Larvatus prodeo [我戴着面具前行]
Descartes
9 掩码语言模型
在前两章中,我们介绍了 transformer,并看到如何把 transformer 语言模型预训练为因果语言模型或从左到右的语言模型。本章将介绍预训练语言模型的第二种范式:双向 transformer 编码器,以及其中使用最广泛的版本 BERT 模型(Devlin et al., 2019)。这个模型通过掩码语言建模训练:我们不再预测下一个词,而是把中间的某个词遮住,让模型根据两侧的词来猜测该词。因此,这种方法允许模型同时看到右侧和左侧上下文。
上一章还介绍了微调。本章将描述一种新的微调方式:取这些预训练模型学到的 transformer 网络,在网络顶层之后加入一个神经网络分类器,并用额外的带标签数据训练它,使它能够执行下游任务,例如命名实体标注或自然语言推理。直觉仍然是:预训练阶段学到的语言模型会实例化丰富的词义表示,从而使模型更容易学习(也就是 “被微调到”)某个下游语言理解任务的需求。预训练--微调范式的这个方面,是机器学习中所谓迁移学习的一个实例:从某个任务或领域获取知识,再把它应用(迁移)到一个新任务上。
本章引入的第二个思想是上下文嵌入:也就是上下文中的词表示。第 5 章中的 word2vec 或 GloVe 等方法为词汇表中的每个唯一词 $w$ 学习一个单一向量嵌入。相比之下,在 BERT 这类掩码语言模型学习到的上下文嵌入中,同一个词 $w$ 每次出现在不同上下文中,都会由不同的向量表示。第 8 章中的因果语言模型也使用上下文嵌入,但掩码语言模型产生的嵌入似乎特别适合作为表示。
9.1 双向 Transformer 编码器
我们先介绍 BERT 及其后继模型(如 RoBERTa(Liu et al., 2019)和 SpanBERT(Joshi et al., 2020))背后的双向 transformer 编码器。第 7 章介绍了从左到右语言模型的思想,它可用于问答或摘要等自回归上下文生成问题;第 8 章则说明了如何用因果(从左到右)transformer 实现语言模型。但这些模型从左到右的性质也是一种限制,因为有些任务在处理某个词元时,如果能够偷看未来词元,会很有用。序列标注任务尤其如此:我们希望给每个词元打上一个标签,例如第 9.5 节将介绍的命名实体标注任务,以及后续章节中出现的词性标注或句法分析任务。
这里介绍的双向编码器和因果模型很不一样。第 8 章中的因果模型是生成式模型,设计目标是方便地生成序列中的下一个词元。而双向编码器的重点,则是计算输入词元的上下文化表示。双向编码器使用自注意力,把输入嵌入序列 $(x_1,\ldots,x_n)$ 映射为同样长度的输出嵌入序列 $(h_1,\ldots,h_n)$;输出向量利用整个输入序列的信息进行了上下文化。这些输出嵌入是每个输入词元的上下文化表示,适用于一系列需要基于上下文中的词元进行分类或决策的应用。
还记得我们说过,第 8 章中的模型有时被称为 decoder-only,因为它们对应于第 12 章将介绍的编码器--解码器模型中的解码器部分。相比之下,本章中的掩码语言模型有时被称为 encoder-only,因为它们为每个输入词元产生一个编码,但通常不通过解码或采样来生成连续文本。这一点很重要:掩码语言模型不是用来生成文本的。它们通常用于解释性任务。
9.1.1 双向掩码模型的架构
先讨论整体架构。基于双向 transformer 的语言模型与前几章的因果 transformer 有两点不同。第一,注意力函数不是因果的;某个词元 $i$ 的注意力可以查看后续词元 $i+1$ 等。第二,训练方式略有不同,因为我们预测的是文本中间的内容,而不是末尾内容。本节讨论第一点,下一节讨论第二点。
图 9.1a 从第 8 章复现,展示了第 8 章从左到右方法中的信息流。每个词元位置上的注意力计算都基于先前(以及当前)输入词元,忽略了位于当前词元右侧、可能有用的信息。双向编码器通过允许注意力机制覆盖整个输入来克服这一限制,如图 9.1b 所示。
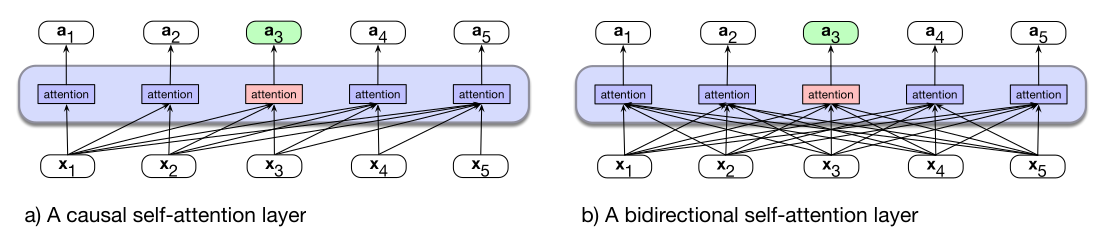
实现非常简单:只需去掉式 (8.34) 中引入的注意力掩码步骤。回忆第 8 章,对于因果 transformer,我们必须对 $QK^\top$ 矩阵做掩码,使注意力不能查看未来词元。下面把式 (8.34) 针对单个注意力头重写一遍:
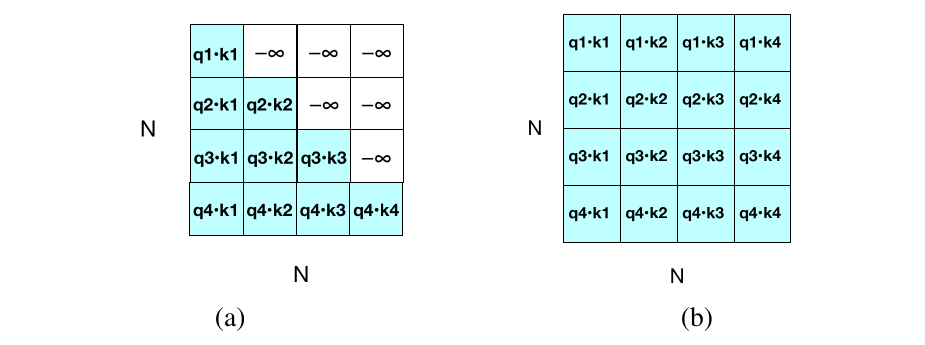
图 9.2 显示了 $QK^\top$ 的掩码版本和未掩码版本。对于双向注意力,我们使用图 9.2b 中的未掩码版本。因此,双向注意力的注意力计算与式 (9.1) 完全相同,只是去掉了掩码:
除此之外,注意力计算与第 8 章中看到的完全相同,transformer 块架构(前馈层、层归一化等)也相同。和第 8 章一样,输入也是一系列子词词元,通常由三种流行词元化算法之一计算得到:包括第 2 章已经见过的 BPE 算法,以及 WordPiece 算法和 SentencePiece Unigram LM 算法。因此,每个输入句子首先都必须被词元化,之后的所有处理都发生在子词词元而不是词上。正如本书第三部分将看到的,对于某些需要词这一概念的 NLP 任务(如句法分析),我们有时需要把子词映射回词。
更具体地说,最初的仅英语双向 transformer 编码器模型 BERT(Devlin et al., 2019)包含以下部分:
- 一个仅英语的子词词汇表,包含 30,000 个词元,由 WordPiece 算法生成(Schuster and Nakajima, 2012)。
- 输入上下文窗口 $N=512$ 个词元,模型维度 $d=768$。
- 因此模型输入 $X$ 的形状为 $[N\times d]=[512\times 768]$。
- $L=12$ 层 transformer 块,每层有 $A=12$ 个(双向)多头注意力层。
- 得到的模型约有 1 亿个参数。
在 100 种语言上训练的更大多语种 XLM-RoBERTa 模型包含:
- 一个多语种子词词汇表,包含 250,000 个词元,由 SentencePiece Unigram LM 算法生成(Kudo and Richardson, 2018b)。
- 输入上下文窗口 $N=512$ 个词元,模型维度 $d=1024$,因此模型输入 $X$ 的形状为 $[N\times d]=[512\times 1024]$。
- $L=24$ 层 transformer 块,每层有 $A=16$ 个多头注意力层。
- 得到的模型约有 5.5 亿个参数。
注意,从大型语言模型的尺度看,5.5 亿参数相对较小(Llama 3 有 4050 亿参数,大了三个数量级)。事实上,掩码语言模型往往比因果语言模型小得多。
9.2 训练双向编码器
第 8 章中,我们训练因果 transformer 语言模型的方法是让它们反复预测文本中的下一个词。但在注意力中去掉因果掩码之后,“猜下一个词” 的语言建模任务就变得平凡了,因为答案已经直接出现在上下文中,所以我们需要新的训练方案。模型不再尝试预测下一个词,而是学习执行填空任务,技术上称为 cloze 任务(Taylor, 1953)。为了理解这一点,我们回到第 3 章中的动机例子。与其预测下面例子中可能接着出现哪些词:
The water of Walden Pond is so beautifully
我们转而要求模型在给定句子其余部分的情况下预测缺失项:
The of Walden Pond is so beautifully ...
也就是说,给定一个缺失一个或多个元素的输入序列,学习任务是预测这些缺失元素。更精确地说,在训练期间,模型会被剥夺输入序列中的一个或多个词元,并且必须为每个缺失项在整个词汇表上生成概率分布。随后,我们使用模型每个预测的交叉熵损失来驱动学习过程。
这种方法可以推广为多种破坏训练输入、再要求模型恢复原始输入的方法。已有操作包括在训练文本中加入掩码、替换、重排、删除,以及插入额外内容。这类训练的一般名称叫去噪:我们以某种方式破坏输入(给输入加噪声,例如遮住一个词,或放入一个错误词),系统的目标是去除噪声。
9.2.1 掩蔽词
下面描述用于训练双向编码器的掩码语言建模(Masked Language Modeling, MLM)方法(Devlin et al., 2019)。和已经见过的语言模型训练方法一样,MLM 使用来自大语料库的无标注文本。在 MLM 训练中,模型看到训练语料中的一系列句子,其中有一定比例的词元(BERT 模型中为 15%)被随机选出,并由掩码程序进行操作。假设输入句子为 lunch was delicious,并且随机选中了第 3 个词元 delicious 进行操作:
- 80% 的时候:该词元被替换为名为
[MASK]的特殊词汇表词元,例如lunch was delicious$\rightarrow$lunch was [MASK]。 - 10% 的时候:该词元被另一个词元替换,这个词元根据词元一元概率从词汇表中随机采样,例如
lunch was delicious$\rightarrow$lunch was gasp。 - 10% 的时候:该词元保持不变,例如
lunch was delicious$\rightarrow$lunch was delicious。
随后我们训练模型去猜这些被操作词元的正确词元。为什么要有三种可能的操作?加入 [MASK] 词元会在预训练与下游微调或推理之间制造不匹配,因为当我们使用 MLM 模型执行下游任务时,并不会使用任何 [MASK] 词元。如果我们只是把词元替换为 [MASK],模型可能只在看到 [MASK] 时才预测词元;但我们希望模型总是尝试预测输入词元。
