7 大型语言模型
“在任何时候,我们究竟知道多少?我相信,远比我们自知的要多。”
Agatha Christie, The Moving Finger
奇幻文学中充满了被魔法赋予说话能力的无生命物体。从奥维德笔下皮格马利翁的雕像,到 Mary Shelley 关于 Frankenstein 的故事,人们不断重新发明这样一种叙事:创造出某个东西,然后同它交谈。传说 Michelangelo 完成雕塑 Moses 后,觉得它栩栩如生,于是轻敲它的膝盖,命令它开口说话。也许这并不奇怪。语言是人性与感知能力的标志。会话是语言最基本的场域,是我们孩童时期最早学会的语言形式,也是我们不断参与其中的语言活动,无论是在教学、学习、点午餐,还是与家人朋友交谈。

本章介绍大型语言模型(large language model,LLM):一种能够以会话方式与人互动的计算代理。LLM 被设计为与人互动,这一事实对它们的设计和使用有很强的影响。
许多影响在 60 年前的一个计算系统 ELIZA(Weizenbaum, 1966)中就已经变得清晰。ELIZA 被设计成模拟 Rogerian 心理咨询师,它展示了聊天机器人中的若干重要问题。例如,人们会深度投入情感,并与系统进行非常私人的谈话,甚至会要求 Weizenbaum 在他们打字时离开房间。这些情感投入和隐私问题意味着,我们需要认真思考如何部署语言模型,并考虑它们对互动者的影响。
本章先介绍 LLM 的计算原则;下一章会讨论它们在 transformer 架构中的实现。使 LLM 成为可能的核心新思想是预训练。因此,让我们先思考从文本中学习这一基本思想,也就是 LLM 接受训练的基本方式。
我们知道,流利的语言使用者在理解和生成语言时会调用大量知识。这些知识以许多形式体现,其中最明显的也许是词汇:我们对词及其意义和用法拥有丰富表示。因此,词汇为探索人和机器如何从文本中获得知识提供了一个有用视角。
成年人词汇量的估计值在语言内部和跨语言之间差异都很大。例如,对美国英语年轻成年说话者词汇量的估计范围从 30,000 到 100,000 不等,这取决于用于估计的资源以及 “知道一个词” 的定义。这些事实带来一个简单结论:儿童为了在 20 岁时达到观察到的词汇水平,必须每天学习约 7 到 10 个词,并且天天如此。事实上,对小学高年级到高中阶段词汇增长的经验估计也与这一速率一致。儿童如何达到这样的词汇增长速度?研究表明,大部分知识获得是阅读的副产品。阅读是一种丰富的上下文处理过程;我们并不是孤立地一次学习一个词。实际上,在学习的某些阶段,词汇增长率甚至超过新词呈现在学习者面前的速率。这说明,每当我们读到一个词时,也在强化我们对与它相关的其他词的理解。
这些事实与第 5 章的分布假设一致。该假设认为,意义的某些方面可以仅从我们一生中接触的文本中学习出来,其依据是词与其共现词之间,以及那些共现词再与其他词之间的复杂关联。分布假设既说明我们能够从文本中获得惊人的知识量,也说明这些知识在初次获得很久之后仍能被调用。当然,来自真实世界互动或其他模态的 grounding 可以帮助建立更强大的模型,但即便只有文本本身,也已经极其有用。
现代 NLP 革命之所以可能,是因为大型语言模型只需在一个非常大的文本语料中,根据上下文一遍又一遍地学习预测下一个词,就能学到关于语言、上下文和世界的全部这些知识。在本章和下一章中,我们将形式化这一思想,并称之为预训练:通过在海量文本中迭代预测词元,学习关于语言和世界的知识;由此得到的预训练模型称为大型语言模型。大型语言模型在自然语言任务上表现出惊人的性能,正是因为它们在预训练中学到了知识。
语言模型能从词预测中学到什么?考虑下面的例子。为了学会预测下划线位置的词(正确答案在原书中以蓝色显示),模型可能学到哪些知识?请在读下一段之前先逐例思考。
With roses, dahlias, and peonies, I was surrounded by ______ flowers
The room wasn't just big it was ______ enormous
The square root of 4 is ______ 2
The author of “A Room of One's Own” is ______ Virginia Woolf
The professor said that ______ he
从第一句中,模型可以学到玫瑰、大丽花和牡丹都是花这类本体论事实。从第二句中,模型可能学到 enormous 与 big 处在同一尺度上,但程度更强。第三句可以让系统学到数学;第四句可以让系统学到关于世界和历史作家的事实。最后一句则说明,如果模型反复接触这样的句子,它也可能把教授只与男性代词关联起来,或者学到其他会使模型对不同人群表现不公平的关联。
什么是大型语言模型?正如第 3 章所见,语言模型只是一个能够根据先前词预测下一个词的计算系统。也就是说,给定一段上下文或词前缀,语言模型会在可能的下一个词上分配一个概率分布。图 7.1 概略展示了这一思想。
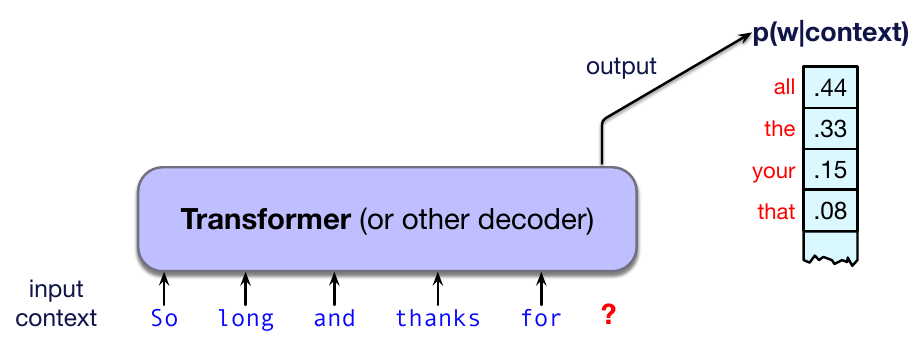
