荃者所以在鱼,得鱼而忘荃。
网是为了捕鱼;一旦得到了鱼,便可以忘记网。
言者所以在意,得意而忘言。
词语是为了意义;一旦得到了意义,便可以忘记词语。
——庄子,第 26 章
5 嵌入
洛杉矶著名的沥青主要出现在高速公路上。但在城市中央还有另一片沥青,那就是拉布雷亚沥青坑;这些沥青保存了更新世冰期末期的数百万块化石骨骼。其中一种化石是 Smilodon,即剑齿虎,它那长长的犬齿使人一眼就能认出。大约五百万年前,一种完全不同的剑齿虎 Thylacosmilus 生活在阿根廷以及南美其他地区。Thylacosmilus 是有袋类,而 Smilodon 是胎盘哺乳动物,但 Thylacosmilus 同样具有很长的上犬齿,而且像 Smilodon 一样,下颌上也有保护性的骨质突缘。这两种哺乳动物之间的相似性,是平行演化或趋同演化的许多例子之一:特定的语境或环境会使不同物种演化出非常相似的结构(Gould, 1980)。

语境在另一种不那么生物学意义上的有机体,也就是词的相似性中同样重要。出现在相似语境中的词,往往具有相似的意义。词的分布方式上的相似性与词义上的相似性之间的这种联系,称为分布假说(distributional hypothesis)。这一假说最早由 Joos(1950)、Harris(1954)和 Firth(1957)等语言学家在 20 世纪 50 年代提出。他们注意到,同义词(如 oculist 和 eye-doctor)往往出现在相同的环境中,例如靠近 eye 或 examined 等词;两个词之间意义差异的大小,大致对应于它们环境差异的大小(Harris, 1954, p. 157)。
本章介绍嵌入(embeddings):直接从文本中的词分布学习出来的词义向量表示。嵌入位于大型语言模型和其他现代应用的核心。这里介绍的静态嵌入,是更强大的动态或上下文化嵌入的基础;后者包括第 9 章和第 8 章将看到的 BERT 这类表示。
研究嵌入及其意义的语言学领域称为向量语义学(vector semantics)。嵌入也是本书第一个表示学习(representation learning)的例子:自动学习输入文本的有用表示。寻找这种自监督方式来学习语言表示,而不是通过特征工程手工创建表示,是现代 NLP 的重要原则(Bengio et al., 2013)。
5.1 词汇语义学
先从词义的一些基本原则开始。我们应该如何表示一个词的意义?在第 3 章的 n-gram 模型以及经典 NLP 应用中,词的唯一表示只是一个字母串,或者词汇表中的一个索引。这种表示方式与哲学中的一个传统并没有太大差别;你也许在入门逻辑课上见过这种做法:用小型大写字母拼出一个词来表示它的意义,例如把 “dog” 的意义表示为 DOG,把 “cat” 的意义表示为 CAT,或者使用撇号形式 DOG'。
用大写形式来表示词义显然不是令人满意的模型。你也许见过语义学家 Barbara Partee 最早讲过的一个笑话版本(Carlson, 1977):
问:生命的意义是什么?
答:LIFE'
我们当然可以做得更好。毕竟,我们希望词义模型能替我们完成各种事情:它应当告诉我们某些词有相似意义(cat 与 dog 相似),另一些词互为反义(cold 与 hot 相反),有些词带有正面内涵(happy),有些词带有负面内涵(sad)。它还应当表示这样一个事实:buy、sell 和 pay 的意义都从不同视角描述同一个购买事件。(如果我从你那里买了某物,你很可能把它卖给了我,而我也很可能付了钱给你。)更一般地,词义模型应当允许我们进行推理,以解决问答、对话等与意义有关的任务。
本节总结这些需求中的一部分,这些需求来自语言学中对词义的研究,也就是词汇语义学(lexical semantics)。我们会在附录 G 和第 21 章回到并扩展这份清单。
词目与词义
我们先看看一个词(这里选 mouse)在词典中可能如何定义。下面的定义简化自在线词典 WordNet:
mouse (N)
1. 许多小型啮齿动物中的任一种……
2. 一种手动操作、用于控制光标的设备……
这里的形式 mouse 是词目(lemma),也称为引用形式(citation form)。mice 这个词的词目同样是 mouse;词典通常不会为 mice 这样的屈折形式单独列定义。类似地,sing 是 sing、sang、sung 的词目。在许多语言中,动词的不定式形式被用作词目,例如西班牙语 dormir “睡觉” 是 duermes “你睡觉” 的词目。像 sung、carpets、sing 或 duermes 这样的具体形式称为词形(wordform)。
如上例所示,每个词目可以有多个意义;词目 mouse 可以指啮齿动物,也可以指光标控制设备。我们把 mouse 意义的这些不同方面分别称为词义(word sense)。词目可能是多义的(polysemous),这会使解释变得困难:搜索 “mouse info” 的人是在找宠物信息,还是在找电子设备信息?第 9 章和附录 G 会讨论多义性问题,并介绍词义消歧,即判断某个词在特定语境中使用的是哪一种词义的任务。
同义
词义的一个重要组成部分,是词义之间的关系。例如,如果一个词的某个词义与另一个词的某个词义相同或几乎相同,我们就说这两个词义对应的词是同义词(synonyms)。同义词包括如下词对:
couch/sofa vomit/throw up filbert/hazelnut car/automobile
如果在任意句子中用一个词替换另一个词都不改变句子的真值条件,也就是不改变该句为真的那些情形,那么这两个词可以更形式化地称为同义词。
有些词对,如 car/automobile 或 water/$H_2O$,互相替换时可以保持真值不变,但它们的意义仍然并不完全相同。事实上,也许没有两个词在意义上绝对相同。语义学的一条基本原则称为对立原则(principle of contrast)(Girard 1718; Breal 1897; Clark 1987):语言形式上的差异总是伴随着某种意义差异。例如,$H_2O$ 常用于科学语境,在徒步指南中则不合适;此时 water 更合适。这种文体差异也是词义的一部分。因此在实践中,synonym 一词通常用来描述近似或粗略的同义关系。
词相似性
虽然一个词真正的同义词并不多,但大多数词都有许多相似词。cat 不是 dog 的同义词,但猫和狗当然是相似的词。从同义转向相似时,我们将从词义之间的关系(如同义)转为讨论词之间的关系(如相似)。直接处理词可以避免我们必须先承诺某种特定的词义表示,这会让任务更简单。
词相似性(word similarity)的概念在更大的语义任务中非常有用。知道两个词有多相似,有助于计算两个短语或句子的意义有多相似,而这又是问答、复述和摘要等任务的重要组成部分。获得词相似性数值的一种方法,是请人类判断一个词与另一个词有多相似。许多数据集就是由这类实验产生的。例如 SimLex-999 数据集(Hill et al., 2015)给出了 0 到 10 之间的评分,如下例所示;这些词对从近义词(vanish, disappear)到几乎看不出有什么共同点的词对(hole, agreement)都有:
| vanish | disappear | 9.8 |
| belief | impression | 5.95 |
| muscle | bone | 3.65 |
| modest | flexible | 0.98 |