为了训练模型做出预测,原始输入序列先用子词模型词元化,然后采样要被操作的词元。所有输入词元的词嵌入从嵌入矩阵 $E$ 中取出,并与位置嵌入结合,形成 transformer 的输入;随后通过一叠双向 transformer 块,再通过语言建模头。MLM 训练目标是为每个被掩码的词元预测原始输入;这些预测的交叉熵损失驱动模型中所有参数的训练过程。也就是说,所有输入词元都参与自注意力过程,但只有被采样的词元用于学习。
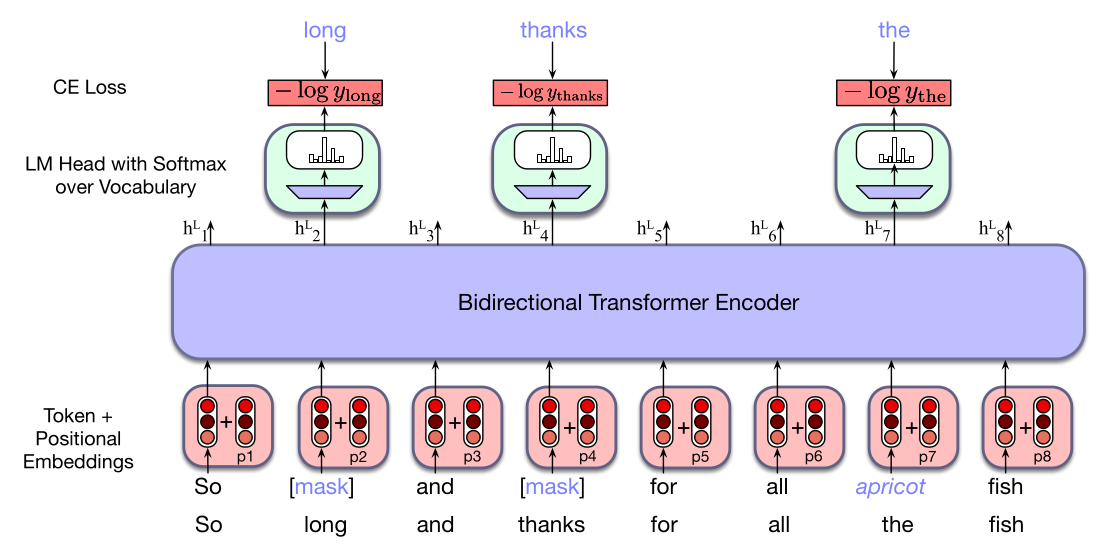
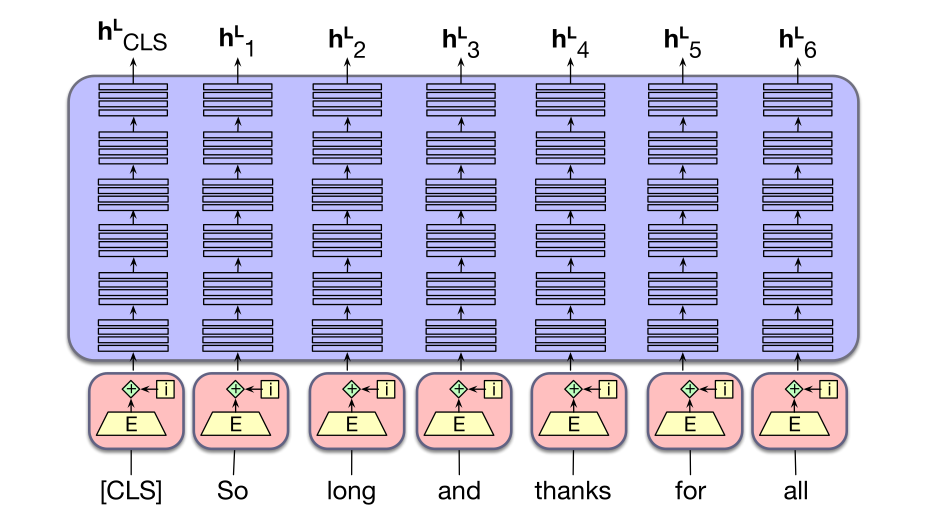
图 9.3 用一个简单例子说明了这种方法。这里,long、thanks 和 the 被从训练序列中采样出来;前两个被遮住,the 被随机采样词元 apricot 替换。得到的嵌入通过一叠双向 transformer 块。回忆第 8 章第 8.5 节,为了给每个被掩码词元生成词汇表上的概率分布,语言建模头会取最终 transformer 层 $L$ 中每个被掩码词元 $i$ 的输出向量 $h_i^L$,将它乘以反嵌入层 $E^\top$ 产生 logits $u$,再用 softmax 把 logits 转换为词汇表上的概率 $y$:
有了每个被掩码项的预测概率分布,我们就可以使用交叉熵来计算每个被掩码项的损失,也就是分配给实际被掩码词的负对数概率,如图 9.3 所示。更形式化地说,对于句子或批次中的输入词元向量 $x$,设被掩码词元集合为 $M$,把部分词元替换为掩码后的句子版本为 $x_{\mathrm{mask}}$,输出向量序列为 $h$。对于给定输入词元 $x_i$,例如图 9.3 中的词 long,损失是在给定 $x_{\mathrm{mask}}$(由单个输出向量 $h_i^L$ 概括)的条件下正确词 long 的概率:
形成权重更新基础的梯度,基于单个训练序列(或序列批次)中采样学习项的平均损失:
注意,只有 $M$ 中的词元参与学习;其他词不参与损失函数。因此在这个意义上,BERT 及其后继模型效率不高:训练数据中的输入样本只有 15% 真正用于训练权重。[注 1]
9.2.2 下一句预测
基于掩码的学习重点是从周围上下文预测词,目标是产生有效的词级表示。然而,有一类重要应用需要判断句子对之间的关系。这些任务包括复述检测(判断两个句子是否意义相近)、蕴含判断(判断两个句子的意义是否相互蕴含或矛盾)以及篇章连贯性判断(判断相邻两个句子是否构成连贯篇章)。
为了捕获这类应用所需的知识,BERT 家族中的一些模型包含第二个学习目标,称为下一句预测(Next Sentence Prediction, NSP)。在这个任务中,模型看到句子对,并被要求预测每个句子对是训练语料中真实相邻句子对,还是不相关句子对。在 BERT 中,50% 的训练句子对是正例;另外 50% 中,句子对的第二个句子从语料库其他位置随机选择。NSP 损失基于模型区分真实句子对与随机句子对的能力。
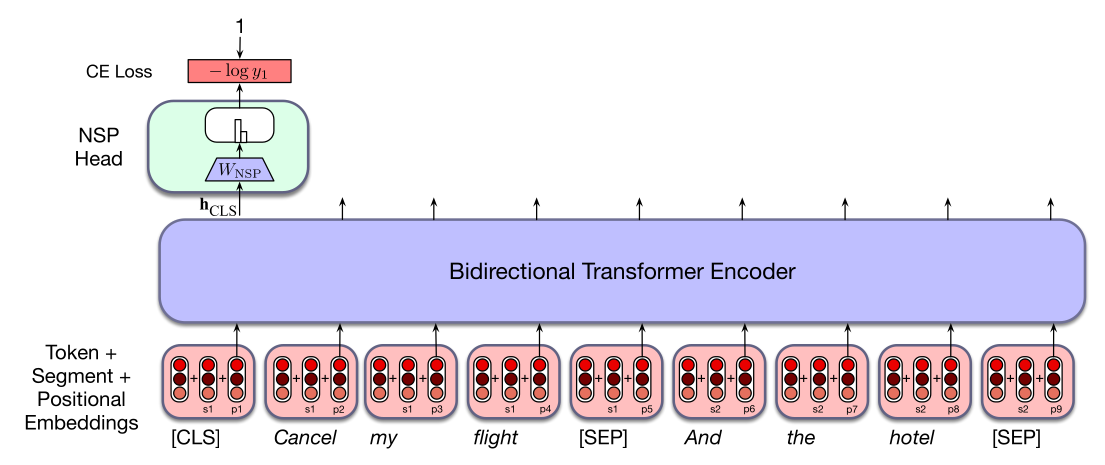
为了便于 NSP 训练,BERT 在输入表示中引入两个特殊词元(这些词元在微调中也会很有用)。输入经过子词模型词元化后,词元 [CLS] 被加到输入句子对最前面,词元 [SEP] 被放在两个句子之间,并放在第二个句子的最后一个词元之后。实际上还有两个特殊词元:“第一片段” 词元和 “第二片段” 词元。这些词元会在输入阶段加到词嵌入和位置嵌入上。也就是说,输入 $X$ 中每个词元实际上由三种嵌入相加而成:词、位置、第一/第二片段嵌入。
训练期间,与 [CLS] 词元关联的最终层输出向量 $h_{\mathrm{CLS}}^L$ 表示下一句预测。和 MLM 目标一样,我们加入一个特殊的头;此处是 NSP 头,它由一组学到的分类权重 $W_{\mathrm{NSP}}\in \mathbb{R}^{d\times 2}$ 构成,从原始 [CLS] 向量 $h_{\mathrm{CLS}}^L$ 产生二分类预测:
交叉熵用于计算呈现给模型的每个句子对的 NSP 损失。图 9.4 展示了整体 NSP 训练设置。在 BERT 中,NSP 损失与 MLM 训练目标结合使用,形成最终损失。
9.2.3 训练方案
BERT 和其他早期基于 transformer 的语言模型在约 33 亿词上训练,这些词来自英语维基百科以及名为 BooksCorpus 的图书文本语料(Zhu et al., 2015;该语料因知识产权原因已不再使用)。现代掩码语言模型现在会在大得多的网页文本数据集上训练;这些数据经过一定过滤,并由维基百科等更高质量数据增强,和第 8 章讨论因果大型语言模型时的做法相同。多语种模型同样使用网页文本和多语种维基百科。例如,XLM-R 模型在约 3000 亿个词元上训练,覆盖 100 种语言,数据来自 Common Crawl(https://commoncrawl.org/)。