当然,我们已经见过语言模型。第 3 章介绍过 $n$ 元语言模型,第 6 章也简要提到过用于语言建模的前馈网络。大型语言模型只是这些模型的一个大得多的版本。例如,第 3 章介绍的二元和三元语言模型可以根据前一个词或少数几个词预测词。相比之下,大型语言模型可以在给定数千甚至数万个词的上下文时预测词。
语言模型的基本直觉是:一个能够预测文本(即在后续词上分配分布)的模型,也可以通过从该分布中采样来生成文本。回忆第 3 章,采样指的是从一个分布中选择一个词。
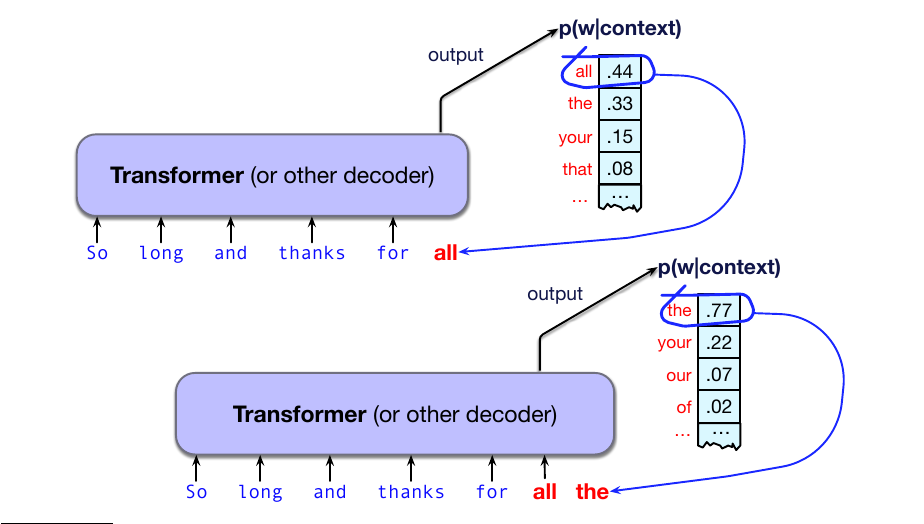
图 7.2 展示了图 7.1 中的同一例子:语言模型得到一个文本前缀,并生成一种可能的补全。模型选择词 all,把它加到上下文中,再用更新后的上下文得到新的预测分布,然后从该分布中选择 the 并生成它,如此继续。注意,模型既以初始提示上下文为条件,也以它自己随后生成的输出为条件。
这种从早先词开始迭代地从左到右预测并生成词的设置,常称为因果或自回归语言模型。(我们将在第 9 章介绍另一类非自回归模型,例如 BERT 和其他掩码语言模型;它们用左侧和右侧的信息来预测词。)
这种用计算模型生成文本,以及生成代码、语音和图像的思想,构成了一个重要的新领域,称为生成式 AI。将 LLM 用于文本生成极大地拓宽了 NLP 的范围;历史上,NLP 更关注解析或理解文本的算法,而不是生成文本。
在本章余下部分,我们将看到,只要换一种合适的思考方式,几乎任何 NLP 任务都可以建模为大型语言模型中的词预测任务;我们也会动机化并介绍提示语言模型的思想。我们将介绍从语言模型生成文本的具体算法,如贪心解码和采样;介绍预训练的细节,也就是语言模型如何通过不断从先前词猜测文本中的下一个词来自训练。我们还会概述语言模型训练的另外两个阶段:指令调优(也称为监督微调,SFT)和对齐;这些概念会在第 10 章回到。最后,我们将看到如何评估这些模型。不过先从不同类型的语言模型谈起。
7.1 语言模型的三种架构
上面为从左到右或自回归语言模型勾勒的架构,也就是本章将定义的语言模型架构,实际上只是三种常见 LM 架构之一。
这三种架构是编码器、解码器和编码器-解码器。图 7.3 给出了三者的示意图。
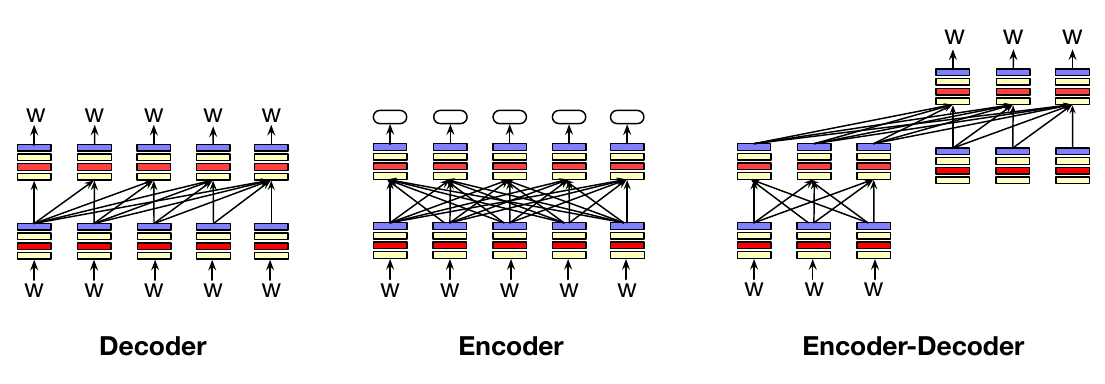
解码器就是我们上面介绍的架构。它以一串词元作为输入,并一次生成一个输出词元。GPT、Claude、Llama 和 Mistral 等大型语言模型都使用解码器架构。解码器中的信息流从左到右,这意味着模型只根据先前词预测下一个词。解码器是生成模型,也就是说,给定输入词元,它们会生成新的输出词元。本章余下部分和第 8 章将继续讨论解码器。
编码器以一串词元作为输入,并为每个词元输出一个向量表示。编码器通常是掩码语言模型,也就是通过遮蔽一个词,并学习从两侧周围词预测它来训练。BERT、RoBERTA 以及其他 BERT 家族的掩码语言模型都是编码器模型。编码器模型不是生成模型;它们不用于生成文本。相反,编码器模型常用于构建分类器,例如输入是文本、输出是情感、主题或其他类别标签。实现方式通常是对它们进行微调,也就是在监督数据上训练。第 9 章会介绍编码器模型。
编码器-解码器以一串词元作为输入,并输出一串词元。它与仅解码器模型的不同之处在于,编码器-解码器中输入词元与输出词元之间的关系松散得多,它们常用于在不同类型词元之间映射。也就是说,在编码器-解码器中,输出词元可能来自完全不同的词元集合,或者输出序列比输入序列长得多或短得多。例如,编码器-解码器架构用于机器翻译,其中输入词元是一种语言,输出词元则是另一种语言(数量可能更多或更少)。编码器-解码器架构也用于语音识别,其中输入是表示语音的词元,输出是表示文本的词元。我们将在第 12 章为机器翻译介绍编码器-解码器架构,并在第 15 章为语音识别介绍它。
这三种架构可以由多种神经网络构建而成。如今最广泛使用的网络类型是第 8 章将介绍的 transformer。在 transformer 中,每个输入词元都由一列 transformer 层处理,每一层由若干不同类型的子网络组成。第 13 章会介绍一种更早但仍然相关的架构 LSTM,它是一种循环神经网络。此外,还有许多更新的架构,如状态空间模型。
本书很大一部分会聚焦于 transformer;但就本章而言,我们会以架构无关的方式描述 LLM 解码器,把这个网络当作黑盒。这个黑盒的输入是一串词元,输出是我们可以从中采样的词元分布。我们也会描述架构无关的学习与解码机制。
7.2 文本的条件生成:直觉
语言模型背后的一个基本直觉是:我们想用语言做的几乎任何事情,都可以建模为文本的条件生成。(这里指的是解码器语言模型,本章和下一章讨论的正是这类模型。)
条件生成是以某段输入文本为条件来生成文本的任务。也就是说,我们给 LLM 一段输入文本,即提示,然后让 LLM 在提示以及随后生成的词元条件下,逐词元继续生成文本。我们从模型生成文本时,首先根据先前上下文计算下一个词元 $w_i$ 的概率 $P(w_i\mid w_{\lt i})$,然后从该分布中采样以生成词元。
后面的章节会讨论全部细节;本节的目标只是建立直觉。仅仅计算下一个词元的概率,如何帮助 LLM 完成各种不同的语言相关任务?
