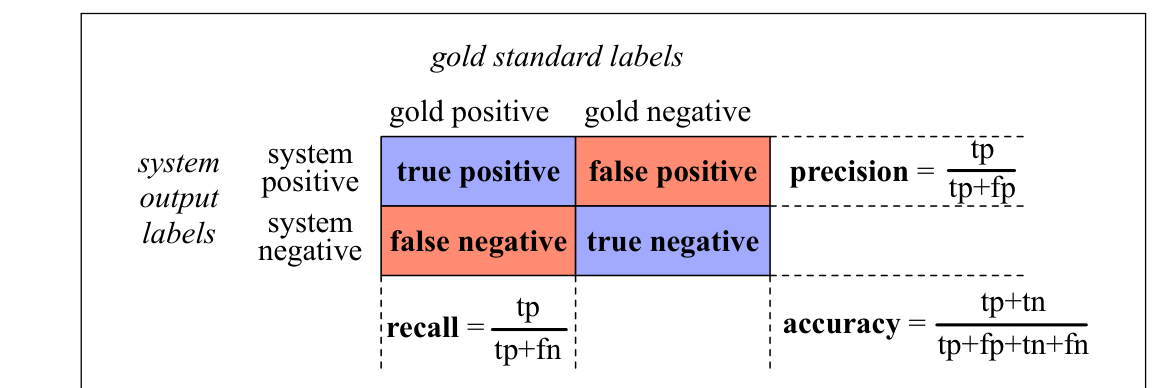
表格右下角是准确率(accuracy)公式,即系统正确标注的观测比例。虽然准确率看似自然,但文本分类任务通常不使用它,因为当类别不平衡时准确率表现很差。垃圾邮件在邮件中占多数;大多数推文也与馅饼无关。
例如看一百万条推文,只有 100 条讨论我们的馅饼,其他 999,900 条完全无关。一个愚蠢分类器把每条推文都标为“不是关于馅饼”,它会有 999,900 个真负例和 100 个假负例,准确率是 999,900/1,000,000,即 99.99%。这个准确率惊人,但分类器完全没用,因为它找不到任何我们真正关心的顾客评论。当目标是发现稀有事件或类别频率不平衡时,准确率不是好指标。
因此,通常使用图4.7中的精确率(precision)和召回率(recall)。精确率衡量系统检测出的项目中,实际上为正的比例:
召回率衡量输入中实际存在的正类项目中,被系统正确识别出来的比例:
精确率和召回率能解决“所有都不是馅饼”分类器的问题。这个分类器尽管准确率高达 99.99%,召回率却为 0,因为没有真正例、却有 100 个假负例。和准确率不同,精确率和召回率强调真正例:找到我们应该寻找的东西。
有许多方法可以把精确率和召回率合为一个指标。最简单的是 F 度量(F-measure):
$\beta$ 参数根据应用需要对召回率和精确率赋予不同权重。$\beta>1$ 偏向召回率,$\beta<1$ 偏向精确率。$\beta=1$ 时二者权重相同,这是最常用指标,称为 $F_{\beta=1}$ 或 $F_1$:
F 度量来自精确率和召回率的加权调和平均。$n$ 个数的调和平均为
因此 F 度量可写为
使用调和平均,是因为两个值的调和平均比算术平均更接近较小者;它对较小的指标惩罚更重,在这种情况下更保守。
4.9.1 多于两个类别时的评价
上面对精确率和召回率的定义来自只有两个类别的文本分类。但很多 NLP 分类任务有超过两个类别。情感分析常有三类(正向、负向、中性),文本分类、情绪检测等任务类别更多。
对于多类分类,需要稍微修改精确率和召回率定义。图4.8展示了一个三分类邮件分类任务(urgent、normal、spam)的混淆矩阵。
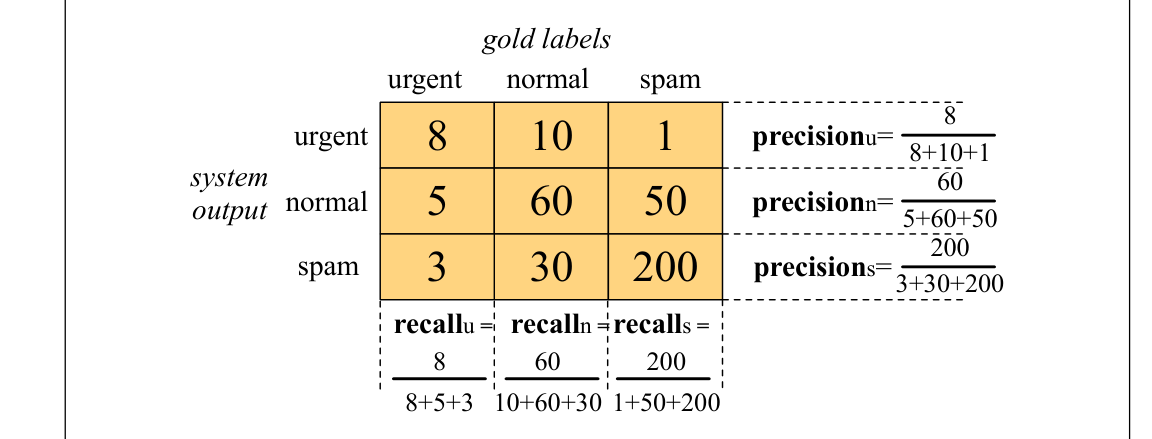
矩阵显示,例如系统把一个 spam 文档错误标为 urgent。图中还展示了如何为每个类别分别计算精确率和召回率。为了得到一个表示系统整体表现的单一指标,可以用两种方式组合这些值。宏平均(macroaveraging)先计算每个类别的表现,再跨类别平均。微平均(microaveraging)把所有类别的决策汇总到一个混淆矩阵中,再从该表计算精确率和召回率。
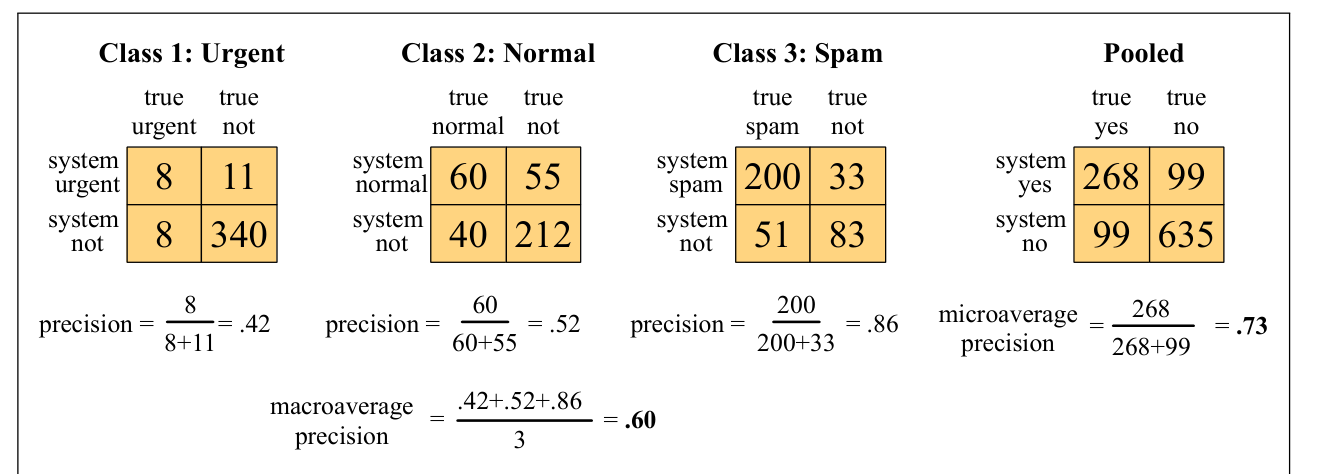
如图所示,微平均会被更频繁的类别主导,因为计数被汇总在一起。宏平均更能反映较小类别的统计情况,因此当所有类别上的表现同等重要时,宏平均更合适。
4.10 测试集与交叉验证