为了训练原始 BERT 模型,文本片段对按照下一句预测的 50/50 方案从训练语料中选择。采样句子对时,它们的合计长度要小于 512 个词元的输入限制。随后,这些句子对中的词元用 MLM 方法遮蔽,并用 MLM 与 NSP 目标的联合损失作为最终损失。由于这个最终损失会反向传播穿过整个 transformer,每个 transformer 层上的嵌入都会学到有助于根据邻近词预测词的表示。由于 [CLS] 词元是 NSP 分类器的直接输入,它们学到的表示往往会包含关于整个序列的信息。模型大约需要对训练数据进行 40 次遍历(epoch)才能收敛。
有些模型(例如 RoBERTa)去掉了下一句预测目标,因此训练方案也略有改变。输入不再采样句子对,而是简单地使用一系列连续句子,仍然以特殊 [CLS] 词元开头。如果文档在达到 512 个词元之前结束,就加入一个额外的分隔词元,并把下一个文档中的句子打包进来,直到达到总计 512 个词元。通常会使用大批量,规模在 8K 到 32K 个词元之间。
多语种模型还必须做一个额外决策:用什么数据来构建词汇表?回忆一下,所有语言模型都使用子词词元化(BPE 和 SentencePiece Unigram LM 是最常见的两种算法)。鉴于有些语言比其他语言更容易获得大量文本,应该用哪些文本来学习这种多语种词元化?一种选项是从训练数据(也许是 Common Crawl 的网页文本)中随机采样句子,构造这个词汇学习数据集。这样我们会从英语等网络表示丰富的语言中选择大量句子,词元就会偏向罕见英语词元,而不是为数据较少语言中的高频词创建词元。因此,常见做法是把训练数据划分为 $N$ 种不同语言的子语料,计算每种语言 $i$ 的句子数量 $n_i$,并重新调整这些概率,从而提高低资源语言被采样的概率(Lample and Conneau, 2019)。从 $N$ 种语言中选择句子的新的概率为 $\{q_i\}_{i=1\ldots N}$,其中每种语言的先验频率为 $n_i$:
回忆第 5 章式 (5.19),$\alpha$ 值介于 0 和 1 之间时,会给较低概率样本更高权重。Conneau et al. (2020) 表明,$\alpha=0.3$ 能很好地让罕见语言更多地纳入词元化学习中,从而整体提升多语种表现。
这个预训练过程的结果包括学到的词嵌入,以及双向编码器的所有参数;这些参数用于为新输入产生上下文嵌入。
对于许多用途,预训练多语种模型比单语模型更实用,因为它避免了构建许多(上百个)独立单语模型的需求。而且,多语种模型可以利用训练数据中某个资源更丰富的相近语言的语言信息,提升低资源语言上的性能。尽管如此,当语言数量变得非常大时,多语种模型会表现出所谓多语性诅咒(Conneau et al., 2020):与在较少语言上训练的模型相比,每种语言上的性能都会下降。多语种模型的另一个问题是它们 “有口音”:高资源语言(常常是英语)的语法结构会渗入低资源语言;训练中大量英语使模型对低资源语言的表示变得略微更像英语(Papadimitriou et al., 2023)。
9.3 上下文嵌入
给定一个预训练语言模型和一个新的输入句子,我们可以把模型输出序列看成输入中每个词元的上下文嵌入。这些上下文嵌入是向量,表示上下文中某个词元意义的某个方面,可用于任何需要词元或词含义的任务。更形式化地说,给定输入词元序列 $x_1,\ldots,x_n$,我们可以用模型最终层 $L$ 的输出向量 $h_i^L$ 作为词元 $x_i$ 在句子 $x_1,\ldots,x_n$ 上下文中的意义表示。也可以不只使用模型最终层的向量 $h_i^L$,而是常常通过平均模型最后四层中每层的输出词元 $h_i$ 来计算 $x_i$ 的表示,即 $h_i^L$、$h_i^{L-1}$、$h_i^{L-2}$ 和 $h_i^{L-3}$。
正如第 5 章中我们使用 word2vec 等静态嵌入来表示词义一样,我们也可以把上下文嵌入用作上下文中词义的表示,用于任何可能需要词义模型的任务。静态嵌入表示的是词类型(词汇表条目)的意义,而上下文嵌入表示的是词实例的意义:某个特定词类型在某个特定上下文中的实例。因此,word2vec 对每个词类型只有一个向量,而上下文嵌入为该词类型在句子上下文中的每个实例提供一个向量。上下文嵌入由此可用于测量两个上下文中词的语义相似性等任务,也适用于需要词义模型的语言学任务。
9.3.1 上下文嵌入与词义
词是有歧义的:同一个词可以用来表示不同事物。第 5 章中我们看到,词 “mouse” 可以表示 (1) 小型啮齿动物,或 (2) 控制光标的手持设备。词 “bank” 可以表示 (1) 金融机构,或 (2) 倾斜的堤岸。我们说 “mouse” 或 “bank” 是多义的(polysemous;源自希腊语 “许多意义”,poly- 表示 “许多”,sema 表示 “符号、标记”)。[注 2]