| hole | agreement | 0.3 |
词相关性
两个词的意义还可以以相似性之外的方式发生关联。一类这样的联系称为词相关性(word relatedness)(Budanitsky and Hirst, 2006),在心理学传统中也称为词联想(word association)。
考虑 coffee 和 cup 的意义。coffee 与 cup 并不相似;它们几乎没有共同特征(咖啡是一种植物或饮料,而杯子是一种具有特定形状的人工制品)。但 coffee 与 cup 显然相关,因为它们共同参与一个日常事件:用杯子喝咖啡。类似地,scalpel 与 surgeon 并不相似,但在事件层面相关,因为外科医生常使用手术刀。
词之间一种常见的相关性,是它们属于同一个语义场(semantic field)。语义场是一组覆盖某一语义域并彼此具有结构化关系的词。例如,词可以因为同属于医院语义场(surgeon, scalpel, nurse, anesthetic, hospital)、餐馆语义场(waiter, menu, plate, food, chef)或房屋语义场(door, roof, kitchen, family, bed)而相关。语义场也与主题模型有关,例如潜在狄利克雷分配(Latent Dirichlet Allocation, LDA);主题模型在大型文本集合上应用无监督学习,从文本中归纳出关联词集合。语义场和主题模型是发现文档主题结构的有用工具。
在附录 G 中,我们还会介绍词义之间的更多关系,如上位关系或 IS-A 关系、反义关系,以及部分-整体关系。
内涵
最后,词还具有情感意义或内涵(connotations)。connotation 一词在不同领域中含义不同,这里我们用它指词义中与作者或读者的情绪、情感倾向、观点或评价相关的方面。例如,一些词具有正面内涵(wonderful),另一些词具有负面内涵(dreary)。即使在其他方面意义相似的词,内涵也可能不同;比较一边的 fake, knockoff, forgery 与另一边的 copy, replica, reproduction,或者比较 innocent(正面内涵)和 naive(负面内涵)。一些词表达正面评价(great, love),另一些表达负面评价(terrible, hate)。正面或负面的评价性语言称为情感倾向(sentiment),这在附录 K 中已经见过;词的情感倾向在情感分析、立场检测,以及将 NLP 用于政治语言和消费者评论等重要任务中都会发挥作用。
关于情感意义的早期研究(Osgood et al., 1957)发现,词在情感意义的三个重要维度上会发生变化:
- 效价(valence):刺激物令人愉悦的程度。
- 唤醒度(arousal):刺激物引发情绪的强度。
- 支配度(dominance):刺激物施加控制的程度。
因此,happy 或 satisfied 这样的词效价高,而 unhappy 或 annoyed 效价低。excited 唤醒度高,而 calm 唤醒度低。controlling 支配度高,而 awed 或 influenced 支配度低。每个词因此可以用三个数字来表示,分别对应于它在三个维度上的取值:
| 效价 | 唤醒度 | 支配度 | |
|---|---|---|---|
| courageous | 8.0 | 5.5 | 7.4 |
| music | 7.7 | 5.6 | 6.5 |
| heartbreak | 2.5 | 5.7 | 3.6 |
| cub | 6.7 | 4.0 | 4.2 |
Osgood et al.(1957)注意到,当用这三个数字表示一个词的意义时,模型实际上是把每个词表示为三维空间中的一个点,也就是一个向量;三个维度分别对应这个词在三个量表上的评分。词义可以表示为空间中的一个点,例如 heartbreak 的一部分意义可以表示为点 $[2.5, 5.7, 3.6]$。这个革命性的思想,是我们接下来介绍的向量语义模型的最早表达。
5.2 向量语义学:直觉
向量语义学是 NLP 中表示词义的标准方式,它帮助我们建模上一节看到的词义的许多方面。这个模型的根源在 20 世纪 50 年代,当时两个重要思想汇合在一起:一是前面提到的 Osgood 在 1957 年提出的想法,即用三维空间中的一个点表示词的内涵;二是 Joos(1950)、Harris(1954)和 Firth(1957)等语言学家的主张,即用词在语言使用中的分布来定义词义,也就是用它的邻近词或语法环境来定义词义。他们的想法是:两个词如果出现在非常相似的分布中,也就是邻近词相似,那么它们的意义也相似。
例如,假设你不知道 ongchoi 这个词的意思(这是一个近来从粤语借入的词),但你在如下语境中看到了它:
(5.1) Ongchoi is delicious sauteed with garlic.
(5.2) Ongchoi is superb over rice.
(5.3) ...ongchoi leaves with salty sauces...
再假设你曾在其他语境中见过这些上下文词中的许多词:
(5.4) ...spinach sauteed with garlic over rice...
(5.5) ...chard stems and leaves are delicious...
(5.6) ...collard greens and other salty leafy greens
ongchoi 与 rice、garlic、delicious、salty 等词共同出现,而 spinach、chard 和 collard greens 也与这些词共同出现,这一事实也许会提示我们:ongchoi 是一种叶菜,类似这些其他叶菜。[注 1] 我们可以用计算方式实现同样的直觉:只需统计 ongchoi 的上下文中的词。
向量语义学的想法,是把词表示为多维语义空间中的一个点,而这个语义空间以不同方式从词的邻近词分布中导出。用于表示词的向量称为嵌入。“embedding” 这个词在历史上来自它在数学中的含义,即从一个空间或结构到另一个空间或结构的映射,虽然它的含义后来发生了转移;本章末尾会再谈到这一点。
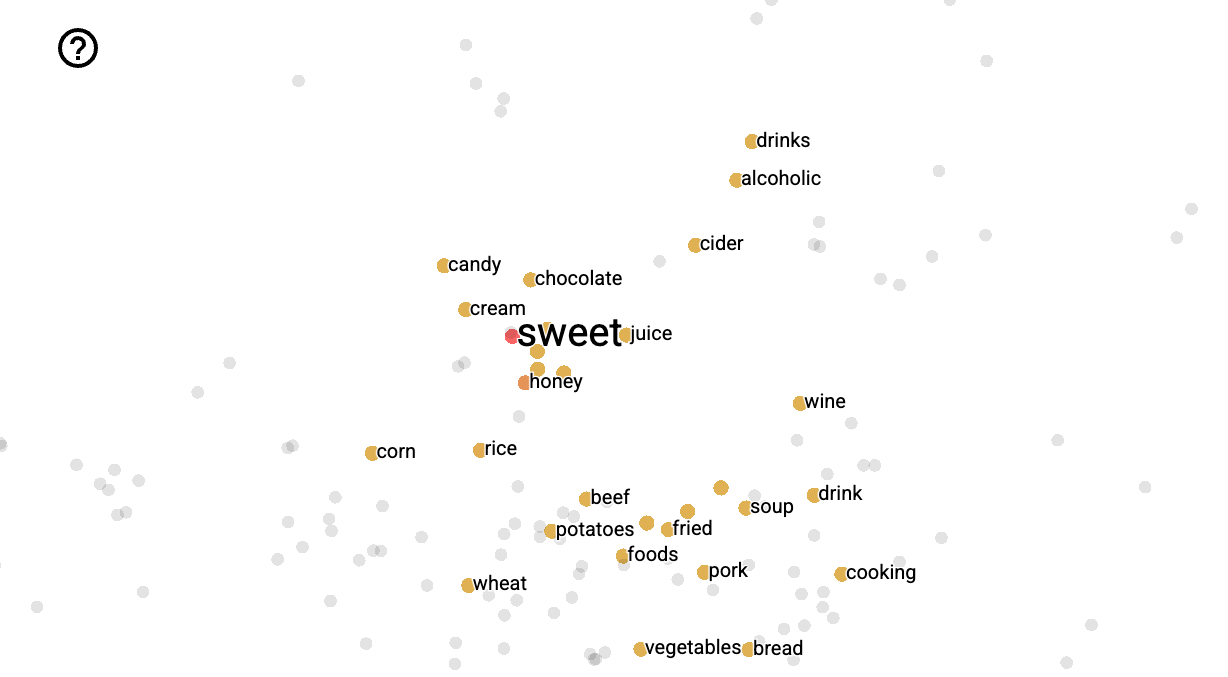
图 5.1 展示了由 word2vec 算法学习到的嵌入的可视化,把选出的词(“sweet” 的邻近词)从 200 维空间投影到二维空间。注意,sweet 的最近邻是 honey、candy、juice、chocolate 等语义相关的词。相似词在高维空间中相邻这一想法,为语言模型和其他 NLP 应用提供了巨大能力。例如,第 4 章的情感分类器依赖训练集和测试集中出现相同的词。但如果把词表示为嵌入,只要分类器见过一些意义相近的词,就可以进行情感判定。并且正如我们将看到的,图 5.1 所示的向量语义模型可以从文本中自动、无监督地学习出来。
本章将先从一个简单的教学性嵌入模型开始,在这个模型中,一个词的意义由一个向量定义,向量中记录附近词的计数。我们引入这个模型,是为了帮助理解向量的概念,以及向量如何成为词义表示;但更复杂的变体同样重要,例如第 11 章会介绍的 tf-idf 模型。我们会看到,这种方法会产生非常长而稀疏的向量,也就是大多数元素为零的向量,因为大多数词根本不会出现在其他词的上下文中。随后我们会介绍 word2vec 模型族,它可以构建较短的稠密向量,并具有更有用的语义性质。