文本分类的训练和测试过程与语言模型类似:用训练集训练模型,用开发测试集(development test set,也叫 devset)调节某些参数并帮助选择模型。确定最佳模型之后,在此前未见过的测试集上运行并报告性能。
使用开发集可以避免过拟合测试集,但固定训练集、开发集、测试集也带来另一个问题:为了保留大量训练数据,测试集或开发集可能不够大,代表性不足。有没有办法既用全部数据训练,又用全部数据测试?交叉验证可以做到这一点。
在交叉验证中,选择一个数 $k$,把数据划分为 $k$ 个互不相交的子集,称为折(folds)。每次选择其中一个折作为测试集,用剩下 $k-1$ 个折训练分类器,然后在测试折上计算错误率。再换另一个折作为测试集,重复这一过程 $k$ 次,并对 $k$ 次测试错误率取平均。若 $k=10$,就训练 10 个不同模型(每个使用 90% 的数据),测试 10 次并平均结果,这叫 10 折交叉验证。
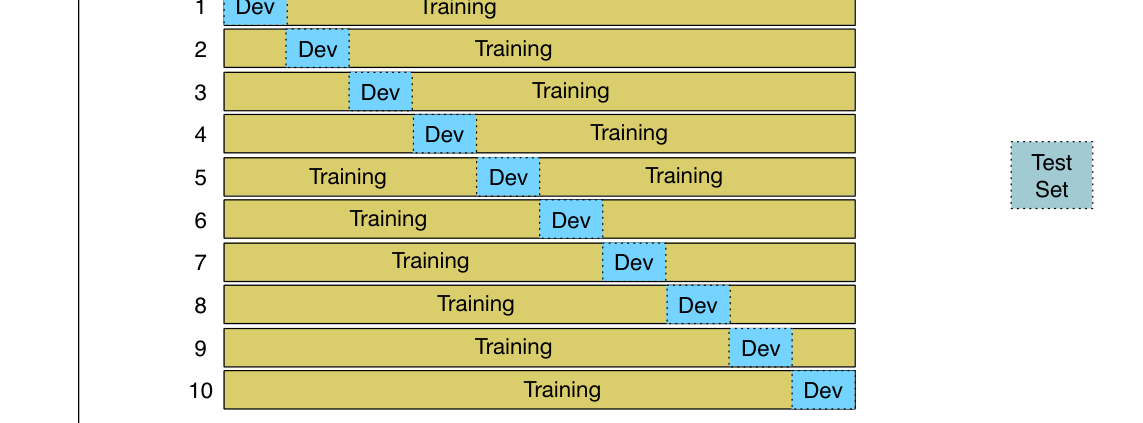
交叉验证的一个问题是:所有数据都被用作测试,因此整个语料都必须保持 blind;我们不能查看数据来启发特征或理解现象,否则就等于偷看测试集,会高估系统性能。然而,在设计 NLP 系统时,查看语料以理解情况又非常重要。因此常见做法是创建固定训练集和测试集,在训练集内部做 10 折交叉验证,而在测试集上按普通方式计算错误率,如图4.10。
4.11 统计显著性检验
构建系统时,经常需要比较两个系统的性能。怎样知道新系统是否优于旧系统,或优于文献中的某个系统?这是统计假设检验的问题。本节介绍 NLP 分类器的统计显著性检验,尤其借鉴 Dror et al. (2020) 和 Berg-Kirkpatrick et al. (2012)。
假设我们在某个指标 $M$(例如 $F_1$ 或准确率)上比较分类器 A 和 B。我们想知道新情感分类器 A 在测试集 $\vct{x}$ 上的 $F_1$ 是否高于旧分类器 B。令 $M(A,\vct{x})$ 为系统 A 在测试集 $\vct{x}$ 上的得分,$\delta(\vct{x})$ 为 A 与 B 在 $\vct{x}$ 上的性能差:
我们想知道 $\delta(\vct{x})>0$ 是否成立。$\delta(\vct{x})$ 称为效应量(effect size);更大的 $\delta$ 表示 A 似乎比 B 好很多,小的 $\delta$ 表示只好一点。
为什么不只看 $\delta(\vct{x})$ 是否为正?如果发现 A 的 $F_1$ 比 B 高 .04,能确定 A 更好吗?不能。A 可能只是碰巧在这个特定测试集 $\vct{x}$ 上更好。我们还想知道,如果换另一个测试集 $\vct{x}'$ 或其他条件,A 的优势是否仍可能成立。
在统计假设检验框架中,我们形式化两个假设:
$H_0$ 称为零假设,假设 $\delta(\vct{x})$ 实际为负或 0,也就是 A 并不优于 B。我们希望知道能否有信心排除这个假设,转而支持 $H_1$。