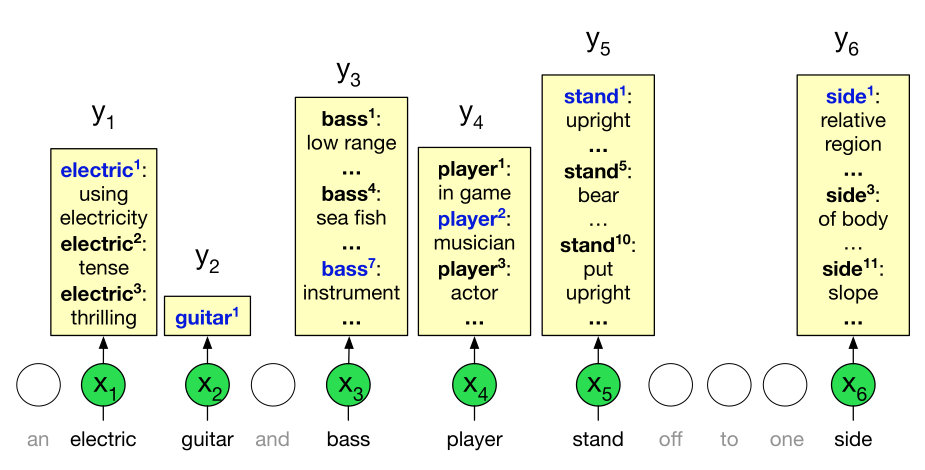
义项(sense,或 word sense)是词义某个方面的离散表示。我们可以用上标表示每个义项:$bank^1$ 和 $bank^2$,$mouse^1$ 和 $mouse^2$。这些义项可以在 WordNet(Fellbaum, 1998)这样的在线同义词词典中找到;WordNet 为许多语言提供了列出大量词义项的数据集。在上下文中,很容易看出不同意义:
$mouse^1$:……1968 年控制计算机系统的一个 mouse。
$mouse^2$:……像 mouse 一样安静的动物。
$bank^1$:……一家 bank 可以在托管账户中持有投资……
$bank^2$:……随着东 bank 的农业蓬勃发展,这条河……
上下文消解了上面 mouse 和 bank 义项的这一事实,也可以用几何方式可视化。图 9.6 显示了英语和德语中词 die 的许多 BERT 嵌入实例的二维投影。图中每个点表示 die 在一个输入句子中的用法。我们可以清楚看到 BERT 嵌入空间中至少有两个英语 die 的不同义项(骰子 dice 的单数,以及动词 “死亡”),还有德语冠词。
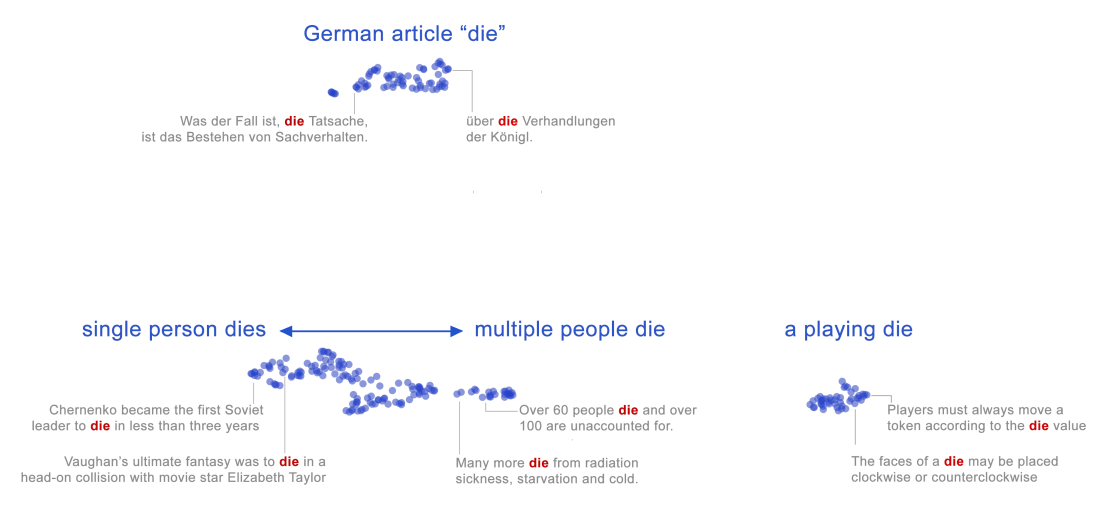
因此,尽管 WordNet 这类词典给出离散义项列表,嵌入(无论是静态还是上下文嵌入)提供的是意义的连续高维模型;这个模型虽然可以被聚类,但并不会完全划分成离散义项。
词义消歧
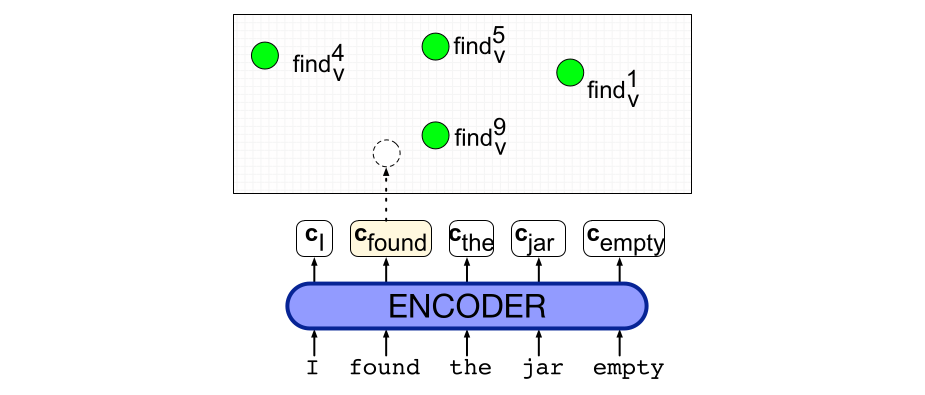
词义消歧(word sense disambiguation,WSD)是为一个词选择正确义项的任务。WSD 算法以一个上下文中的词和一个固定的潜在词义项清单(例如 WordNet 中的义项)作为输入,并输出上下文中的正确词义。图 9.7 勾勒了这个任务。
WSD 可以作为人文学科和社会科学文本分析的有用分析工具,词义也能在词表示的模型可解释性中发挥作用。词义还具有有趣的分布特性。例如,一个词在一段篇章中通常大致使用同一个义项,这一观察称为一篇章一义项规则(Gale et al., 1992a)。
表现最好的 WSD 算法,是使用上下文词嵌入的简单 1-近邻算法,源自 Melamud et al. (2016) 和 Peters et al. (2018)。训练时,我们把某个带义项标签的数据集(如多种语言中的 SemCore 或 SenseEval 数据集)中的每个句子送入任意上下文嵌入模型(例如 BERT),为每个带标签词元得到一个上下文嵌入。(计算词元 $i$ 的上下文嵌入 $v_i$ 有多种方式;对于 BERT,常见做法是把最后四层中 $i$ 的向量表示相加,以汇聚多层信息。)随后,对于语料中任意词的每个义项 $s$,对该义项的 $n$ 个词元,将它们的 $n$ 个上下文表示 $v_i$ 取平均,产生义项 $s$ 的上下文义项嵌入 $v_s$:
测试时,给定上下文中某个目标词 $t$ 的词元,我们计算它的上下文嵌入 $t$,然后从训练集中选择最近邻义项,也就是其义项嵌入与 $t$ 的余弦最高的义项:
图 9.8 展示了这个模型。
9.3.2 上下文嵌入与词相似性
第 5 章介绍过一个思想:可以通过词在几何上有多接近来度量两个词的相似性,使用余弦作为相似函数。图 9.6 中意义聚类也几何地展示了意义相似性的思想:某个上下文中具有特定义项的词表示,更接近同一词的同一义项的其他实例。因此,我们常用两个上下文中两个词实例(或同一个词在两个不同上下文中的两个实例)的上下文嵌入之间的余弦,来衡量它们的相似性。
通常,在计算余弦之前需要对嵌入做一些变换。这是因为上下文嵌入(无论来自掩码语言模型还是自回归模型)具有一个性质:所有词的向量都极其相似。如果观察 BERT 或其他模型最终层的嵌入,任意两个随机词实例的嵌入都会有非常高的余弦,可能非常接近 1,这意味着所有词向量都倾向于指向同一方向。一个系统中的向量都倾向于指向同一方向,这种性质称为各向异性。Ethayarajh (2019) 将模型的各向异性定义为语料中任意一对词的期望余弦相似度。“isotropy” 的意思是在各个方向上均匀,因此在各向同性模型中,向量集合应当指向所有方向,一对随机嵌入之间的期望余弦应当为零。Timkey and van Schijndel (2021) 表明,各向异性的一个原因是,余弦度量被上下文嵌入中少数几个维度主导;这些维度的取值与其他维度很不相同,它们是具有很大幅度和很高方差的离群维度。