我们还会介绍余弦(cosine):使用嵌入计算两个词、两个句子或两个文档之间语义相似性的标准方法,也是实际应用中的重要工具。
5.3 简单的基于计数的嵌入
“三维空间中一个向量最重要的属性是:位置、位置、位置。”
——Randall Munroe,https://xkcd.com/2358/ 的悬停文字
现在介绍计算词向量嵌入的第一种方法。这个最简单的意义向量模型基于共现矩阵,它表示词共同出现的频率。我们将定义一种特定的共现矩阵,称为词-上下文矩阵(word-context matrix):矩阵中的每一行表示词汇表中的一个词,每一列表示其他每个词在其附近出现的次数。因此,这个矩阵的维度是 $|V|\times |V|$,每个单元格记录某个行词(目标词)与某个列词(上下文词)在训练语料中的近邻位置共同出现的次数。
“附近”是什么意思?可以有多种实现方法,但我们先从一个很简单的方法开始:围绕该词取一个上下文窗口,比如左边 4 个词和右边 4 个词。这样,每个单元格就表示:在某个训练语料中,列词出现在行词周围 $\pm 4$ 词窗口中的次数。
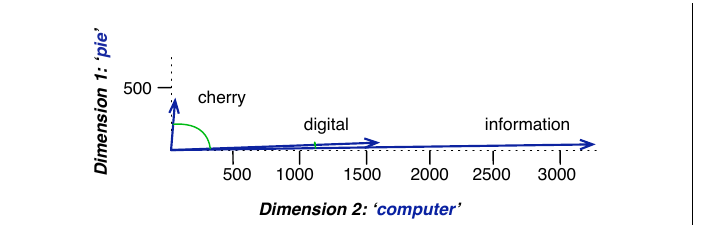
看看这对四个词如何工作:cherry、strawberry、digital 和 information。我们为每个词从语料中取一个实例,并展示该实例的 $\pm 4$ 词窗口:
is traditionally followed by cherry pie, a traditional dessert
often mixed, such as strawberry rhubarb pie. Apple pie
computer peripherals and personal digital assistants. These devices usually
a computer. This includes information available on the internet
如果随后取大型语料中每个词的每一次出现,并统计它周围的上下文词,我们就得到一个词-上下文共现矩阵。完整的词-上下文共现矩阵非常大,因为对词汇表中的每个词(即 $|V|$ 个词),我们都必须统计它与词汇表中其他每个词共同出现的频率,因此维度为 $|V|\times |V|$。为了简化说明,我们只在小尺度上勾勒这个过程。假设我们只考察这 4 个词,并且只考虑 3 个上下文词:a、computer 和 pie。此外,假设我们只统计上面的迷你语料。
在看图 5.2 之前,请先手工计算这 3 个上下文词相对于 cherry、strawberry、digital 和 information 这四个词的计数。

希望你的计数与图 5.2 中所示相同;每个单元格表示某个特定词(由行定义)在某个特定上下文(由列词定义)中出现的次数。
于是,每一行都是表示一个词的向量。回顾一些基本线性代数:向量本质上只是一个数字列表或数组。因此,cherry 表示为列表 $[1,0,1]$(图 5.2 的第一行向量),information 表示为列表 $[1,1,0]$(第四行向量)。
向量空间是一组向量,并由其维度刻画。三维向量空间中的向量在空间的每个维度上都有一个元素。我们会宽松地把三维空间中的向量称为三维向量,也就是每个维度上有一个元素。图 5.2 的例子中,我们把文档向量设为 3 维,只是为了能放在页面上;在真实的词-文档矩阵中,文档向量的维度会是 $|V|$,即词汇表大小。
向量空间中数字的顺序表示文档发生变化的不同维度。对这些向量来说,第三个维度对应上下文中 pie 出现的次数,第二个维度对应 computer 出现的次数。注意,information 和 digital 在这个 “computer” 维度上的值相同,都是 1。
实际上,我们不会只在单个上下文窗口上计算词向量,而是在整个语料上计算。看看一些真实计数是什么样的。图 5.3 展示了这四个词的词-词共现矩阵的一个子集;同样,因为在这本教材的页面上不可能展示所有 $|V|$ 个可能的上下文词,所以这里只展示 6 个维度的子集,这些计数来自 Wikipedia 语料(Davies, 2015)。

注意图 5.3 中,cherry 和 strawberry 彼此更相似(pie 和 sugar 都倾向于出现在它们的窗口中),而不太像 digital 这样的词;反过来,digital 与 information 彼此更相似,而不像 strawberry。
我们可以把文档的向量看作 $|V|$ 维空间中的一个点;因此图 5.3 中的文档就是三维空间中的点。图 5.4 展示了一个空间可视化。
注意,$|V|$,即向量的维度,通常是词汇表大小,常在 10,000 到 50,000 个词之间(使用训练语料中最常见的词;保留约 50,000 个最常见词之后的词通常帮助不大)。由于这些数字大多数为零,这些表示是稀疏向量表示;有高效算法可用于存储和计算稀疏矩阵。
也可以对这些单元格中的计数应用各种加权函数。最常见的加权是 tf-idf,我们将在第 11 章介绍;历史上也曾使用过各种其他加权方式。
有了这些直觉之后,我们转向考察计算词相似性的细节。
5.4 用余弦度量相似性
为了度量两个目标词 $\mathbf{v}$ 和 $\mathbf{w}$ 之间的相似性,我们需要一个度量:它接收两个相同维度的向量(要么两者都以词为维度,因此长度为 $|V|$;要么两者都以文档为维度,因此长度为 $|D|$),并给出它们相似程度的数值。到目前为止,最常用的相似性度量是两个向量夹角的余弦。
和 NLP 中大多数向量相似性度量一样,余弦基于线性代数中的点积(dot product)算子,也称为内积:
点积可以作为相似性度量,因为当两个向量在相同维度上都有较大取值时,它通常会很高。相反,在不同维度上为零的向量,也就是正交向量,其点积为 0,表示强烈不相似。
不过,原始点积作为相似性度量存在一个问题:它偏好长向量。向量长度定义为
如果向量更长、各维度取值更高,点积就会更高。更频繁的词有更长的向量,因为它们倾向于与更多词共同出现,并且与每个词的共现值也更高。因此,原始点积对高频词会更高。但这会造成问题;我们希望相似性度量能够告诉我们两个词有多相似,而不受它们频率的影响。
我们通过把点积除以两个向量各自的长度来对向量长度进行归一化。这个归一化点积恰好等于两个向量夹角的余弦,这来自两个向量 $\mathbf{a}$ 和 $\mathbf{b}$ 的点积定义:
因此,两个向量 $\mathbf{v}$ 和 $\mathbf{w}$ 之间的余弦相似度可以计算为:
在一些应用中,我们会预先对每个向量归一化,也就是除以它的长度,创建长度为 1 的单位向量。因此,可以通过把 $\mathbf{a}$ 除以 $|\mathbf{a}|$ 来得到 $\mathbf{a}$ 的单位向量。对于单位向量来说,点积就等于余弦。
余弦值的范围从 1(两个向量指向相同方向)到 0(正交向量),再到 -1(两个向量指向相反方向)。但由于原始频率值非负,这些向量的余弦范围是 0 到 1。
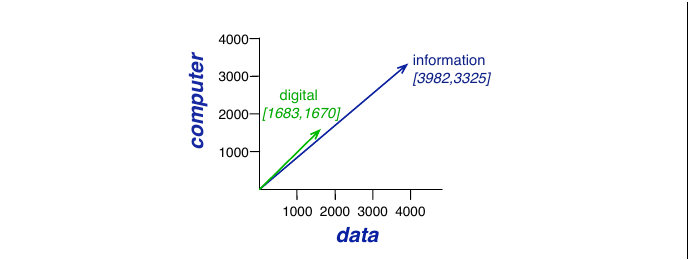
我们用下面这个缩短后的表,只使用原始计数,看看余弦如何判断 cherry 和 digital 中哪一个在意义上更接近 information:
| pie | data | computer | |
|---|---|---|---|
| cherry | 442 | 8 | 2 |
| digital | 5 | 1683 | 1670 |
| information | 5 | 3982 | 3325 |
模型判断 information 比起 cherry 更接近 digital,这是一个合理的结果。图 5.5 给出了可视化。
余弦相似度可以用来估计词相似性,服务于寻找词语复述、跟踪词义变化,或自动发现不同语料中的词义等任务。例如,我们可以通过计算任意目标词 $\mathbf{w}$ 与其他 $|V|-1$ 个词之间的余弦,排序并查看前 10 个结果,找到与目标词最相似的 10 个词。
5.5 Word2vec
前几节看到,我们可以把一个词表示为一个稀疏的长向量,其维度对应词汇表中的词。现在介绍一种更强大的词表示:嵌入,也就是短的稠密向量。不同于目前看到的向量,嵌入很短,维度数 $d$ 通常在 50 到 1000 之间,而不是大得多的词汇表大小 $|V|$。这些 $d$ 个维度没有清晰的解释。向量是稠密的:向量条目不再是稀疏的、多数为零的计数或计数函数,而是可以为负的实数值。
事实证明,在每个 NLP 任务中,稠密向量都比稀疏向量效果更好。虽然我们并不完全理解所有原因,但有一些直觉。把词表示为 300 维稠密向量,比把词表示为 50,000 维向量要求分类器学习少得多的权重;更小的参数空间可能有助于泛化并避免过拟合。稠密向量也可能更好地捕捉同义关系。例如,在稀疏向量表示中,car 和 automobile 这样的同义词维度是不同且互不相关的;因此,稀疏向量可能无法捕捉一个词以 car 为邻近词和另一个词以 automobile 为邻近词之间的相似性。
本节介绍一种计算嵌入的方法:带负采样的 skip-gram,有时称为 SGNS。skip-gram 算法是 word2vec 这个软件包中的两种算法之一,因此有时这个算法也被宽泛地称为 word2vec(Mikolov et al. 2013a; Mikolov et al. 2013b)。word2vec 方法训练快速、高效,而且网上很容易获得代码和预训练嵌入。word2vec 嵌入是静态嵌入,意思是该方法为词汇表中的每个词学习一个固定嵌入。第 9 章会介绍学习动态上下文化嵌入的方法,例如流行的 BERT 表示族;在这类表示中,同一个词在不同上下文中的向量不同。
word2vec 的直觉是:我们不再统计每个上下文词 $c$ 在比如 apricot 附近出现的频率,而是训练一个二元预测任务的分类器:“词 $c$ 是否可能出现在 apricot 附近?” 我们并不真正关心这个预测任务本身;相反,我们会把学习到的分类器权重作为词嵌入。
这里革命性的直觉是:可以直接把连续文本作为这种分类器的隐式监督训练数据;出现在目标词 apricot 附近的词 $c$,就是问题 “词 $c$ 是否可能出现在 apricot 附近?” 的金标准正确答案。这种方法通常称为自监督,避免了任何手工标注的监督信号。这个想法最早出现在神经语言建模任务中:Bengio et al.(2003)和 Collobert et al.(2011)表明,神经语言模型(一种学习根据前面的词预测下一个词的神经网络)可以直接把连续文本中的下一个词作为监督信号,并在完成这个预测任务的过程中为每个词学习一个嵌入表示。
下一章会介绍神经网络,但 word2vec 比神经网络语言模型简单得多,体现在两个方面。第一,word2vec 简化了任务,把词预测改成二元分类。第二,word2vec 简化了架构,训练的是逻辑回归分类器,而不是带隐藏层、需要更复杂训练算法的多层神经网络。skip-gram 的直觉如下:
- 把目标词和一个相邻上下文词作为正例。
- 从词典中随机采样其他词,得到负样本。
- 用逻辑回归训练一个分类器来区分这两种情况。
- 使用学到的权重作为嵌入。
5.5.1 分类器
先考虑分类任务,再讨论如何训练。设想如下句子,其中目标词是 apricot,并假设我们使用 $\pm 2$ 个上下文词的窗口:
... lemon, a [tablespoon of apricot jam, a] pinch ...
c1 c2 w c3 c4
我们的目标是训练一个分类器,使得给定一个目标词 $w$ 与候选上下文词 $c$ 组成的元组 $(w,c)$(例如 $(\textit{apricot}, \textit{jam})$,也可能是 $(\textit{apricot}, \textit{aardvark})$),分类器返回 $c$ 是真实上下文词的概率(对 jam 为真,对 aardvark 为假):
词 $c$ 不是 $w$ 的真实上下文词的概率,就是 1 减去式 (5.11):
分类器如何计算概率 $P$?skip-gram 模型的直觉,是把这个概率建立在嵌入相似性上:如果一个词的嵌入向量与目标词嵌入相似,那么它就更可能出现在目标词附近。为了计算这些稠密嵌入之间的相似性,我们依赖一个直觉:两个向量如果点积较高,就相似;毕竟余弦只是归一化的点积。换言之:
点积 $\mathbf{c}\cdot\mathbf{w}$ 不是概率;它只是一个从 $-\infty$ 到 $\infty$ 的数(由于 word2vec 嵌入中的元素可以为负,点积也可以为负)。为了把点积转换成概率,我们使用逻辑函数或 sigmoid 函数 $\sigma(x)$,也就是逻辑回归的核心:
我们把词 $c$ 是目标词 $w$ 的真实上下文词的概率建模为:
sigmoid 函数返回 0 到 1 之间的数,但要使它成为概率,我们还需要两个可能事件($c$ 是上下文词,$c$ 不是上下文词)的总概率加起来为 1。因此,我们估计词 $c$ 不是 $w$ 的真实上下文词的概率为:
式 (5.15) 给出了一个词的概率,但窗口中有许多上下文词。skip-gram 做出一个简化假设:所有上下文词彼此独立,因此可以直接相乘:
总结来说,skip-gram 训练一个概率分类器。给定测试目标词 $w$ 及其由 $L$ 个词组成的上下文窗口 $c_{1:L}$,分类器根据这个上下文窗口与目标词的相似程度分配概率。该概率通过对目标词嵌入和每个上下文词嵌入的点积应用逻辑函数(sigmoid)得到。为了计算这个概率,我们只需要词汇表中每个目标词和上下文词的嵌入。
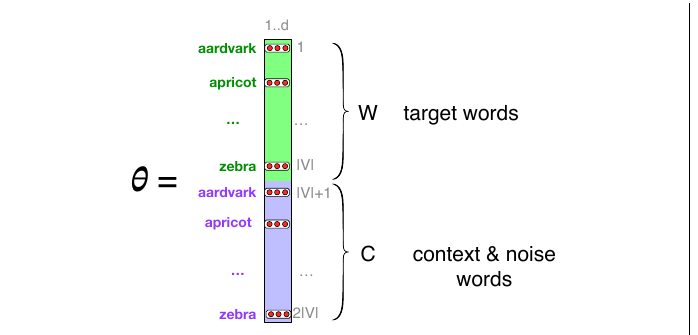
图 5.6 展示了我们所需参数的直觉。skip-gram 实际上为每个词存储两个嵌入:一个用于词作为目标词时,另一个用于词作为上下文时。因此,我们需要学习的参数是两个矩阵 $W$ 和 $C$,它们都为词汇表 $V$ 中的每个 $|V|$ 词存储一个嵌入。[注 2] 下面转向学习这些嵌入;这也是训练这个分类器的真正目标。
5.5.2 学习 skip-gram 嵌入
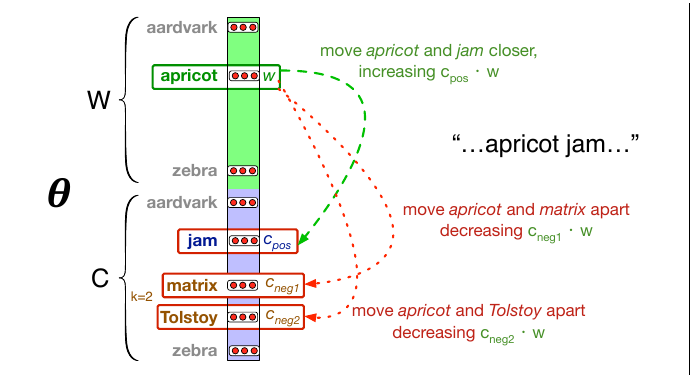
skip-gram 嵌入的学习算法以文本语料和选定的词汇表大小 $N$ 作为输入。它先为 $N$ 个词汇表词中的每个词分配一个随机嵌入向量,然后迭代地移动每个词 $w$ 的嵌入,使它更像文本中出现在附近的词的嵌入,更不像没有出现在附近的词的嵌入。先考虑一条训练数据:
... lemon, a [tablespoon of apricot jam, a] pinch ...