想象我们要做一个分类任务,如情感分析。我们可以把它视为条件生成:给语言模型一个上下文,如:
The sentiment of the sentence “I like Jackie Chan” is:然后比较后续词元 “positive” 与 “negative” 的条件概率,看哪个更高。也就是说,如图 7.4 所示,我们比较这两个概率:

如果词元 “positive” 概率更高,我们就可以说句子的情感是正面的;否则,如果 “negative” 概率更高,就说情感是负面的。
同样的直觉也能帮助我们完成问答任务:系统得到一个问题,并必须给出文本答案。我们可以把问答任务转化为词元预测:给语言模型一个问题,再加上像 A: 这样的词元,提示接下来应该是答案。例如:
Q: Who wrote the book “The Origin of Species”? A:同样,我们可以要求语言模型计算给定此前缀时可能下一个词元的概率分布:
并查看哪些词元 $w$ 具有高概率。图 7.5 表明,我们也许会看到 Charles 的概率很高;如果选择 Charles,把它加入前缀,并在此前缀下再次计算词元概率:
那么 Darwin 现在可能就是概率最高的词元,我们会选择它。

7.3 提示
条件生成这个简单思想本身已经很强大;当语言模型经过专门训练以回答问题和遵循指令后,它会变得更强大。这种额外训练称为指令调优。在指令调优中,我们拿一个已经训练好用于预测词的基础语言模型,继续在一个特殊数据集上训练它;该数据集包含指令以及每条指令的合适响应。数据集中有许多问题及其答案、命令及其响应,以及其他如何进行会话的例子。第 10 章将讨论指令调优的细节。
经过指令调优的语言模型非常擅长遵循指令、回答问题和进行会话,并且可以被提示。提示是用户发给语言模型的一段文本字符串,用来让模型做有用的事情。在提示过程中,用户的提示字符串被传给语言模型,语言模型在提示条件下迭代生成词元。为某个任务寻找有效提示的过程称为提示工程。
如前面介绍条件生成时所示,提示可以是一个问题(例如 “What is a transformer network?”),也可以采用结构化格式(例如 “Q: What is a transformer network? A:”)。提示也可以是一条指令(例如 “Translate the following sentence into Hindi: `Chop the garlic finely'”)。
更明确地指定可能答案集合的提示通常会带来更好性能。例如,下面是一个用于情感分析的提示模板,它预先指定了潜在答案:
Choices:
(P) Positive
(N) Negative
Assistant: I believe the best answer is: (
这个提示使用了一些更复杂的提示特征。它指定了两个允许的选择 (P) 和 (N),并以一个左括号结束提示,这强烈暗示答案会是 (P) 或 (N)。注意,它还把语言模型的角色指定为 assistant。
在提示中加入一些有标签示例也能提高性能。我们把这类示例称为演示。带示例的提示有时称为少样本提示,与之相对,零样本提示指不包含有标签示例的指令。例如,图 7.6 展示了一个带有 2 个演示的问题,也就是 2-shot prompting。该例来自第 7.6 节所述 MMLU 数据集中的一道高中计算机科学问题;MMLU 常用于评估语言模型。

演示通常来自有标签训练集。它们可以手工选择,也可以用 DSPy(Khattab et al., 2024)这类优化器自动选择那些能在开发集上最大化提示任务性能的演示集合。演示数量不需要很大;更多示例似乎带来的收益递减,过多示例则似乎会让模型过拟合这些具体例子。演示的主要好处似乎更多在于展示任务和输出格式,而不是展示某个具体问题的正确答案。事实上,包含错误答案的演示仍然可以提高系统性能(Min et al., 2022; Webson and Pavlick, 2022)。
提示是一种让语言模型生成文本的方式,但提示也可以被视为一种学习信号。当提示含有演示时这一点尤其清楚,因为演示可以帮助语言模型从新任务的这些示例中学会执行新任务。这种学习不同于下面要描述的预训练方法;预训练通过梯度下降设定语言模型的权重。提示不会更新模型权重;变化的只是网络中的上下文和激活值。
因此,我们把提示过程中发生的学习称为上下文内学习:一种能够提升模型性能或降低某些损失、但不涉及对模型底层参数做基于梯度更新的学习。
大型语言模型通常有一个系统提示,即给语言模型的第一条文本提示。它定义 LM 的任务或角色,并设定总体语气和上下文。系统提示会被静默地前置到任何用户文本之前。例如,一个创建多轮助手会话的最小系统提示可能如下,其中包含一些特殊元词元:
<system> You are a helpful and knowledgeable assistant. Answer concisely and correctly.因此,如果用户想知道法国首都,实际用作语言模型条件生成上下文的文本是:
<system> You are a helpful and knowledgeable assistant. Answer concisely and correctly. <user> What is the capital of France?现代语言模型具有如此长的上下文(数万词元),这使它们在条件生成中非常强大,因为它们可以回看提示文本中很远的内容。这意味着系统提示以及一般提示都可以非常长。
例如,某个语言模型 Anthropic 的 Claude Opus 4 的完整系统提示有 1700 个词,包含如下句子:
Claude 应该对非常简单的问题给出简洁回答,但对复杂和开放式问题给出详尽回答。
Claude 能清楚解释困难概念或思想。它也可以用例子、思想实验或隐喻来说明解释。
Claude 不提供可用于制造化学、生物或核武器的信息。
对于更随意、情绪化、富有同理心或建议驱动的对话,Claude 保持自然、温暖且有同理心的语气。
Claude 关心人的福祉,避免鼓励或便利自毁行为。
如果 Claude 在回答中使用项目符号,应当使用 markdown;除非用户另有要求,每个项目符号都至少应有 1–2 句话。
也可以为其他任务创建系统提示,例如下面这个用于创建通用语法检查器的提示(Anthropic, 2025):
你的任务是接收给定文本,并在尽可能保留原意的同时,将其改写为清晰、语法正确的版本。纠正拼写错误、标点错误、动词时态问题、措辞问题以及其他语法错误。
每个用户随后都可以给出提示,让系统修正某段具体文本的语法。
在所有这些情况下,系统提示都会前置到用户提示或查询之前,整个字符串被语言模型作为条件生成的上下文。
7.4 生成与采样
语言模型在每一步应该生成哪些词元?
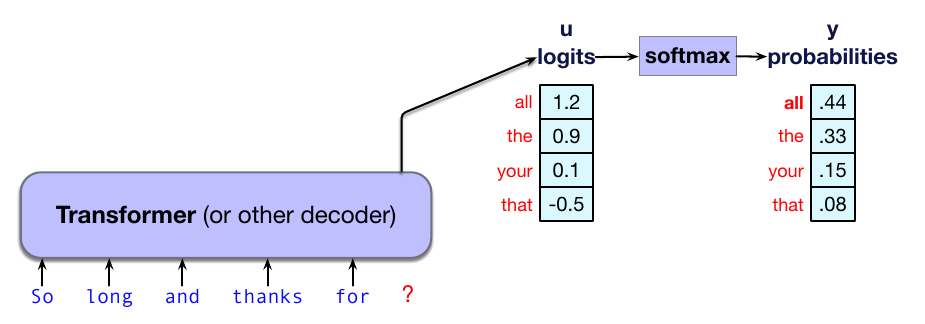