Timkey and van Schijndel (2021) 表明,我们可以通过对向量进行标准化(z-score)让嵌入更各向同性,也就是减去均值并除以方差。给定某个语料中所有嵌入的集合 $C$,每个嵌入维度为 $d$(即 $x\in \mathbb{R}^d$),均值向量 $\mu\in\mathbb{R}^d$ 为:
每个维度的标准差 $\sigma\in\mathbb{R}^d$ 为:
随后,每个词向量 $x$ 被替换为标准化版本 $z$:
标准化无法解决余弦的一个问题:对于非常高频的词,余弦往往会低估人类对词义相似性的判断(Zhou et al., 2022)。
9.4 用于分类的微调
预训练语言模型的力量在于,它们能从大量文本中抽取概括;这些概括对众多下游应用有用。要用这些概括来解决下游任务,有两种实用方式。最常见的方式是用自然语言提示模型,让模型处于能按上下文生成我们想要内容的状态。
本节探索另一种把预训练语言模型用于下游应用的方法:第 7 章微调范式的一个版本。在掩码语言模型使用的这种微调中,我们把特定于应用的电路(常称为特殊头)加到预训练模型顶部,以预训练模型的输出作为输入。微调过程包括使用关于该应用的带标签数据来训练这些额外的应用特定参数。通常,这种训练会冻结预训练语言模型参数,或者只对它们做极小调整。
下面几节介绍最常见应用类型的微调方法:序列分类、句子对分类和序列标注。
9.4.1 序列分类
序列分类任务是用单个标签给整个文本序列分类。这组任务通常称为文本分类,例如情感分析或垃圾邮件检测(附录 K),我们把文本分成两个或三个类别(如正面或负面);也包括类别数量很多的分类任务,例如文档级主题分类。
对于序列分类,我们用单个向量表示整个待分类输入。表示一个序列有多种方式。一种方式是取序列中每个词元最后输出向量的和或均值。对于 BERT,我们改为在词汇表中加入一个新的唯一词元 [CLS],并在预训练和编码期间把它前置到所有输入序列开头。模型最终层中 [CLS] 输入的输出向量表示整个输入序列,并作为分类器头的输入;分类器头可以是逻辑回归或神经网络分类器,用来做出相关决策。
作为例子,我们回到情感分类问题。为这个应用微调分类器,需要学习一组权重 $W_C$,把 [CLS] 词元的输出向量 $h_{\mathrm{CLS}}^L$ 映射到可能情感类别上的一组分数。假设任务是三分类情感分类(正面、负面、中性),模型维度为 $d$,则 $W_C$ 的大小为 $[d\times 3]$。为了分类一个文档,我们把输入文本传入预训练语言模型,生成 $h_{\mathrm{CLS}}^L$,将其乘以 $W_C$,再让得到的向量通过 softmax:
微调 $W_C$ 的值需要有监督训练数据,其中输入序列带有相应情感类别标签。训练按通常方式进行:softmax 输出与正确答案之间的交叉熵损失驱动学习,从而产生 $W_C$。
这个损失不仅可用于学习分类器权重,也可用于更新预训练语言模型本身的权重。实践中,通常只需对语言模型参数进行很小改动就能获得合理的分类性能,常常只限于更新 transformer 的最后几层。图 9.9 展示了这种序列分类总体方法。
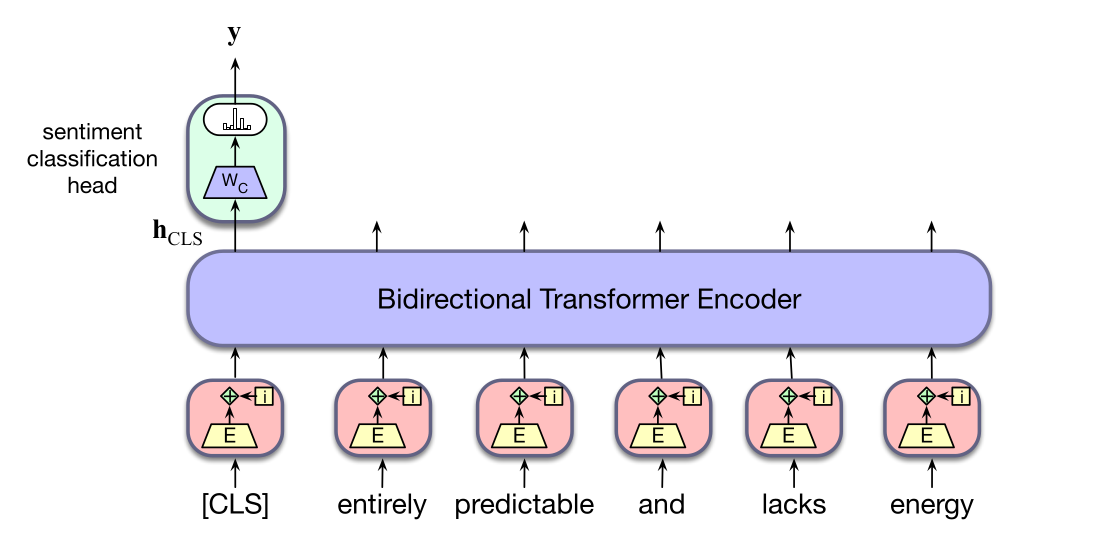
[CLS] 词元的输出向量作为简单分类器的输入。9.4.2 序列对分类
如第 9.2.2 节所述,有一类重要问题涉及输入序列对的分类。属于这一类的实际应用包括复述检测(两个句子是否互为复述?)、逻辑蕴含(句子 A 是否在逻辑上蕴含句子 B?)以及篇章连贯性(句子 B 作为句子 A 的后续有多连贯?)。
针对这些任务之一微调应用,过程与使用 NSP 目标进行预训练时相同。微调期间,来自有监督微调集的带标签句子对被呈现给模型,并通过模型所有层,产生每个输入词元的 $h$ 输出。和序列分类一样,与前置 [CLS] 词元相关联的输出向量表示模型对输入句子对的看法。和 NSP 训练一样,两个输入由 [SEP] 词元分隔。为了执行分类,[CLS] 向量乘以一组学到的分类权重,再通过 softmax 生成标签预测;这些预测随后用于更新权重。
举例来说,考虑使用 Multi-Genre Natural Language Inference(MultiNLI)数据集(Williams et al., 2018)的蕴含分类任务。在自然语言推理(natural language inference,NLI)任务中,也称为识别文本蕴含,模型会看到一对句子,并必须分类它们意义之间的关系。例如在 MultiNLI 语料中,句子对被赋予三种标签之一:entails(蕴含)、contradicts(矛盾)和 neutral(中性)。这些标签描述第一个句子(前提)与第二个句子(假设)之间的意义关系。以下是语料中每个类别的代表性例子:
- Neutral(中性)
a: Jon walked back to the town to the smithy.