c1 c2 w c3 c4
这个例子有一个目标词 $w$(apricot),以及 $L=\pm2$ 窗口中的 4 个上下文词,于是得到 4 个正训练实例(下表左侧):
| 正例 + | 负例 - | ||||
|---|---|---|---|---|---|
| $w$ | $c_{\text{pos}}$ | $w$ | $c_{\text{neg}}$ | $w$ | $c_{\text{neg}}$ |
| apricot | tablespoon | apricot | aardvark | apricot | seven |
| apricot | of | apricot | my | apricot | forever |
| apricot | jam | apricot | where | apricot | dear |
| apricot | a | apricot | coaxial | apricot | if |
为了训练二元分类器,我们还需要负例。事实上,带负采样的 skip-gram(SGNS)使用的负例比正例更多,二者比例由参数 $k$ 决定。因此,对每个 $(w,c_{\text{pos}})$ 训练实例,我们会创建 $k$ 个负样本,每个负样本由目标词 $w$ 加上一个噪声词 $c_{\text{neg}}$ 组成。噪声词是词典中的随机词,约束是不能等于目标词 $w$。上表右侧展示了 $k=2$ 的设置,因此对每个正例 $w,c_{\text{pos}}$,负训练集 $-$ 中会有 2 个负例。
噪声词按照加权一元概率 $p_{\alpha}(w)$ 选择,其中 $\alpha$ 是权重。如果按照未加权概率 $P(w)$ 采样,这意味着我们会以一元概率 $P(\text{``the''})$ 选择 the 作为噪声词,以一元概率 $P(\text{``aardvark''})$ 选择 aardvark,依此类推。但实践中通常设置 $\alpha=0.75$,也就是使用加权 $P_{3/4}(w)$:
设置 $\alpha=.75$ 会带来更好性能,因为它会稍微提高罕见噪声词的概率:对罕见词,$P_{\alpha}(w)>P(w)$。为了说明这个直觉,不妨计算一个例子:$\alpha=.75$,两个事件 $P(a)=0.99$ 和 $P(b)=0.01$:
因此,使用 $\alpha=.75$ 会把罕见事件 $b$ 的概率从 0.01 提高到 0.03。
给定正、负训练实例集合以及初始嵌入集合,学习算法的目标是调整这些嵌入,以便:
- 最大化来自正例的目标词与上下文词对 $(w,c_{\text{pos}})$ 的相似性。
- 最小化来自负例的 $(w,c_{\text{neg}})$ 对的相似性。
如果考虑一个词/上下文对 $(w,c_{\text{pos}})$ 及其 $k$ 个噪声词 $c_{\text{neg},1}\ldots c_{\text{neg},k}$,可以把这两个目标表示为下面要最小化的损失函数 $L$(因此带有负号)。第一项表示我们希望分类器给真实上下文词 $c_{\text{pos}}$ 分配较高的邻居概率,第二项表示我们希望给每个噪声词 $c_{\text{neg},i}$ 分配较高的非邻居概率;由于假设独立,所以概率相乘:
也就是说,我们希望最大化目标词与真实上下文词的点积,并最小化目标词与 $k$ 个负采样非邻居词的点积。
我们使用随机梯度下降来最小化这个损失函数。图 5.7 展示了一步学习的直觉。
为了得到梯度,需要分别对式 (5.21) 关于不同嵌入求导。可以证明导数如下(证明留作本章末练习):
因此,在随机梯度下降中,从时间步 $t$ 到 $t+1$ 的更新方程为:
于是,与逻辑回归一样,学习算法从随机初始化的 $W$ 和 $C$ 矩阵开始,然后遍历训练语料,使用梯度下降移动 $W$ 和 $C$,通过式 (5.25)–(5.27) 的更新来最小化式 (5.21) 中的损失。
回忆一下,skip-gram 模型为每个词 $i$ 学习两个单独的嵌入:目标嵌入 $\mathbf{w}_i$ 和上下文嵌入 $\mathbf{c}_i$,分别存储在两个矩阵中,即目标矩阵 $W$ 和上下文矩阵 $C$。常见做法是直接把它们相加,用向量 $\mathbf{w}_i+\mathbf{c}_i$ 表示词 $i$。另一种做法是丢弃 $C$ 矩阵,只用向量 $\mathbf{w}_i$ 表示每个词 $i$。
与 tf-idf 等简单计数方法一样,上下文窗口大小会影响 skip-gram 嵌入的性能;实验中通常会在开发集上调节上下文窗口大小参数。
5.5.3 其他静态嵌入
静态嵌入有许多种。word2vec 的一个扩展是 fastText(Bojanowski et al., 2017),它解决了目前介绍的 word2vec 的一个问题:无法很好地处理未知词,即出现在测试语料中但没有出现在训练语料中的词。相关的另一个问题是词稀疏性,例如在形态丰富的语言中,每个名词和动词可能有许多形式,其中一些形式出现得很少。fastText 通过使用子词模型来处理这些问题:把每个词表示为词本身加上一袋组成它的 n-gram,并在每个词上添加特殊边界符号 < 和 >。例如,当 $n=3$ 时,单词 where 会表示为序列 <where> 加上字符 n-gram:
<wh, whe, her, ere, re>
随后为每个组成 n-gram 学习一个 skip-gram 嵌入,而单词 where 则由其所有组成 n-gram 的嵌入之和表示。未知词也可以只用其组成 n-gram 的嵌入之和来表示。fastText 开源库包含 157 种语言的预训练嵌入,可在 https://fasttext.cc 获得。
另一个使用非常广泛的静态嵌入模型是 GloVe(Pennington et al., 2014),全称为 Global Vectors,因为该模型基于捕捉全局语料统计。GloVe 建立在词-词共现矩阵的概率比值之上。
事实证明,像 word2vec 这样的稠密嵌入实际上与基于计数的嵌入有一种优雅的数学关系:word2vec 可以看作是在隐式优化某个计数矩阵的函数,并带有特定的 PPMI 加权(Levy and Goldberg, 2014c)。
5.6 嵌入的可视化
“只要维度大约是二维,我就能很好地看见许多维度。”
——已故经济学家 Martin Shubik
可视化嵌入是理解、应用和改进这些词义模型的重要目标。但我们如何可视化一个例如 100 维的向量?