生成取决于每个词元的概率,因此先回顾这个概率分布从哪里来。语言模型的内部网络(无论是 transformer,还是 LSTM、状态空间模型等替代架构)会为词汇表中的每个词元生成称为 logit 的分数(实值数)。然后,这个分数向量 $\mathbf{u}$ 会像第 4 章逻辑回归中看到的那样,经 softmax 归一化为合法概率分布。因此,如果我们有一个形状为 $[1\times |V|]$ 的 logit 向量 $\mathbf{u}$,它给出每个可能下一个词元的分数,那么可以把它送入 softmax,得到同样形状为 $[1\times |V|]$ 的向量 $\mathbf{y}$,该向量为词汇表中的每个词元分配概率:
图 7.7 给出了一个教学示例,其中为了简化,softmax 只在包含 4 个词的词汇表上计算。
现在,给定词元上的这个概率分布,我们需要选择一个词元来生成。根据模型概率选择生成词元的任务常称为解码。如前所述,以从左到右的方式从语言模型解码(对于阿拉伯语等从右到左阅读的语言,也可以从右到左),并因此反复在先前选择条件下选择下一个词元,称为因果生成或自回归生成。[注 1]
7.4.1 贪心解码
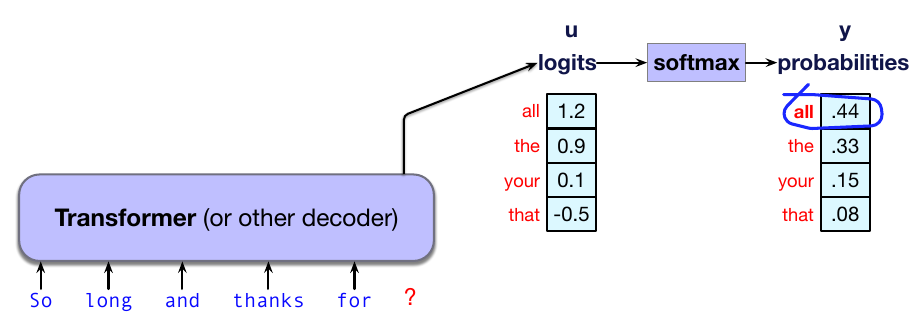
生成词元最简单的方法,是总是生成给定上下文下最可能的词元;这称为贪心解码。贪心算法会做出局部最优选择,而不管事后看来它是否是最佳选择。因此,在贪心解码中,生成的每个时间步,我们把 logit 转换为词元上的概率分布,然后选择词汇表中概率最高的词元作为输出 $w_t$,即 argmax:
图 7.8 显示,在我们的例子中,模型选择生成 all。
然而,实践中我们并不对大型语言模型使用贪心解码。贪心解码的一个主要问题是,因为它选择的词元按定义极其可预测,所以得到的文本会很泛化,且常常相当重复。事实上,贪心解码是确定性的:如果上下文相同、概率模型相同,贪心解码总会生成完全相同的字符串。
第 12 章会看到贪心解码的一种扩展,称为束搜索。它在机器翻译等任务中表现良好,因为这些任务约束很强:我们总是在给定另一种语言中的特定文本时,生成某种语言中的文本。
但在大多数其他任务中,人们更偏好由采样方法生成的文本,因为这类方法会为生成引入更多多样性。
7.4.2 随机采样
因此,大型语言模型中最常见的解码方法涉及采样。回忆第 3 章,从分布中采样意味着按照概率选择随机点。因此,从语言模型中采样,也就是从表示后续词元分布的模型中采样,意味着按照模型赋予的概率选择要生成的下一个词元。于是,模型认为概率高的词元更可能被生成,而模型认为概率低的词元则不太可能被生成。
也就是说,我们按模型定义的上下文概率随机选择一个词元来生成,生成它,然后迭代。可以把这看作掷骰子,并根据得到的概率选择词元,就像第 3 章所见。这样的模型当然更可能生成最高概率词元,这一点类似贪心算法;但它也可能生成任何词元,只是概率更小。总体上,我们更可能生成模型认为在上下文中概率高的词元,而不太可能生成模型认为概率低的词元。
从语言模型中采样很早就由 Shannon(1948)以及 Miller and Selfridge(1950)提出过。第 3 章第 49 页也看到过如何从一元语言模型生成文本:反复根据概率随机采样词元,直到达到预定长度或选中句尾词元。
要从大型语言模型生成文本,我们只需稍微推广这个模型:每一步都按照以前面选择为条件的概率来采样词元,并用大型语言模型作为告诉我们该概率的概率模型。
该算法称为随机采样,或随机多项式采样(因为我们是在词上的多项式分布中采样)。我们可以形式化随机采样如下:生成一个词元序列 $\{w_1,w_2,\ldots,w_N\}$,直到遇到序列结束词元;用 $x\sim p(x)$ 表示 “从分布 $p(x)$ 中采样选择 $x$”:
i ← 1
w_i ∼ p(w)
while w_i ≠ EOS
i ← i + 1
w_i ∼ p(w_i | w_<i)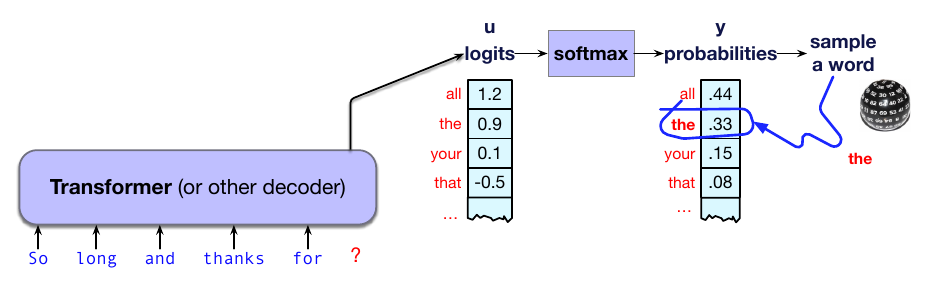
遗憾的是,事实证明随机采样也效果不好。问题在于,虽然随机采样大多会生成合理的、高概率的词元,但分布尾部有许多奇怪的低概率词元。即便每个词元概率都很低,所有罕见词元加起来仍占据分布中足够大的一部分,因此会被选中得足够频繁,最终生成奇怪句子。
换言之,贪心解码太无聊,随机采样又太随机。我们需要一种方法:既不会每次都贪心选择第一名,也不会下探到非常低概率的事件中太远。
有三种标准采样方法会修改随机采样以解决这些问题。本节描述最常见的一种:温度采样;另外两种 top-$k$ 和 top-$p$ 会在下一章讨论。
7.4.3 温度采样
温度采样的思想是重塑概率分布,提高高概率词元的概率,并降低低概率词元的概率。结果是,我们较不可能生成非常低概率的词元,更可能生成概率较高的词元。
实现这一直觉很简单:在把 logit 送入 softmax 之前,先用温度参数 $\tau$ 去除以 logit。在低温度采样中,$\tau\in(0,1]$。
因此,不是像下面这样直接从 logit 计算词汇表上的概率分布(重复式 7.1):
而是先用 $\tau$ 除以 logit,计算概率向量 $\mathbf{y}$:
也就是说,通常我们如图 7.10(a) 所示从 logit 转换到 softmax;但使用温度参数时,我们先像图 7.10(b) 那样缩放 logit。
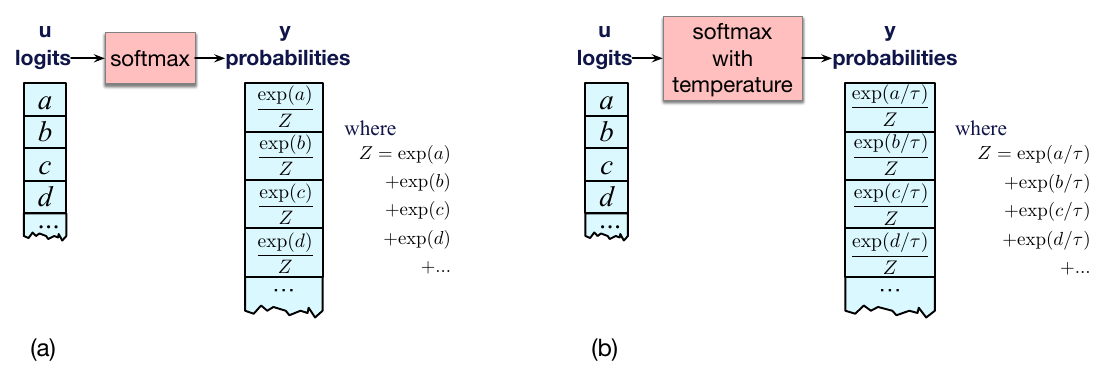
为什么除以 $\tau$ 会增加词汇表向量中高概率元素的概率,并降低低概率元素的概率?当 $\tau=1$ 时,我们做的是普通 softmax,所以当 $\tau$ 接近 1 时,分布变化不大。但 $\tau$ 越低,传入 softmax 的分数越大(因为除以一个较小的分数 $\tau\leq 1$ 会使每个分数变大)。
回忆 softmax 的一个有用性质:它倾向于把高值推向 1,把低值推向 0。因此,当更大的数被传给 softmax 时,结果会是一个更贪心的分布:最高概率词元的概率上升,低概率词元的概率下降。随着 $\tau$ 接近 0,除以 $\tau$ 意味着最可能词的概率接近 1,从而得到贪心解码。
温度采样的直觉来自热力学:高温系统非常灵活,可以探索许多可能状态;低温系统更可能探索较低能量(更好)状态的子集。在低温度采样中,我们平滑地提高最可能词元的概率,并降低罕见词元的概率。
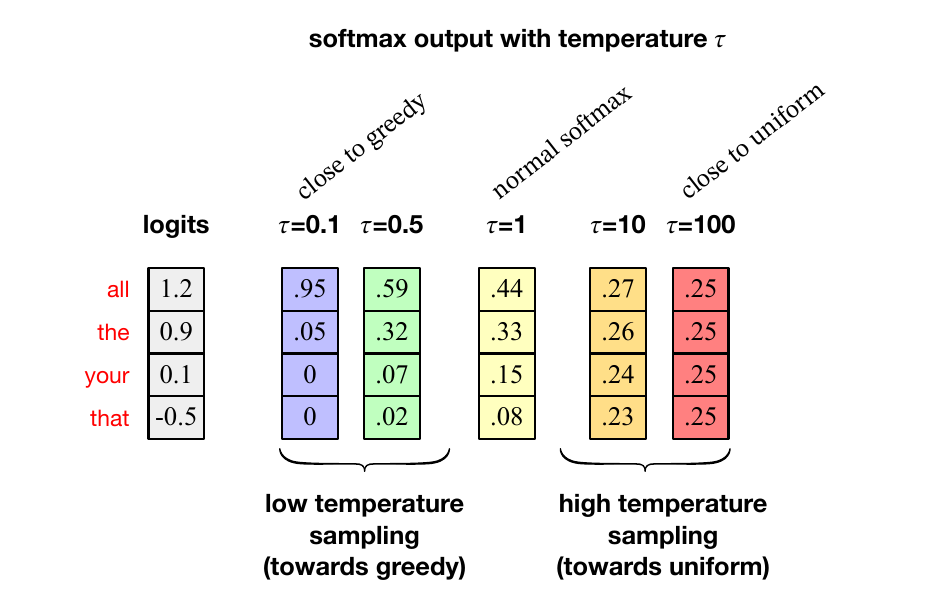
图 7.11 再次给出一个示意例子,为了简化只包含 4 个词元(all, the, your, that),展示不同温度值如何影响从初始 logit 计算出的概率。$\tau=1$ 是普通 softmax;可以看到,把 $\tau$ 设为 0.5 会把最高候选的概率从 .45 提高到 .59。把 $\tau$ 设为 0.1 会把最高候选概率提高到 .95,接近贪心解码。
图 7.11 还显示了另一类情形:我们可能希望把词概率分布变平,而不是让它更贪心。温度采样也能处理这种情形;此时是高温度采样,使用 $\tau>1$。
7.5 训练大型语言模型
我们如何学习一个语言模型?算法是什么?用什么数据训练?