做法是创建一个随机变量 $X$,其取值覆盖所有测试集。然后问:如果零假设 $H_0$ 正确,那么在大量重复实验中,观察到我们看到的 $\delta(\vct{x})$ 或更大值的概率有多大?这个概率称为 p 值:
非常小的 p 值表示在零假设下观察到的差异极不可能,因此可以拒绝零假设。常用阈值包括 .05 或 .01。若阈值为 .01,且 p 值小于 .01,就拒绝零假设,并认为 A 确实优于 B。当观察到的 $\delta$ 的概率低于阈值、从而拒绝零假设时,我们称结果具有统计显著性。
怎样计算 p 值需要的概率?NLP 中通常不使用简单的参数检验(如 t 检验或 ANOVA),因为它们假设检验统计量服从某些分布(如正态性),而这些假设通常不成立。因此 NLP 通常使用基于采样的非参数检验:人为创建许多实验设置版本。NLP 中常用两类非参数检验:近似随机化(approximate randomization)和 bootstrap 检验。下面介绍配对 bootstrap,它在 NLP 中最常见。配对检验比较两组对齐的观测;当比较两个系统在同一测试集上的表现时,系统 A 在样例 $x_i$ 上的表现可以与系统 B 在同一 $x_i$ 上的表现配对。
4.11.1 配对 bootstrap 检验
bootstrap 检验可用于任何指标,从精确率、召回率、$F_1$ 到机器翻译中的 BLEU。bootstrapping 指从原始集合中反复有放回地抽取大量样本(bootstrap samples)。bootstrap 检验的直觉是:通过从观察到的测试集中重复采样,可以创建许多虚拟测试集。它只假设样本能代表总体。
考虑一个很小的文本分类例子:测试集 $\vct{x}$ 含 10 个文档。图4.11第一行显示两个分类器 A 和 B 在该测试集上的结果。每个文档标为四种可能之一:A 和 B 都对、都错、A 对 B 错、A 错 B 对。字母上划线表示该分类器答错。若为简单起见把指标设为准确率,A 的准确率为 .70,B 的准确率为 .50,因此 $\delta(\vct{x})=.20$。

现在创建大量 $b$ 个虚拟测试集 $\vct{x}^{(i)}$(例如 $10^5$ 个),每个大小为 $n=10$。每次创建虚拟测试集时,都从原始 $\vct{x}$ 中有放回地随机选择一个单元格。得到 $b$ 个测试集后,就有一个采样分布,可以统计 A 偶然占优的频率。
若假设 $H_0$ 成立(A 不比 B 好),理论上许多测试集上 $\delta(X)$ 的期望应为 0 或负。观察到很高的值会令人惊讶。按照 Berg-Kirkpatrick et al. (2012) 的版本,由于 bootstrap 样本来自原始测试集 $\vct{x}$,而 $\vct{x}$ 本身已经以 .20 偏向 A,所以计算 p 值时统计的是有多少 bootstrap 测试集中 $\delta(\vct{x}^{(i)})$ 超过 $\delta(\vct{x})$ 的期望值至少 $\delta(\vct{x})$:
其中 $\mathbb{1}(x)$ 表示若 $x$ 为真则为 1,否则为 0。若有 10,000 个测试集和 .01 阈值,且只有 47 个测试集满足 $\delta(\vct{x}^{(i)})\ge 2\delta(\vct{x})$,则 p 值为 .0047,小于 .01,说明观察到的差异足够令人惊讶,不太可能偶然发生,可以拒绝零假设并认为 A 优于 B。

4.12 避免分类中的危害
必须避免分类器可能造成的危害。一类危害是表征性危害(representational harms):系统贬低某个社会群体,例如延续关于该群体的负面刻板印象。Kiritchenko and Mohammad (2018) 考察了 200 个情感分析系统在成对句子上的表现;句子唯一差别是包含常见非裔美国人名字(如 Shaniqua)或常见欧裔美国人名字(如 Stephanie)。他们发现,大多数系统会给包含非裔美国人名字的句子分配更低情感和更负面情绪,从而反映并延续把非裔美国人与负面情绪关联的刻板印象。
在其他任务中,分类器可能带来表征性危害以及其他危害,例如沉默某些声音。毒性检测(toxicity detection)是一个重要文本分类任务,目标是检测仇恨言论、辱骂、骚扰或其他有毒语言。虽然这类分类器的目标是减少社会危害,但毒性分类器自身也可能造成危害。研究表明,一些广泛使用的毒性分类器会把无毒但提到某些身份的句子错误标为有毒,例如提到女性、盲人或同性恋者的句子,或使用非裔美国英语等语言变体特征的句子。这些假正例可能导致关于这些群体或由这些群体发出的言论被压制。
这些模型问题可能来自训练数据中的偏见或其他问题;机器学习系统通常会复制甚至放大训练数据中的偏见。问题也可能来自标签(例如人工标注者偏见)、使用的资源(如词表或预训练嵌入等模型组件),甚至模型架构(例如模型被训练来优化什么目标)。虽然缓解这些偏见(例如仔细考虑训练数据来源)是重要研究方向,但目前还没有通用解决方案。因此,在发布任何 NLP 模型时,研究这些因素并清晰说明非常重要。一种方式是为每个模型版本发布模型卡(model card),记录如下信息:
- 训练算法和参数;
- 训练数据来源、动机和预处理;
- 评价数据来源、动机和预处理;
- 预期用途和用户;
- 不同人口统计或环境情形下的模型性能。
4.13 解释模型
我们常常不仅想知道一个观测的正确分类,还想知道分类器为什么做出这样的决策。也就是说,我们希望决策可解释。可解释性很难严格定义,但核心思想是:人应该知道算法为什么得出某个结论。逻辑回归的特征通常由人设计,因此理解分类器决策的一种方式,是理解每个特征在决策中扮演的角色。逻辑回归可以与统计检验结合(例如似然比检验或 Wald 检验);考察某个特征是否显著,或检查它的权重大小,都能帮助解释分类器为什么做出某个决策。这对构建透明模型极为重要。
此外,逻辑回归不仅是分类器,也是 NLP 和许多领域中广泛使用的分析工具,可用于检验解释变量(特征)对结果的影响。在文本分类中,我们可能想知道逻辑否定词(no、not、never)是否更可能与负向情感相关,或负面电影评论是否更可能讨论摄影。但这样做时必须控制潜在混杂因素:其他可能影响情感的因素,例如电影类型、年份、评论长度。类似地,研究由 NLP 抽取的语言特征与非语言结果(再入院率、政治结果、产品销售)之间的关系时,也需要控制病人年龄、投票县、产品品牌等混杂因素。在这些情况下,逻辑回归允许我们测试某个特征是否在其他特征影响之外还与某个结果相关。