可视化空间中某个词 $w$ 的意义的最简单方法,是列出与它最相似的词:对词汇表中所有词的向量按其与 $w$ 向量的余弦排序。例如,使用某组由 GloVe 算法计算得到的嵌入,与 frog 最近的 7 个词是:frogs、toad、litoria、leptodactylidae、rana、lizard 和 eleutherodactylus(Pennington et al., 2014)。
另一种可视化方法,是使用聚类算法来显示一种层级表示,说明嵌入空间中哪些词与哪些词相似。下图使用了一些名词嵌入向量的层次聚类作为可视化方法(Rohde et al., 2006)。
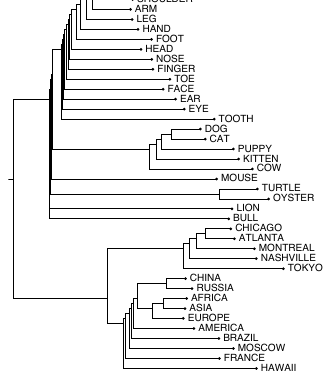
不过,最常见的可视化方法大概是把一个词的 100 个维度投影到 2 个维度。图 5.1 展示了这样一种可视化,图 5.9 也是如此;它们使用了一种称为 t-SNE 的投影方法(van der Maaten and Hinton, 2008)。
5.7 嵌入的语义性质
本节简要总结一些已经被研究过的嵌入语义性质。
不同类型的相似性或关联性
向量语义模型的一个参数,同时影响稀疏 PPMI 向量和稠密 word2vec 向量,就是用于收集计数的上下文窗口大小。这个窗口通常在目标词左右各 1 到 10 个词之间,即总上下文为 2 到 20 个词。
如何选择窗口大小取决于表示的目标。较短的上下文窗口往往会产生更偏句法的表示,因为信息来自紧邻的词。当向量由短上下文窗口计算时,目标词 $w$ 的最相似词往往是词性相同的语义相似词。当向量由长上下文窗口计算时,与目标词 $w$ 余弦最高的词往往是在主题上相关但并不相似的词。
例如,Levy and Goldberg(2014a)显示,使用窗口为 $\pm2$ 的 skip-gram 时,与 Hogwarts(来自《哈利·波特》系列)最相似的词是其他虚构学校的名称:Sunnydale(来自《吸血鬼猎人巴菲》)或 Evernight(来自某个吸血鬼系列)。当窗口为 $\pm5$ 时,与 Hogwarts 最相似的词则是其他与《哈利·波特》系列主题相关的词:Dumbledore、Malfoy 和 half-blood。
区分词之间两种相似性或关联性也常常有用(Schutze and Pedersen, 1993)。如果两个词通常彼此相邻,就称它们具有一阶共现(first-order co-occurrence),有时也称为组合关联(syntagmatic association)。因此,wrote 是 book 或 poem 的一阶关联词。如果两个词拥有相似的邻近词,就称它们具有二阶共现(second-order co-occurrence),有时也称为聚合关联(paradigmatic association)。因此,wrote 是 said 或 remarked 这类词的二阶关联词。
类比/关系相似性
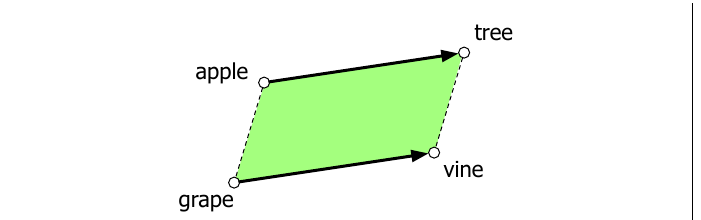
嵌入的另一种语义性质,是它们捕捉关系意义的能力。在一个重要的早期认知向量空间模型中,Rumelhart and Abrahamson(1973)提出了平行四边形模型,用于解决形如 “$a$ 之于 $b$,就像 $a^*$ 之于什么?” 的简单类比问题。在这类问题中,系统得到类似 apple:tree::grape:? 的题目,也就是 “apple 之于 tree,正如 grape 之于 ____”,并且必须填入 vine。在图 5.8 所示的平行四边形模型中,从 apple 到 tree 的向量($\vec{\mathrm{tree}}-\vec{\mathrm{apple}}$)被加到 grape 的向量上;然后返回离该点最近的词。
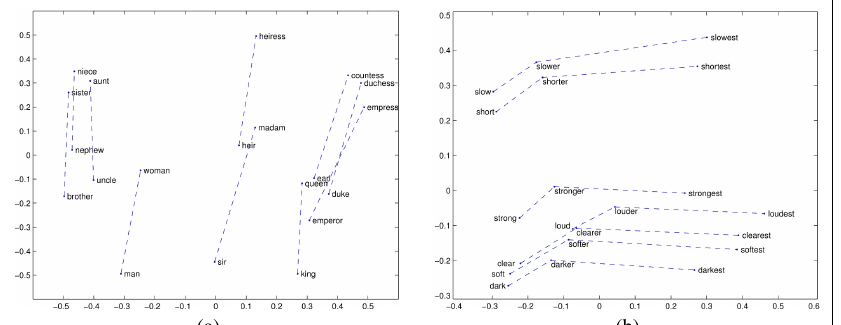
早期关于稀疏嵌入的研究显示,稀疏词义向量模型可以解决这类类比问题(Turney and Littman, 2005)。但平行四边形方法之所以获得更多现代关注,是因为它在 word2vec 或 GloVe 向量上的成功(Mikolov et al. 2013c; Levy and Goldberg 2014b; Pennington et al. 2014)。例如,表达式 $\vec{\mathrm{king}}-\vec{\mathrm{man}}+\vec{\mathrm{woman}}$ 的结果,是一个接近 queen 的向量。类似地,$\vec{\mathrm{Paris}}-\vec{\mathrm{France}}+\vec{\mathrm{Italy}}$ 会得到一个接近 Rome 的向量。因此,嵌入模型似乎提取出了 MALE-FEMALE、CAPITAL-CITY-OF,甚至 COMPARATIVE/SUPERLATIVE 这类关系的表示,如图 5.9 中来自 GloVe 的例子所示。
对于一个 $a:b::a^*:b^*$ 问题,也就是算法得到向量 $\mathbf{a}$、$\mathbf{b}$ 和 $\mathbf{a}^*$,并且必须找到 $\mathbf{b}^*$,平行四边形方法为:
其中可以使用某个距离函数,例如欧氏距离。
这里有一些注意事项。例如,在 word2vec 或 GloVe 嵌入空间中,平行四边形算法返回的最近值通常事实上不是 $b^*$,而是三个输入词之一或其形态变体;例如 cherry:red::potato:x 会返回 potato 或 potatoes,而不是 brown,因此这些词必须被显式排除。此外,当任务涉及高频词、小距离以及某些关系(如国家与首都、动词/名词与其屈折形式)时,嵌入空间表现良好;但对其他关系,平行四边形方法的效果并不好(Linzen 2016; Gladkova et al. 2016; Schluter 2018; Ethayarajh et al. 2019a)。事实上,Peterson et al.(2020)认为,平行四边形方法总体上过于简单,无法建模人类形成这类类比的认知过程。
5.7.1 嵌入与历史语义学
嵌入还可以成为研究意义随时间变化的有用工具:我们可以计算多个嵌入空间,每个空间来自某一特定时期写成的文本。例如,图 5.10 展示了过去两个世纪中英语词义变化的可视化;它通过为每个十年从历史语料构建独立嵌入空间得到,这些语料包括 Google n-grams(Lin et al., 2012b)和 Corpus of Historical American English(Davies, 2012)。

5.8 偏见与嵌入
除了能够从文本中学习词义之外,嵌入遗憾地也会再现文本中潜伏的隐性偏见和刻板印象。如上一节所示,嵌入可以粗略建模关系相似性:“queen” 是最接近 “king” - “man” + “woman” 的词,这意味着 man:woman::king:queen 这个类比。但这些嵌入类比同样也表现出性别刻板印象。例如,Bolukbasi et al.(2016)发现,在新闻文本上训练的 word2vec 嵌入中,最接近 “computer programmer” - “man” + “woman” 的职业是 “homemaker”;这些嵌入还类似地暗示 “father” 之于 “doctor”,正如 “mother” 之于 “nurse”。这可能导致 Crawford(2017)和 Blodgett et al.(2020)所称的分配性伤害(allocational harm):系统对不同群体不公平地分配资源(工作或信贷)。例如,将嵌入作为招聘潜在程序员或医生的搜索的一部分的算法,可能因此错误地下调包含女性姓名的文档权重。