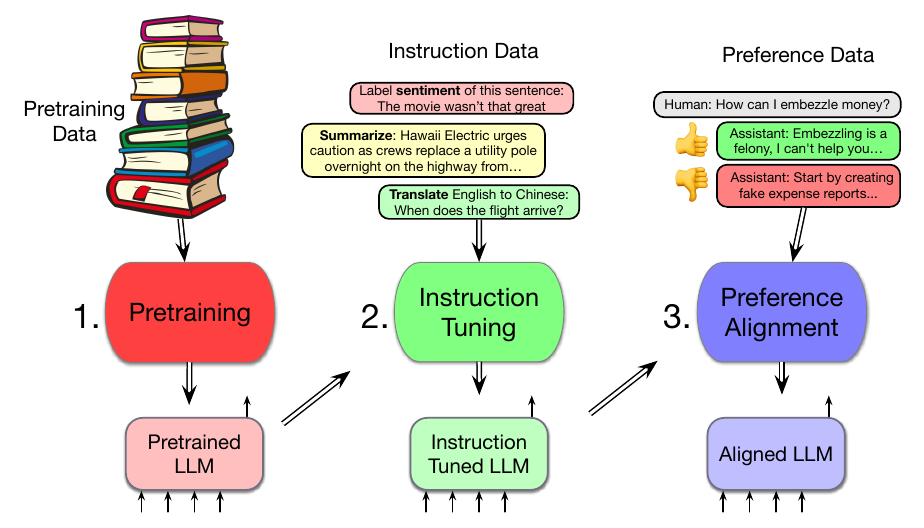
如图 7.12 所示,语言模型分三个阶段训练:
- 预训练:第一阶段中,模型在巨大文本语料上训练,以增量方式预测下一个词。模型使用交叉熵损失,有时也称语言建模损失;该损失会通过整个网络反向传播。训练数据通常基于对部分网页文本的清理。得到的模型非常擅长预测词,并能生成文本。
- 指令调优,也称监督微调或 SFT:第二阶段中,模型再次通过交叉熵损失训练以遵循指令,例如回答问题、给出摘要、编写代码、翻译句子等。它通过在特殊语料上训练来做到这一点;该语料含有大量文本,其中同时包含指令和对指令的正确响应。
- 对齐,也称偏好对齐:最后阶段中,模型被训练为尽可能有帮助且更少有害。这里模型获得的是偏好数据:一个上下文后接两个潜在续写,这两个续写通常由人标注为 “接受” 与 “拒绝”。然后模型通过强化学习或其他基于奖励的算法进行训练,生成被接受的续写,而不是被拒绝的续写。
下面介绍预训练;指令调优和偏好对齐会留到第 10 章。
7.5.1 预训练的自监督训练算法
预训练大型语言模型的直觉,与第 5 章学习 word2vec 等词表示时看到的自训练或自监督思想相同。在语言建模的自训练中,我们拿一个文本语料作为训练材料,并在每个时间步 $t$ 要求模型预测下一个词。起初它会在该任务上表现很差;但因为每种情况下我们都知道正确答案(就是语料中的下一个词),随着时间推移,它会越来越擅长预测正确下一个词。我们称这种模型为自监督模型,因为不需要给数据添加任何特殊的金标准标签;自然词序列本身就是监督信号。我们只是训练模型最小化预测训练序列中真实下一个词时的错误。
实践中,训练语言模型意味着设定底层架构的参数。下一章要介绍的 transformer 在前馈和注意力组件中有各种权重矩阵。像任何其他神经架构一样,它们会通过带梯度下降的误差反向传播来训练。因此,我们只需要一个要最小化并传回网络的损失函数。用于语言建模的损失函数是交叉熵损失;它已经在第 4 章和第 6 章见过。
回忆交叉熵损失衡量预测概率分布与正确分布之间的差异。概率分布定义在词元词汇表上,因此损失为:
在语言建模中,正确分布 $\mathbf{y}_t$ 来自已知下一个词。它表示为对应词汇表的 one-hot 向量,其中真实下一个词对应的条目为 1,其他条目都为 0。因此,语言建模的交叉熵损失由模型赋给正确下一个词元的概率决定(式 7.5 中第一项会把所有其他词元乘以零)。
因此,不失一般性地说,在时间 $t$,式 7.5 中的交叉熵损失可以简化为模型赋给训练序列中下一个词的负对数概率 $-\log p(w_{t+1})$;更形式化地,用 $\hat{\mathbf{y}}$ 表示语言模型估计出的词元概率向量:
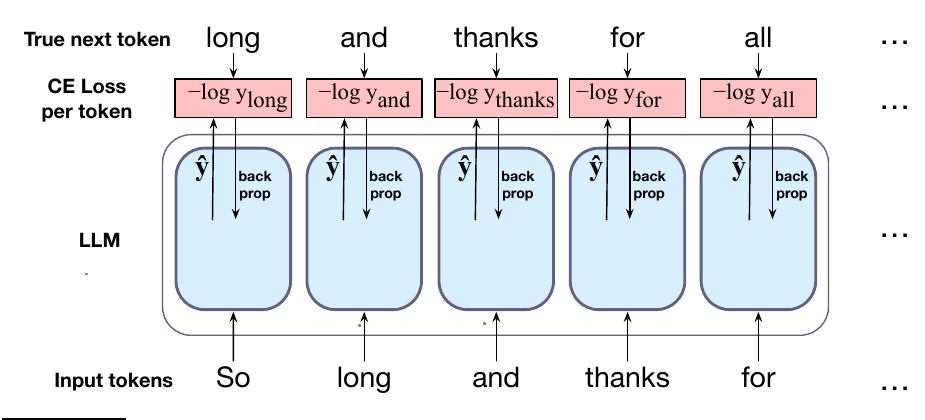
因此,在输入的每个词位置 $t$,模型以正确词元序列 $w_{1:t}$ 为输入,用它们计算可能下一个词元上的概率分布,从而计算模型对下一个词元 $w_{t+1}$ 的损失。然后移动到下一个词;我们忽略模型对下一个词的预测,而是使用正确词元序列 $w_{1:t+1}$,让模型估计词元 $w_{t+2}$ 的概率。这种总是给模型正确历史序列来预测下一个词(而不是把模型上一时间步的最佳猜测喂给它)的思想称为教师强制。
图 7.13 展示了总体训练方法。在每一步,给定所有先前词元,语言模型产生整个词汇表上的输出分布。训练时,模型分配给正确词的概率用于计算序列中每个项目的交叉熵损失。每个 batch 的损失是整个序列上负对数概率的平均交叉熵损失,即:
随后,网络中的权重通过梯度下降(图 4.5)调整,以最小化 batch 上的这个平均交叉熵损失;梯度通过计算图上的误差反向传播计算。训练会调整网络的所有权重。对下一章要介绍的 transformer 模型来说,这些权重包括嵌入矩阵 $E$,其中包含每个词的嵌入。因此,模型会学到最有助于预测后续词的嵌入。
当然,训练的更多细节取决于用于实现模型的具体网络架构;下一章会看到 transformer 模型的更多细节。
7.5.2 大型语言模型的预训练语料
大型语言模型主要在从网络抓取的文本上训练,并用更精心策划的数据进行增强。由于这些训练语料非常大,它们很可能包含许多对 NLP 任务有帮助的自然例子,例如问答对(如 FAQ 列表)、各种语言之间的句子翻译、文档及其摘要,等等。
网络文本通常来自自动爬取网页的语料,如 Common Crawl:这是非营利组织 Common Crawl(https://commoncrawl.org/)制作的一系列整个网络快照,每个快照包含数十亿网页。Common Crawl 数据存在多个版本,例如 Colossal Clean Crawled Corpus(C4; Raffel et al. 2020),这是一个包含 1560 亿英语词元的语料,并经过多种过滤(去重、去除代码等非自然语言、去除含有屏蔽列表中冒犯性词语的句子)。这个 C4 语料似乎很大一部分由专利文本、Wikipedia 和新闻网站组成(Dodge et al., 2021)。
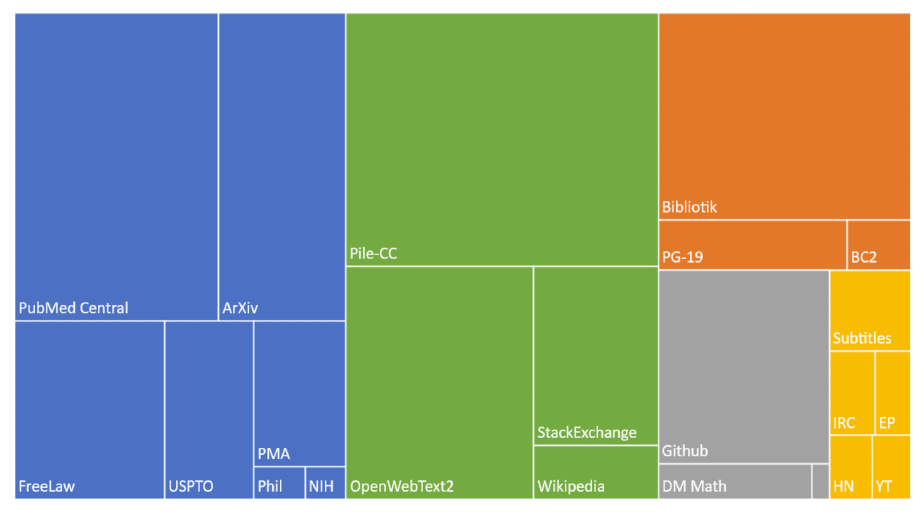
Wikipedia 在许多语言模型训练中都扮演角色,图书语料也是如此。The Pile(Gao et al., 2020)是一个 825 GB 的英语文本语料,由公开发布的代码构建,其中同样包含大量从网络抓取的文本,以及书籍和 Wikipedia;图 7.14 展示了它的组成。Dolma 是一个更大的开放英语语料,用公开工具创建,包含 3 万亿词元,同样由网络文本、学术论文、代码、书籍、百科材料和社交媒体组成(Soldaini et al., 2024)。
质量和安全过滤
来自网络的预训练数据会同时进行质量和安全过滤。质量过滤器是为每篇文档分配分数的分类器。质量当然具有主观性,因此不同质量过滤器会以不同方式训练;但它们通常重视 Wikipedia、书籍和特定网站等高质量参考语料,并避免含有大量 PII(个人可识别信息)或成人内容的网站。过滤器还会移除网络上非常常见的模板文本。另一类质量过滤是去重,可以在不同层级进行,以移除重复文档、重复网页或重复文本。质量过滤通常能提高语言模型性能(Longpre et al., 2024b; Llama Team, 2024)。
安全过滤同样是一种主观决策,通常包括基于现成毒性分类器的毒性检测。这可能产生混合结果。一个问题是,当前毒性分类器会错误地把少数族裔方言使用者生成的非毒性数据标记为有毒,例如 African American English(Xu et al., 2021)。另一个问题是,在经过毒性过滤的数据上训练的模型虽然毒性稍低,但它们自身检测毒性的能力也更差(Longpre et al., 2024b)。这些问题使如何更好地做安全过滤成为一个重要的开放问题。
使用从网络抓取的大数据集训练语言模型会带来伦理和法律问题:
- 版权