b: Jon traveled back to his hometown. - Contradicts(矛盾)
a: Tourist Information offices can be very helpful.
b: Tourist Information offices are never of any help. - Entails(蕴含)
a: I'm confused.
b: Not all of it is very clear to me.
contradicts 关系表示前提与假设矛盾;entails 表示前提蕴含假设;neutral 表示二者不必然为真。这些标签的意义比严格逻辑蕴含或矛盾更宽松,表示一个典型人类读者最可能以这种方式解释句子含义。
为了给 MultiNLI 任务微调分类器,我们按上述方式把前提/假设对传入双向编码器,并使用 [CLS] 词元的输出向量作为分类头的输入。和普通序列分类一样,这个头为三分类器提供输入,三分类器可以在 MultiNLI 训练语料上训练。
9.5 用于序列标注的微调:命名实体识别
在序列标注中,网络的任务是为序列中的每个词元分配一个标签,标签从一个很小的固定标签集合中选择。最常见的序列标注任务之一是命名实体识别。
9.5.1 命名实体
命名实体粗略地说,是任何可以用专名指称的东西:人、地点、组织。命名实体识别(named entity recognition,NER)的任务是找到构成专名的文本片段,并标注实体类型。最常见的四种实体标签是 PER(人)、LOC(地点)、ORG(组织)和 GPE(地缘政治实体)。不过,术语命名实体通常也扩展到包含并非严格实体的东西,包括日期和时间等时间表达式,甚至价格等数值表达式。下面是一个 NER 标注器的输出示例:
由于燃油价格高企,[ORG United Airlines] 于 [TIME Friday] 表示,它已经把一些同时由低成本航空公司服务的城市航线往返票价提高了 [MONEY $6]。[ORG American Airlines] 是 [ORG AMR Corp.] 的一个部门,发言人 [PER Tim Wagner] 表示该公司立即跟进了这一举措。[ORG United] 是 [ORG UAL Corp.] 的一个部门,该公司表示涨价已于 [TIME Thursday] 生效,并适用于它与折扣航空公司竞争的大多数航线,例如从 [LOC Chicago] 到 [LOC Dallas],以及从 [LOC Denver] 到 [LOC San Francisco]。
这段文本包含 13 个命名实体提及,其中包括 5 个组织、4 个地点、2 个时间、1 个人和 1 个金额提及。图 9.10 展示了典型的通用命名实体类型。许多应用还需要使用更具体的实体类型,例如蛋白质、基因、商业产品或艺术作品。

命名实体识别是多种自然语言处理任务中的有用步骤,包括把文本链接到 Wikipedia 等结构化知识源中的信息,度量文本中对某个实体的情感或态度,甚至作为文本隐私匿名化的一部分。NER 任务之所以困难,是因为 NER 片段的分割有歧义:需要弄清哪些词元是实体,哪些不是,因为文本中的大多数词都不是命名实体。另一个困难来自类型歧义。提及 Washington 可以指一个人、一支运动队、一个城市或美国政府,如图 9.11 所示。

9.5.2 BIO 标注
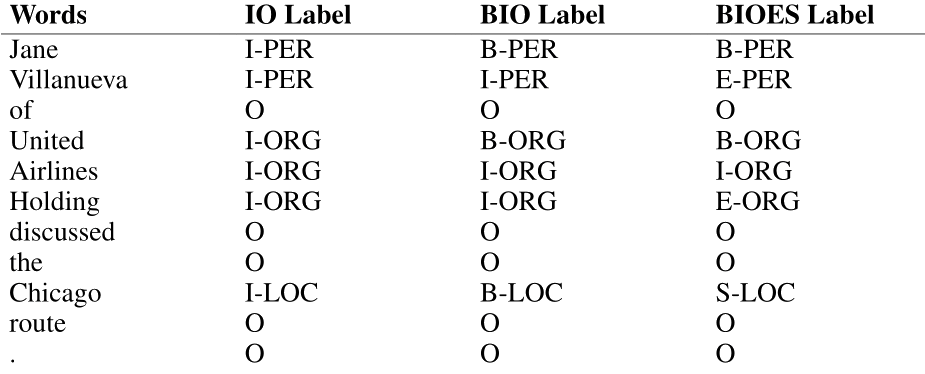
对于 NER 这样的片段识别问题,一种标准的序列标注方法是 BIO 标注(Ramshaw and Marcus, 1995)。这种方法通过同时捕获边界和命名实体类型的标签,使我们能够把 NER 当作逐词序列标注任务来处理。考虑下面的句子:
[PER Jane Villanueva] of [ORG United], a unit of [ORG United Airlines Holding], said the fare applies to the [LOC Chicago] route.