4.14 进阶:正则化
Numquam ponenda est pluralitas sine necessitate
“如无必要,勿增实体。” William of Occam
学习权重时,如果让模型完美匹配训练数据,会出现问题。若某个特征碰巧只出现在一个类别中并完美预测结果,它会获得非常高的权重。特征权重会试图完美拟合训练集细节,甚至过于完美,把偶然与类别相关的噪声因素也建模进去。这个问题称为过拟合(overfitting)。好的模型应当能从训练数据泛化到未见测试集;过拟合模型泛化能力差。
为避免过拟合,在式(4.21)的损失函数中加入新的正则化项 $R(\theta)$。以下写成最大化对数概率而不是最小化损失,并去掉不影响 $\arg\max$ 的 $\frac{1}{m}$:
新的正则化项惩罚大权重。因此,如果某组权重完美匹配训练数据,但需要许多很大的权重,就会比另一组略微不那么完美、但权重较小的设置受到更大惩罚。正则化强度参数 $\alpha$ 越高,模型权重越低,对训练数据的依赖越小。通常不对偏置项正则化,因为偏置像阈值一样帮助处理非中心化数据和类别先验。
常见的正则化项有两种。$L_2$ 正则化是权重值的二次函数,因使用权重的 $L_2$ 范数平方而得名。若 $\theta$ 包含 $n$ 个权重,则
$L_2$ 正则化损失为
$L_1$ 正则化是权重值的线性函数,因 $L_1$ 范数 $||\vct{W}||_1$ 得名,即权重绝对值之和,也称曼哈顿距离:
$L_1$ 正则化损失为
在统计学中,$L_1$ 正则化称为 lasso 回归,$L_2$ 正则化称为 ridge 回归,二者都常用于语言处理。$L_2$ 因导数简单而更容易优化;$L_1$ 更复杂,因为 $|\theta|$ 在 0 处导数不连续。$L_2$ 倾向于许多小权重,$L_1$ 则倾向于稀疏解:有一些较大权重,但更多权重为 0。因此 $L_1$ 会产生稀疏得多的权重向量,也就是更少的特征。两种正则化通常都忽略偏置项,只考虑其他权重。
$L_1$ 和 $L_2$ 正则化还可从贝叶斯角度解释为对权重形状的先验约束。$L_1$ 正则化可视为权重上的 Laplace 先验。$L_2$ 正则化对应假设权重服从均值 $\mu=0$ 的高斯分布。在高斯分布中,值离均值越远,概率越低。因此,对权重使用高斯先验,就是说权重更倾向于取 0。权重 $\theta_j$ 的高斯形式为
若每个权重都乘以高斯先验,相当于最大化
在对数空间中,若 $\mu=0$ 且 $2\sigma^2=1$,就对应
与式(4.51)形式相同。
4.15 进阶:推导梯度方程
本节推导逻辑回归交叉熵损失函数 $L_{\mathrm{CE}}$ 的梯度。先回顾几个微积分事实。首先是 $\ln(x)$ 的导数:
其次是 sigmoid 的优雅导数:
最后是链式法则。若复合函数 $f(x)=u(v(x))$,则
我们想知道损失函数对单个权重 $w_j$ 的导数:
利用链式法则和对数导数:
整理项,并代入 sigmoid 的导数,再使用一次链式法则,可得
4.16 小结
本章介绍了用于分类的逻辑回归模型。
- 逻辑回归是一种监督式机器学习分类器:从输入抽取实值特征,分别乘以权重并求和,再通过 sigmoid 函数生成概率。随后用阈值做出决策。
- 逻辑回归既可以用于两个类别(例如正向和负向情感),也可以用于多个类别(多项逻辑回归,例如多路文本分类、词性标注等)。
- 多项逻辑回归使用 softmax 函数计算概率。
- 权重(向量 $\vct{w}$ 和偏置 $b$)通过带标签训练集学习;学习需要最小化某个损失函数,例如交叉熵损失。
- 最小化该损失函数是凸优化问题,可使用梯度下降等迭代算法找到最优权重。
- 正则化用于避免过拟合。
- 逻辑回归也是最有用的分析工具之一,因为它能透明地研究单个特征的重要性。
历史注记
逻辑回归最早在统计学中发展起来,20世纪60年代已用于二元数据分析,并在医学中尤其常见。20世纪70年代末开始,它被广泛用于语言学,成为研究语言变异的正式基础之一。
不过,逻辑回归直到20世纪90年代才在自然语言处理中变得常见,而且似乎同时从两个方向进入 NLP。第一个来源是相邻的信息检索和语音处理领域,这两个领域都使用过回归,也把许多统计技术带入 NLP。早期把逻辑回归用于文档路由的工作,也是最早使用 LSI 嵌入作为词表示的 NLP 应用之一。
与此同时,20世纪90年代早期,IBM Research 以最大熵建模或 maxent 的名称发展并应用了逻辑回归,似乎独立于统计学文献。在这个名称下,它被用于语言建模、词性标注、句法分析、共指消解和文本分类。
关于各种文本分类任务有许多资料来源。情感分析可参见 Pang and Lee (2008) 以及 Liu and Zhang (2012)。Stamatatos (2009) 综述了作者归属算法。语言识别可参见 Jauhiainen et al. (2019),Jaech et al. (2016) 是重要的早期神经系统。新闻索引任务常作为文本分类算法的测试用例,基于 Reuters-21578 新闻语料。
文本分类可参见 Manning et al. (2008) 和 Aggarwal and Zhai (2012);一般分类问题见机器学习教材,例如 Hastie et al. (2001)、Witten and Frank (2005)、Bishop (2006)、Murphy (2012)。
计算统计显著性的非参数方法首先在 MUC 竞赛中用于 NLP,在语音识别中甚至更早出现。本章对 bootstrap 的描述参考 Berg-Kirkpatrick et al. (2012)。近期工作还关注多个测试集和多个指标等问题。
特征选择是一种移除不太可能泛化特征的方法。特征通常按其对分类决策的信息量排序。常用指标信息增益(information gain)告诉我们某个词的出现为猜测类别提供了多少比特信息。其他特征选择指标包括 $\chi^2$、点互信息和 GINI 指数。
练习
原章第4章在提供的页面中仅显示练习标题,未包含具体题目正文。