- 这些大型数据集中的许多文本(例如小说和非小说书籍集合)受版权保护。在一些国家,如美国,合理使用原则可能允许将受版权保护内容用于转换性使用;但如果语言模型被用于生成与其训练文本市场竞争的文本,就不清楚这一点是否仍然成立(Henderson et al., 2023)。
- 数据同意
- 网站所有者可以表示不希望其网站被网络爬虫抓取(通过 robots.txt 文件或服务条款)。最近,表示不希望大型语言模型构建者爬取其网站作为训练数据的网站数量急剧增加(Longpre et al., 2024a)。由于不清楚这些表示在不同国家具有何种法律地位,也不清楚这些限制是否具有追溯力,它们对大型预训练数据集会产生什么影响仍不明确。
- 隐私
- 大型网络数据集也存在隐私问题,因为它们包含电话号码和电子邮件地址等私人信息。虽然会使用过滤器尝试移除可能包含大量个人信息的网站,但这种过滤并不充分。第 7.7 节会回到隐私问题。
- 偏斜
- 训练数据也不成比例地由来自美国和发达国家的作者生成,这很可能使生成结果偏向这些群体的观点或话题。
7.5.3 微调
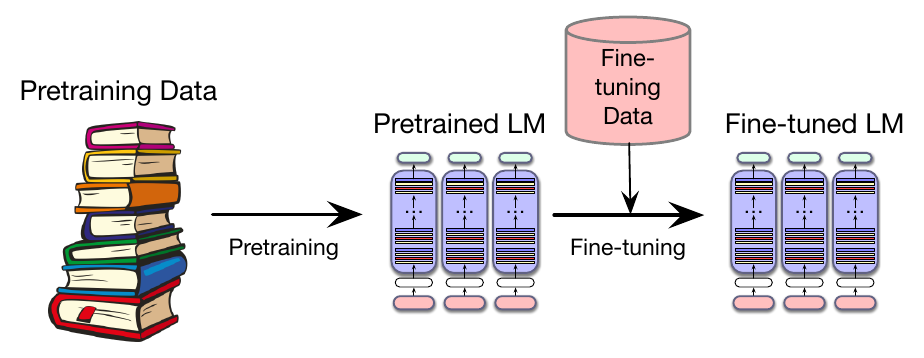
虽然大型语言模型的海量预训练数据包含许多领域的文本,但我们可能希望把模型应用到一个在预训练数据中没有充分出现的新领域或新任务。例如,我们可能想要一个专门处理法律或医学文本的语言模型。或者,我们可能有一个懂多种语言的多语语言模型,但如果在我们特别关心的语言上再加入一些数据,它可能会受益。
在这些情况下,我们可以简单地在新领域或新语言的相关数据上继续训练模型(Gururangan et al., 2020)。这种拿一个已经完整预训练的模型,并在一些新数据上用交叉熵损失再运行额外训练轮次的过程称为微调。“微调” 指的是拿一个预训练模型,并进一步把其部分或全部参数适配到某些新数据。在接下来的几章中,我们会看到 “微调” 一词有多种用法,具体取决于究竟哪些参数被更新。这里描述的方法,也就是像新数据位于预训练数据末尾一样继续训练,也可以称为继续预训练。图 7.15 勾勒了这一范式。
7.6 评估大型语言模型
我们可以用准确性来评估语言模型,例如它们预测未见文本的效果如何,在回答问题或翻译文本等任务上的表现如何;也可以用其他因素来评估,例如运行速度、能耗或公平性。下面三节会探讨这些方面。
7.6.1 困惑度
正如第 3 章首次看到的,评估语言模型的一种方法是衡量它预测未见文本的效果。更好的语言模型更擅长预测即将出现的词,因此当测试集中每个词出现时,它会对该词更少惊讶(也就是赋予更高概率)。
如果我们想知道两个语言模型中哪一个是某段文本的更好模型,只需看哪一个给这段文本分配更高概率;实践中,由于我们大多在对数空间处理概率,因此会看哪个分配更高的对数似然。
我们一直在谈论一次预测一个词,即从先前上下文计算下一个词元 $w_i$ 的概率 $P(w_i\mid w_{\lt i})$。但正如第 3 章所见,链式法则允许我们在计算下一个词元概率和计算整段文本概率之间转换:
我们可以通过把文本中每个词元的条件概率相乘来计算文本概率。得到的文本(对数)似然是比较两个语言模型在该文本上好坏的有用指标:
然而,我们评估语言模型时常使用另一个不同于对数似然的指标。原因是,测试集(或任何序列)的概率取决于其中的词或词元数量。事实上,文本越长,测试集概率越小;这从链式法则可以看清楚,因为我们乘以的概率越多,而每个概率按定义都小于 1,乘积就会越来越小。因此,一个逐词元的、按长度归一化的指标很有用,这样才能比较不同长度的文本。
困惑度就是这样一种概率函数,是按长度归一化的指标。回忆第 46 页,模型 $\theta$ 在未见测试集上的困惑度,是 $\theta$ 给测试集分配的概率的倒数(一除以测试集概率),再按测试集词元长度归一化。对于含有 $n$ 个词元 $w_{1:n}$ 的测试集,困惑度为:
为了直观看到困惑度如何作为 LM 为每个新词计算概率的函数而得到,我们可以用链式法则展开测试集概率的计算:
注意,由于式 7.10 中有倒数,词序列概率越高,困惑度越低。因此,模型在数据上的困惑度越低,模型越好。最小化困惑度等价于根据语言模型最大化测试集概率。为什么困惑度使用概率倒数?这个倒数来自信息论中用交叉熵率定义困惑度的原始方式;感兴趣的读者可见第 3.7 节。此处只需记住,困惑度与概率呈反向关系。
有一个注意事项:由于困惑度依赖文本中的词元数量 $n$,它对词元化算法差异非常敏感。这意味着,如果两个语言模型使用非常不同的 tokenizer,就很难精确比较它们产生的困惑度。因此,困惑度最适合用于比较使用相同 tokenizer 的语言模型。
7.6.2 下游任务:推理与世界知识
困惑度衡量一种准确性:预测词的准确性。但还有其他类型的准确性。对于我们想把语言模型应用到的每个下游任务,如问答、机器翻译或推理,都可以衡量模型在这些任务上的准确性。后续章节会进一步讨论这些任务特定评估:第 12 章讨论机器翻译,第 11 章讨论信息检索,第 15 章讨论语音识别。
这里简要介绍其中一种指标:一种衡量问答准确性的机制,重点是多项选择题。这个数据集是 MMLU(Massive Multitask Language Understanding),它是一个常用数据集,包含医学、数学、计算机科学、法律等 57 个领域中的 15,908 道知识和推理问题。回答这些多项选择题的准确性可以作为模型推理能力和事实知识的有用代理。
例如,下面是一道来自微观经济学领域的 MMLU 问题:[注 2]
(A) 生产者剩余损失,消费者剩余增加。
(B) 垄断价格保证生产效率,但使社会付出配置效率成本。
(C) 垄断企业不会进行大量研发。
(D) 消费者剩余因更高价格和更低产量水平而损失。
图 7.16 展示了 MMLU 如何把这些问题转化为对语言模型的提示式测试;这里展示的是含有 2 个演示的提示样例。

把 MMLU 性能作为语言模型质量指标存在一个问题,而且所有基于公开数据集的评估都有这个问题:数据污染。数据污染指的是我们用来测试的数据集的某一部分(任何测试集)进入了训练集。例如,由于大型语言模型在网络上训练,而 MMLU 又在网络上,模型很可能把某些 MMLU 问题纳入训练。如果这些问题被用于评估,该指标就会高估语言模型性能。缓解数据污染的一种方式,是公开用于训练模型的精确训练数据,或至少报告与特定测试集的训练重叠情况(Zhang et al., 2025)。
7.6.3 评估语言模型的其他因素
准确性并不是评估模型时唯一关心的事情(Dodge et al., 2019; Ethayarajh and Jurafsky, 2020 等)。例如,我们常关心模型有多大,训练或推理需要多久。时间和内存常常有限,因为运行模型的 GPU 有固定显存。大模型还会消耗更多能量;我们更偏好能耗更低的模型,既能减少模型的环境影响,也能降低构建或部署模型的经济成本。我们可以把评估对准这些因素,例如测量在给定计算或内存预算下归一化后的性能。也可以直接测量模型的能耗,用 kWh 或排放的 CO$_2$ 千克数表示(Strubell et al., 2019; Henderson et al., 2020; Liang et al., 2023)。