图 9.12 展示了同一片段的 BIO 标注,以及称为 IO 标注和 BIOES 标注的变体。在 BIO 标注中,任何感兴趣片段的开头词元标为 B;片段内部的词元标为 I;任何感兴趣片段之外的词元标为 O。虽然 O 标签只有一个,但每个命名实体类别都会有不同的 B 和 I 标签。因此,标签数量为 $2n+1$,其中 $n$ 是实体类型数量。BIO 标注可以表示与括号表示法完全相同的信息,但它的优点是可以用和词性标注相同的简单序列建模方式来表示任务:为每个输入词 $x_i$ 分配单个标签 $y_i$。
图中还展示了两种标注方案变体:IO 标注去掉 B 标签,因此丢失一些信息;BIOES 标注加入片段结束标签 E,以及只由一个词组成的片段标签 S。
9.5.3 序列标注
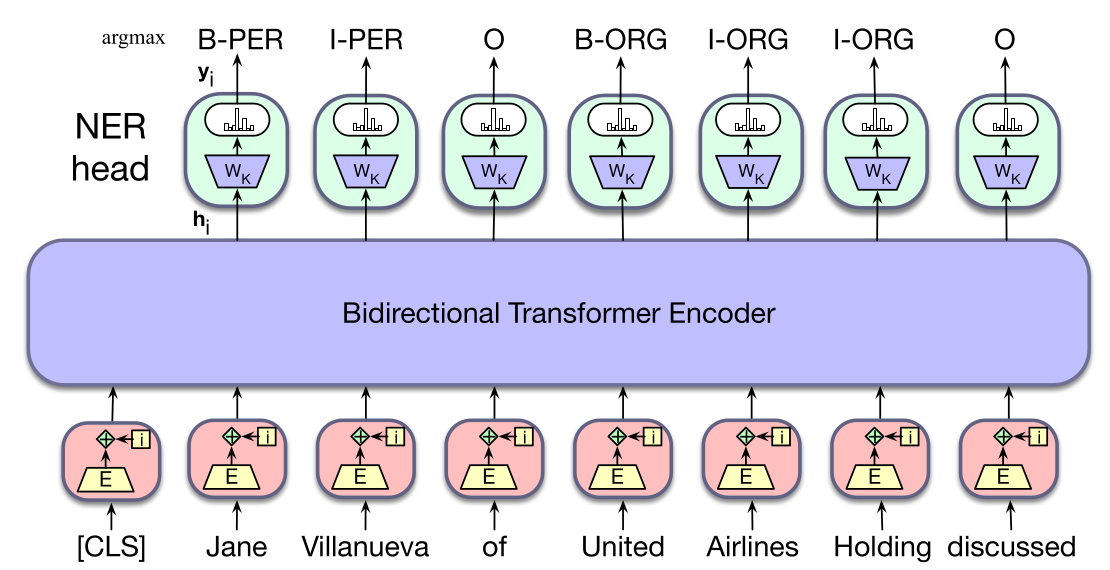
在序列标注中,我们把每个输入词元对应的最终输出向量传给一个分类器,该分类器产生可能标签集合上的 softmax 分布。对于单个前馈层分类器,要学习的权重集合为 $W_K$,大小为 $[d\times k]$,其中 $k$ 是该任务可能标签的数量。可以使用贪心方法生成最终输出标签序列:把每个词元的 argmax 标签当作可能答案。图 9.13 展示了这种方法的一个例子,其中 $y_i$ 是标签上的概率向量,$k$ 索引标签。
另一种做法是,把 softmax 为每个输入词元提供的标签分布传入条件随机场(CRF)层;CRF 层能够把全局标签级转移纳入考虑(见第 17 章关于 CRF 的内容)。
词元化与 NER
注意,NER 的有监督训练数据通常采用 BIO 标签形式,并与按词级分割的文本相关联。例如,下面包含两个命名实体的句子:
[LOC Mt. Sanitas] is in [LOC Sunshine Canyon].
会有下面这一组逐词 BIO 标签:
(9.14) Mt. Sanitas is in Sunshine Canyon .
B-LOC I-LOC O O B-LOC I-LOC O
不幸的是,这个句子的 WordPiece 词元序列无法与标注中的 BIO 标签直接对齐:
'Mt','.','San','##itas','is','in','Sunshine','Canyon','.'
为了解决这种不对齐,我们需要一种方法,在训练期间把 BIO 标签分配给子词词元,并在解码期间以对应方式从子词恢复词级标签。训练时,可以简单地把每个词关联的金标准标签分配给从该词派生出的所有子词词元。
解码时,最简单的方法是使用某个词第一个子词词元关联的 argmax BIO 标签。因此,在我们的例子中,分配给 “Mt” 的 BIO 标签会分配给 “Mt.”,分配给 “San” 的标签会分配给 “Sanitas”,实际上忽略分配给 “.” 和 “##itas” 的标签中的信息。更复杂的方法会组合各个子词上的标签概率分布,试图找到最优词级标签。
9.5.4 评估命名实体识别
命名实体识别器通过召回率、精确率和 $F_1$ 度量进行评估。回忆一下,召回率是正确标注响应数量与本应被标注总数之比;精确率是正确标注响应数量与被标注总数之比;$F_1$ 度量是二者的调和平均。
为了判断两个 NER 系统的 $F_1$ 分数差异是否显著,我们使用配对 bootstrap 检验,或类似的随机化检验(第 4.11 节)。
对于命名实体标注,响应单位是实体而不是词。因此,在图 9.12 的例子中,两个实体 Jane Villanueva 和 United Airlines Holding,以及非实体 discussed,都各自算作一个响应。
命名实体标注包含分割成分,而文本分类或词性标注等任务没有这一点,这给评估带来一些问题。例如,如果系统把 Jane 标为人名,但没有把 Jane Villanueva 标为人名,就会造成两个错误:一个针对 O 的假阳性,以及一个针对 I-PER 的假阴性。此外,用实体作为响应单位、但用词作为训练单位,意味着训练条件和测试条件之间存在不匹配。
9.6 小结
本章介绍了双向编码器和掩码语言模型。下面总结本章覆盖的要点:
- 双向编码器可以使用整个输入上下文,生成输入嵌入的上下文化表示。
- 基于双向编码器的预训练语言模型可以用掩码语言模型目标学习:训练模型根据输入猜测缺失信息。
- 在特定词元列中,每个 transformer 块或组件的向量输出都是一个上下文嵌入,表示上下文中该词元意义的某个方面。
- 词义是词的某个意义方面的离散表示。上下文嵌入提供了连续的高维意义模型,比完全离散的义项更丰富。
- 上下文嵌入之间的余弦可以作为一种方式,用来建模上下文中两个词的相似性,不过需要先对嵌入做一些变换。
- 预训练语言模型可以通过在预训练模型输出顶部加入轻量分类器层,针对具体应用进行微调。
- 这些应用包括情感分析等序列分类任务、自然语言推理等序列对分类任务,以及命名实体识别等序列标注任务。
历史注记
历史注记待补。