事实证明,嵌入不只是反映输入统计,还会放大偏见:性别化词语在嵌入空间中比它们在输入文本统计中更性别化(Zhao et al. 2017; Ethayarajh et al. 2019b; Jia et al. 2020),并且偏见比真实劳动就业统计中的偏见更加夸张(Garg et al., 2018)。
嵌入还编码了人类推理中的隐性联想。隐性联想测验(Implicit Association Test; Greenwald et al., 1998)通过测量人们给不同类别词贴标签所需反应时的差异,来度量概念(如 “flowers” 或 “insects”)与属性(如 “pleasantness” 和 “unpleasantness”)之间的联想。[注 3] 使用这类方法,研究显示美国人会把非裔美国人姓名更多地与不愉快词联系起来(相对于欧洲裔美国人姓名),把男性姓名更多地与数学、女性姓名与艺术联系起来,也把老年人的姓名与不愉快词联系起来(Greenwald et al. 1998; Nosek et al. 2002a; Nosek et al. 2002b)。Caliskan et al.(2017)使用 GloVe 向量和余弦相似度,而不是人类反应时,复现了所有这些隐性联想结果。例如,像 “Leroy” 和 “Shaniqua” 这样的非裔美国人姓名与不愉快词具有更高的 GloVe 余弦,而欧洲裔美国人姓名(“Brad”、“Greg”、“Courtney”)与愉快词具有更高余弦。嵌入中的这些问题是表征性伤害(representational harm)的例子(Crawford 2017; Blodgett et al. 2020),也就是系统贬低甚至忽视某些社会群体而造成的伤害。因此,任何使用词情感的、知道嵌入的算法,都可能加剧针对非裔美国人的偏见。
近期研究关注如何尝试移除这类偏见。例如,开发一种嵌入空间变换,以移除性别刻板印象但保留定义性的性别(Bolukbasi et al. 2016; Zhao et al. 2017),或者改变训练过程(Zhao et al., 2018b)。然而,尽管这类去偏(debiasing)可能减少嵌入中的偏见,但并不能消除偏见(Gonen and Goldberg, 2019);这仍然是一个开放问题。
历史嵌入也被用于度量过去的偏见。Garg et al.(2018)使用来自历史文本的嵌入,度量职业嵌入与不同族裔或性别姓名嵌入之间的关联,例如女性姓名相对于男性姓名与 librarian 或 carpenter 等职业词的相对余弦相似度,时间跨度覆盖 20 世纪。他们发现,这些余弦与这些职业中女性或族裔群体的经验历史比例相关。历史嵌入还复现了关于族裔刻板印象的旧调查:1933 年实验参与者把 industrious 或 superstitious 等形容词与例如华人族裔联系起来的倾向,与在 1930 年代文本上训练的嵌入中中文姓氏与这些形容词之间的余弦相关。他们还能够记录历史性别偏见,例如与能力有关的形容词(smart, wise, thoughtful, resourceful)的嵌入与男性词的余弦高于与女性词的余弦,并表明这种偏见自 1960 年以来一直在缓慢下降。后续章节会再次讨论偏见在自然语言处理中的作用。
5.9 评估向量模型
向量模型最重要的评估指标是在任务上的外在评估(extrinsic evaluation),也就是把向量用于某个 NLP 任务,并观察它是否相对其他模型改善了性能。
尽管如此,内在评估(intrinsic evaluation)也很有用。最常见的指标是测试模型在相似性上的表现:计算算法给出的词相似度分数与人类分配的词相似度评分之间的相关性。WordSim-353(Finkelstein et al., 2002)是一组常用评分,包含 353 个名词对,评分范围为 0 到 10;例如,(plane, car) 的平均分是 5.77。SimLex-999(Hill et al., 2015)是一个更复杂的数据集,它量化的是相似性(cup, mug),而不是相关性(cup, coffee),并包含具体和抽象的形容词、名词和动词词对。TOEFL 数据集包含 80 个问题,每个问题由一个目标词和 4 个额外选项组成;任务是选择正确的同义词。例如:Levied 在意义上最接近哪个词?imposed, believed, requested, correlated(Landauer and Dumais, 1997)。所有这些数据集都在没有上下文的情况下呈现词。
略微更现实的是包含上下文的内在相似性任务。Stanford Contextual Word Similarity(SCWS)数据集(Huang et al., 2012)和 Word-in-Context(WiC)数据集(Pilehvar and Camacho-Collados, 2019)提供了更丰富的评估场景。SCWS 给出 2,003 对处在句子上下文中的词的人类判断,而 WiC 给出两个句子上下文中的目标词,这两个词义要么相同,要么不同;参见附录 G。语义文本相似性任务(Agirre et al. 2012; Agirre et al. 2015)评估句子级相似性算法的性能,数据由若干句子对组成,每个句子对都带有人类标注的相似度分数。
另一个用于评估的任务是第 112 页讨论过的类比任务。在这个任务中,系统必须解决形如 $a$ 之于 $b$,正如 $a^*$ 之于 $b^*$ 的问题:给定 $a$、$b$ 和 $a^*$,找出 $b^*$(Turney and Littman, 2005)。为此已经创建了许多元组集合(Mikolov et al. 2013a; Mikolov et al. 2013c; Gladkova et al. 2016),覆盖形态关系(city:cities::child:children)、词典关系(leg:table::spout:teapot)和百科关系(Beijing:China::Dublin:Ireland)。其中一些关系来自 SemEval-2012 Task 2 数据集的 79 种不同关系(Jurgens et al., 2012)。
所有嵌入算法都存在固有变异性。例如,由于初始化和随机负采样中的随机性,像 word2vec 这样的算法即使在同一数据集上也可能产生不同结果;集合中的单个文档也可能强烈影响得到的嵌入(Tian et al. 2016; Hellrich and Hahn 2016; Antoniak and Mimno 2018)。因此,当嵌入用于研究特定语料中的词联想时,最佳实践是对文档进行 bootstrap 采样,训练多个嵌入,并对结果求平均(Antoniak and Mimno, 2018)。
5.10 小结
- 在向量语义学中,词被建模为一个向量,也就是高维空间中的一个点,也称为嵌入。本章关注静态嵌入,其中每个词被映射到一个固定嵌入。
- 向量语义模型分为两类:稀疏模型和稠密模型。在稀疏模型中,每个维度对应词汇表 $V$ 中的一个词,单元格是共现计数的函数。词-上下文矩阵或项-项矩阵,对词汇表中的每个(目标)词有一行,对词汇表中的每个上下文项有一列。
- 稠密向量模型通常具有 50 到 1000 的维度。像 skip-gram 这样的 word2vec 算法,是计算稠密嵌入的一种流行方式。skip-gram 训练一个逻辑回归分类器,用来计算两个词 “可能在文本中相邻出现” 的概率。这个概率由两个词嵌入的点积计算得到。
- skip-gram 使用随机梯度下降来训练分类器:它学习使得附近出现的词的嵌入之间点积较高、与噪声词的嵌入之间点积较低的嵌入。
- 其他重要嵌入算法包括 GloVe,这是一种基于词共现概率比值的方法。
- 无论使用稀疏向量还是稠密向量,词与文档的相似性都由向量之间点积的某种函数来计算。两个向量的余弦,也就是归一化点积,是最流行的这类度量。