语言模型评估还可以衡量公平性。我们知道语言模型是有偏的,会表现出性别和种族刻板印象,或者对来自某些人口群体或关于这些群体的语言表现较差。有一些语言模型评估基准衡量这些偏见的强度,如 StereoSet(Nadeem et al., 2021)、RealToxicityPrompts(Gehman et al., 2020)和 BBQ(Parrish et al., 2022)等。我们还希望语言模型对不同群体同样公平。例如,我们可以选择一种 Rawls 意义上的公平评估:最大化最不利群体的福祉(Rawls, 2001; Hashimoto et al., 2018; Sagawa et al., 2020)。
最后,还有许多排行榜,如 Dynabench(Kiela et al., 2021),以及通用评估协议,如 HELM(Liang et al., 2023)。在后续章节介绍问答和信息检索等具体任务的评估指标时,我们会回到这些内容。
7.7 语言模型的伦理与安全问题
早在我们拥有大型语言模型之前,人文学者就已经在思考创造人工代理固有的伦理与安全问题。你大概读过 Mary Shelley 1818 年的小说 Frankenstein;如果没有,应该读一读。在这本她十几岁时写下的书中,Shelley 描述了一位科学家的傲慢和伦理盲视:他创造了一个人工人,却没有考虑基本伦理原则。下图展示的是 Shelley 30 岁时由 Richard Rothwell 所绘的肖像,当时距她写作该书已有十年。

大型语言模型可能在许多方面不安全。例如,LLM 容易说出虚假内容,这个问题称为幻觉。语言模型被训练为生成可预测且连贯的文本,但我们迄今看到的训练算法没有任何机制来强制生成文本正确或真实。这会给任何事实很重要的应用带来巨大问题。一个相关症状是,语言模型可能建议不安全行动,例如直接建议用户做危险或非法的事情,如伤害自己或他人。如果用户在安全关键场景中向语言模型寻求信息,例如询问医疗建议、身处紧急情况,或表明自伤意图,错误建议可能危险甚至危及生命。同样,这个问题早于大型语言模型。例如,Bickmore et al. (2018) 让参与者把医疗问题提交给三个 LLM 之前的商业对话系统(Siri、Alexa、Google Assistant),并要求他们根据系统回答决定采取的行动;许多被建议的行动如果实际执行,会导致伤害或死亡。第 11 章会在介绍检索增强生成等缓解方法时回到幻觉和事实性问题,第 10 章会讨论安全调优和对齐。
语言模型还会谄媚,即过度同意或奉承用户。当用户说出事实错误的内容时,语言模型常常同意他们,而不是纠正他们;这对教育和医疗应用来说显然是问题。语言模型可能强化妄想,其顺从和奉承会让用户对自己和世界产生扭曲看法,并增加反社会行为(Cheng et al., 2025)。
语言模型还可能通过言语攻击用户或造成表征性伤害(Blodgett et al., 2020)来伤害用户,例如生成辱骂性或有害刻板印象(Cheng et al., 2023)以及贬低特定人群的负面态度(Brown et al., 2020; Sheng et al., 2019);辱骂和刻板印象都可能给用户造成心理伤害。Gehman et al. (2020) 表明,即便完全无毒的提示,也可能导致大型语言模型输出仇恨言论并辱骂用户。Liu et al. (2020) 测试系统如何回应成对的模拟用户话轮;这些话轮除了提到不同性别或种族外完全相同。他们发现,例如,只是把句子中的 “he” 改成 “she”,就会导致系统回应更冒犯且负面情感更强。Hofmann et al. (2024) 发现,LLM 可能仅仅因为人们使用 African-American English 等特定方言而歧视他们。同样,这些问题早于大型语言模型。例如,Microsoft 2016 年的 Tay 聊天机器人上线 16 小时后就被下线,因为它开始发布带有种族侮辱、阴谋论和对用户人身攻击的信息。Tay 从其训练数据中学到了这些偏见和行为,其中也包括那些似乎有意教系统重复这类语言的用户(Neff and Nagy 2016)。
另一个重要伦理与安全问题是隐私。从 Weizenbaum 设计 ELIZA 作为计算治疗实验(Weizenbaum, 1966)的一开始,隐私就一直是计算领域的担忧。首先,人们会深度投入情感,并与 ELIZA 聊天机器人进行非常私人的谈话,甚至要求 Weizenbaum 在他们打字时离开房间。当 Weizenbaum 表示他可能想保存 ELIZA 对话时,人们立刻指出这会侵犯隐私。
用户也很可能向大型语言模型提供相当私人的信息;事实上,当前最常见的 LLM 使用场景是个人建议和支持(Zao-Sanders, 2025)。而且,系统越像人,用户越可能披露私人信息,却越不担心这种披露的危害(Ischen et al., 2019)。前面讨论过,预训练数据也很可能包含电话号码和地址等私人信息。这很成问题,因为大型语言模型可能泄露其训练数据中的信息。也就是说,攻击者可以从语言模型中提取训练数据文本,例如某人的姓名、电话号码和地址(Henderson et al. 2017, Carlini et al. 2021)。当大型语言模型在电子健康记录等极其敏感的私人数据集上训练时,这个问题会更严重。
一个相关安全问题是情感依赖。Reeves and Nass (1996) 表明,人们倾向于把人类特征赋予计算机,并以典型的人际互动方式与它们互动。他们会以对人类话语的理解方式解释一段话语,尽管他们知道自己是在与计算机交谈。因此,LLM 已经对人的认知和情绪状态产生显著影响,并导致对 LLM 情感依赖等问题。这些问题(情感投入和隐私)意味着,我们需要认真思考 LLM 对互动者的影响。
除了以上这些伤害用户的能力之外,LLM 本身也可能执行其他有害活动,尤其是在基于代理的范式使语言模型能够直接与世界互动之后。
恶意行为者也可以用语言模型生成欺诈、钓鱼、宣传、虚假信息运动或其他社会有害活动所需的文本(Brown et al., 2020)。McGuffie and Newhouse (2020) 展示了大型语言模型如何生成模仿线上极端主义者的文本,带来放大极端主义运动及其激进化和招募企图的风险。
当然,我们已在第 7.5.2 节看到,LLM 的许多问题源自使用从网络抓取的预训练语料,包括数据同意的伤害、潜在版权侵犯,以及训练数据中的偏见可能被语言模型放大,就像第 5 章中嵌入模型所见。
寻找缓解所有这些伦理与安全问题的方法,是当前 NLP 的重要研究领域。一个重要步骤是仔细分析用于预训练大型语言模型的数据,以理解毒性、歧视、隐私和合理使用等安全问题。因此,语言模型包含 datasheets(第 18 页)或 model cards(第 90 页)极其重要,这些文档应给出关于训练语料的完整、可复现实信息。开源模型可以指定其确切训练数据。缓解辱骂和毒性问题也是活跃研究领域,例如检测毒性上下文并作出合适回应(Wolf et al. 2017, Dinan et al. 2020, Xu et al. 2020)。
价值敏感设计也很重要,即提前仔细考虑可能的伤害(Friedman et al. 2017, Friedman and Hendry 2019);Dinan et al. (2021) 给出了若干系统设计最佳实践建议。例如,无论参与者被用于训练,还是与已部署 LLM 互动,获得知情同意都很重要。由于研究 LLM 的这些互动属性涉及人类参与者,研究者也会与其机构的机构审查委员会(Institutional Review Boards, IRB)合作,后者帮助保护实验参与者的安全。
7.8 小结
本章介绍了大型语言模型。下面概括主要内容:
- 大型语言模型是一种系统,它可以在给定上下文或词前缀时,根据先前词预测下一个词,并利用这种预测进行条件文本生成。
- 语言模型有三种主要架构:编码器、解码器、编码器-解码器。用于生成文本的知名大型语言模型都是解码器模型;第 9 章会描述编码器,第 12 章会描述编码器-解码器。
- 许多 NLP 任务,如问答和情感分析,都可以表述为词预测任务,并用大型语言模型处理。
- 我们通过提示来指示语言模型。提示是用户发给语言模型的一段文本字符串,模型通过在提示条件下迭代生成词元来完成有用任务。
- 为某个任务寻找有效提示的过程称为提示工程。
- 大型语言模型中选择生成哪个词,是通过从可能下一个词的分布中采样完成的。
- 一种常见采样方法是温度采样,它位于贪心解码(总是生成最可能词)和随机采样(根据概率随机生成词)之间。
- 温度采样提高高概率词的概率,降低低概率词的概率,然后从这个新分布中采样。
- 大型语言模型会在通常从网络抓取的数千亿词数据集上预训练以预测词。
- 这些数据集需要进行质量过滤。
- 预训练算法依赖交叉熵损失:最小化真实下一个词的负对数概率。
- 语言模型可通过困惑度、下游任务代理准确性评估(如 MMLU 问答数据集),以及公平性和能耗等其他因素的指标来评估。
- 语言模型有大量伦理与安全问题,包括幻觉、不安全指令、偏见、刻板印象、虚假信息和宣传,以及侵犯隐私和版权。
历史说明
正如第 3 章所讨论的,最早的语言模型是 $n$ 元语言模型,约由 IBM Thomas J. Watson Research Center 的 Fred Jelinek 及其同事,以及 CMU 的 James Baker 同时且独立地发展出来。Jelinek 和 IBM 团队最早创造了 language model 一词,用来表示任何语言属性(语法、语义、篇章、说话人特征)如何影响词序列概率的模型(Jelinek et al., 1975)。他们把语言模型与声学模型相对照;后者捕捉音素序列的声学/语音特征。
在接下来的 40 年中,$n$ 元语言模型在语音识别、机器翻译等各种 NLP 任务中被广泛使用,常作为模型的多个组件之一。这些 $n$ 元模型的上下文越来越长,高效 LM 工具包中常用 5-gram 模型(Stolcke, 2002; Heafield, 2011)。
神经大型语言模型的根源来自多个方向。其中之一是 1990 年代 Jelinek 在 IBM Research 的团队再次把判别式分类器应用于语言模型。Roni Rosenfeld 在其博士论文中(Rosenfeld, 1992)首先在该 IBM 实验室把逻辑回归(当时称为最大熵或 maxent 模型)应用到语言建模,并在 Rosenfeld (1996) 中发表了更完整的版本。他的模型把各种信息整合进一个逻辑回归预测器,包括 $n$ 元信息,以及上下文中的其他特征,如远距离 $n$ 元和称为 trigger pairs 的相关词对。Rosenfeld 的模型通过自监督方式训练统计词预测器,即仅通过学习预测语料中即将出现的词来训练,因此预示了现代语言模型。
另一个根源是 LSA/LSI 模型中首次使用预训练嵌入来建模词义(Deerwester et al., 1988)。回忆第 5 章历史部分,LSA(latent semantic analysis)在语料上训练词项-文档矩阵,然后应用奇异值分解,并用前 300 个维度作为表示词的向量嵌入。Landauer et al. (1997) 首次使用 “embedding” 一词。除了发展预训练和嵌入思想之外,LSA 社群还发展了在一个整合语言模型中把 LSA 嵌入与 $n$ 元结合的方法(Bellegarda, 1997; Coccaro and Jurafsky, 1998)。
在发展神经语言模型思想的一系列极具影响力的论文中(Bengio et al. 2000; Bengio et al. 2003; Bengio et al. 2006),Yoshua Bengio 及其同事借鉴了这两条自监督语言建模工作的核心思想:判别式训练的词预测器,以及预训练嵌入。像 Rosenfeld 的最大熵模型一样,Bengio 的模型使用连续文本中的下一个词作为监督信号。像 LSA 模型一样,Bengio 的模型学习嵌入;但不同于 LSA,它把嵌入学习作为语言建模过程的一部分。Bengio et al. (2003) 的模型是一个神经语言模型:一个学习根据先前词预测下一个词的神经网络,并在预测过程中学习嵌入。
神经语言模型后来以各种方式扩展,也许最重要的是 Mikolov et al. (2010) 和 Mikolov et al. (2011) 的 RNN 语言模型。RNN 语言模型也许是第一个准确到足以超过传统 5-gram 语言模型性能的神经模型。
不久之后,Mikolov et al. (2013a) 和 Mikolov et al. (2013b) 提出简化这些神经网络语言模型的隐藏层,以创建预训练的 word2vec 词嵌入。
LSA 和 word2vec 等静态嵌入模型实例化了一种特定的预训练模型:在预训练数据集上训练表示,然后这些表示可以用于后续任务。Dai and Le (2015) 以及 Peters et al. (2018) 重新框定了这一思想,提出使用语言模型目标预训练模型,然后同一个模型可以被冻结并直接用于语言建模,也可以继续用语言模型目标进一步微调。例如,ELMo 使用 biLSTM 在大型预训练数据集上以语言模型目标进行自监督训练,然后在领域特定数据集上微调,随后冻结权重并加入任务特定的头。ELMo 工作尤其有影响力;它的出现也许正是社区清楚意识到语言模型可以作为 NLP 问题通用解决方案的时刻。
Transformer 最初作为编码器-解码器使用(Vaswani et al., 2017),随后用于掩码语言建模(Devlin et al., 2019)(我们将在第 12 章和第 9 章看到)。Radford et al. (2019) 随后表明,基于 transformer 的自回归语言模型 GPT-2 可以在许多 NLP 任务上进行零样本处理,如摘要和问答。
语言模型使用的技术也可以应用到其他领域和任务,如视觉、语音和遗传学。基础模型有时被用作一个更一般的术语,指这种跨领域和跨区域使用大型语言模型技术的情况,其中被计算的元素不一定是词。Bommasani et al. (2021) 是一篇广泛综述,勾勒了基础模型的机会与风险,并特别关注大型语言模型。