历史注记
向量语义学的思想来自 20 世纪 50 年代三个不同领域的研究:语言学、心理学和计算机科学。每个领域都贡献了模型的一个基本方面。
意义与词在上下文中的分布有关这一思想,在 20 世纪 50 年代的语言学理论中很普遍,出现在 Zellig Harris、Martin Joos 和 J. R. Firth 等分布主义者,以及 Thomas Sebeok 等符号学家的工作中。正如 Joos(1950)所说:
语言学家所谓语素的 “意义” ……按定义就是它与所有其他语素共同出现在上下文中的条件概率集合。
词义可以被建模为多维语义空间中的一个点这一思想,来自 Charles E. Osgood 等心理学家。他们研究人们如何通过在 happy/sad 或 hard/soft 等量表上赋值来回应词义。Osgood et al.(1957)提出,一个词的一般意义可以被建模为多维欧氏空间中的一个点,而两个词之间意义的相似性可以建模为这个空间中这些点之间的距离。
20 世纪 50 年代和 60 年代初的第三个思想来源,是当时称为机械索引、现在称为信息检索的领域。在后来被称为信息检索向量空间模型的工作中(Salton 1971; Sparck Jones 1986),研究者展示了用向量定义词义的新方法(Switzer, 1965),并改进了基于词之间统计关联的词相似性度量,例如互信息(Giuliano, 1965)和 idf(Sparck Jones, 1972),还表明文档的意义可以表示在与词相同的向量空间中。几乎同一时期,Cordier(1965)表明,词联想概率的因子分析可以用于形成词的稠密向量表示。
分布式思考方式的一些哲学基础来自哲学家 Wittgenstein 的晚期著作。他对为每个词建立完全形式化的意义定义理论的可能性持怀疑态度。Wittgenstein 转而提出,“一个词的意义就是它在语言中的使用”(Wittgenstein, 1953, PI 43)。也就是说,与其用某种逻辑语言定义每个词,或诉诸指称和真值,不如通过人们在日常互动中说话和理解时如何使用这个词来定义它。这预示了语言学和 NLP 中转向具身和经验模型的趋势(Glenberg and Robertson 2000; Lake and Murphy 2021; Bisk et al. 2020; Bender and Koller 2020)。
更远一些的相关思想,是用离散特征向量定义词;这一思想的根源至少可以追溯到 Descartes 和 Leibniz(Wierzbicka 1992; Wierzbicka 1996)。到 20 世纪中叶,从 Hjelmslev(1969,原作 1943)开始,并在生成语法的早期模型中被展开(Katz and Fodor, 1963),出现了用语义特征表示意义的思想:语义特征是表示某种原始意义的符号。例如,hen、rooster 或 chick 这样的词有共同点(都描述鸡),也有差异(年龄和性别),可以表示为:
| hen | +female, +chicken, +adult |
| rooster | -female, +chicken, +adult |
| chick | +chicken, -adult |
不过,向量意义模型用来定义词的维度,只是在抽象层面上与这种少量固定手工维度的思想有关。尽管如此,仍有一些研究尝试说明,嵌入模型中的某些维度确实会贡献某些特定的组合意义方面,类似这些早期语义特征。
使用稠密向量建模词义,以及 embedding 这个术语本身,源自潜在语义索引(Latent Semantic Indexing, LSI)模型(Deerwester et al., 1988),后来被重述为 LSA(Latent Semantic Analysis,潜在语义分析)(Deerwester et al., 1990)。在 LSA 中,奇异值分解(SVD)被应用于项-文档矩阵(每个单元格由对数频率加权并由熵归一化),然后取前 300 个维度作为 LSA 嵌入。奇异值分解(SVD)是一种寻找数据集中最重要维度的方法,即寻找数据变化最大的那些维度。LSA 很快被广泛应用:作为认知模型(Landauer and Dumais, 1997),以及用于拼写检查(Jones and Martin, 1997)、语言建模(Bellegarda 1997; Coccaro and Jurafsky 1998; Bellegarda 2000)、形态归纳(Schone and Jurafsky 2000; Schone and Jurafsky 2001b)、多词表达(MWEs)(Schone and Jurafsky, 2001a)和作文评分(Rehder et al., 1998)等任务。相关模型也几乎同时由 Schutze(1992b)发展出来,并应用于词义消歧。LSA 还促成了最早用嵌入在概率分类器中表示词的工作,即 Schutze et al.(1995)的逻辑回归文档路由器。SVD 应用于项-项矩阵(而不是项-文档矩阵)作为 NLP 意义模型的想法,在 LSA 之后不久由 Schutze(1992b)提出。Schutze 将 SVD 产生的低秩(97 维)嵌入用于词义消歧任务,分析得到的语义空间,并建议了一些可能的技术,如去除高阶维度。参见 Schutze(1997)。
早期 SVD 工作之后,出现了许多替代矩阵模型,包括概率潜在语义索引(PLSI)(Hofmann, 1999)、潜在狄利克雷分配(LDA)(Blei et al., 2003),以及非负矩阵分解(NMF)(Lee and Seung, 1999)。
LSA 社群似乎最早在 Landauer et al.(1997)中使用了 “embedding” 一词,其含义是数学意义的一种变体,即从一个空间或数学结构到另一个空间或结构的映射。在 LSA 中,“word embedding” 似乎描述的是从稀疏计数向量空间到 SVD 稠密向量潜在空间的映射。因此,虽然这个词最初表示从一个空间到另一个空间的映射,但后来发生了转喻性转移,用来表示潜在空间中得到的稠密向量;我们现在就是在这个意义上使用该词。
到了下一个十年,Bengio et al.(2003)和 Bengio et al.(2006)表明,神经语言模型也可以在词预测任务中发展嵌入。随后 Collobert and Weston(2007)、Collobert and Weston(2008)以及 Collobert et al.(2011)展示了嵌入可以用于表示多种 NLP 任务中的词义。Turian et al.(2010)比较了不同类型嵌入在不同 NLP 任务中的价值。Mikolov et al.(2011)表明,循环神经网络可以用作语言模型。简化这些神经网络语言模型的隐藏层以创建 skip-gram(以及 CBOW)算法的想法,由 Mikolov et al.(2013a)提出。负采样训练算法由 Mikolov et al.(2013b)提出。关于静态嵌入及其参数化,有许多综述(Bullinaria and Levy 2007; Bullinaria and Levy 2012; Lapesa and Evert 2014; Kiela and Clark 2014; Levy et al. 2015)。
关于向量在信息检索中的作用,包括如何比较查询与文档、tf-idf 的更多细节,以及扩展到超大数据集时的问题,可参见 Manning et al.(2008)和第 11 章。Kim(2019)是关于 word2vec 的清晰而全面的教程。Cruse(2004)则是一本有用的词汇语义学入门语言学教材。
练习
(本章原文未在 tex 文件中列出具体习题。)